溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“怎么用Java實現網站聚合工具”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“怎么用Java實現網站聚合工具”文章能幫助大家解決問題。
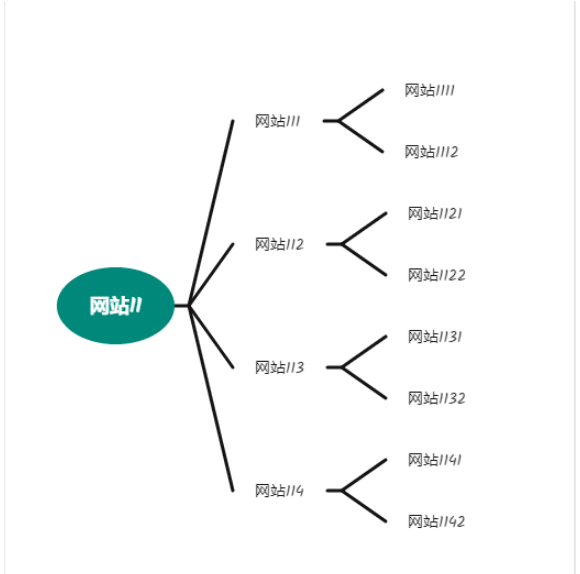
可以把互聯網上的網站看做一張巨大的連通圖,不同的網站處于不同的連通塊中,然后以廣度優先算法遍歷這個連通塊,就能找到所有的網站域名,利用廣度優先算法遍歷該連通塊的結構可以抽象為:
然后,我們對該網站的返回內容進行分詞,剔除無意義的詞語和標點符號,就得出該網站首頁的關鍵詞排序,我們可以取詞頻在(10,50)區間范圍內的為關鍵詞,然后將這些關鍵詞作為網站主題,把網站的信息放到以該詞為名字的markdown文件中備用。
同理,我們也對該網站返回內容的title部分進行分詞,因為title是網站開發者對網站功能的濃縮,也比較重要,同理,也將這些關鍵詞作為網站主題,把網站的信息放到以該詞為名字的markdown文件中備用。
最后,我們只需要從這些文件中人工做篩選,或者以這些數據放到elasticsearch中,做關鍵詞搜索引擎即可。以達到想用的時候隨時去拿的目的。
不過,當你遍歷連通塊沒有收斂時,得到的數據還是很少的,某些分類往往只有一兩個網站。
頁面下載我使用的是httpClient,前期考慮用playwrite來做,但是兩者性能差距太大,后者效率太低了,所以舍棄了部分準確性(即web2.0技術的網站,前者無法拿到數據),所以準確的說我實現的僅僅是web1.0的網站分類搜索引擎的頁面下載功能。
public SendReq.ResBody doRequest(String url, String method, Map<String, Object> params) {
String urlTrue = url;
SendReq.ResBody resBody = SendReq.sendReq(urlTrue, method, params, defaultHeaders());
return resBody;
}其中,SendReq是我封裝的一個httpClient的類,只是實現了一個頁面下載的功能,你可以替換為RestTemplate或者別的發起http(s)請求的方法。
因為是連通塊遍歷,那么定義的連通網站就是該網站首頁里面所有的外鏈的域名所在的站,所以我們需要提取鏈接,直接使用正則表達式提取即可。
public static List<String> getUrls(String htmlText) {
Pattern pattern = Pattern.compile("(http|https):\\/\\/[A-Za-z0-9_\\-\\+.:?&@=\\/%#,;]*");
Matcher matcher = pattern.matcher(htmlText);
Set<String> ans = new HashSet<>();
while (matcher.find()){
ans.add(DomainUtils.getDomainWithCompleteDomain(matcher.group()));
}
return new ArrayList<>(ans);
}title是網站開發者對網站功能的濃縮,所以很有必要將title解析出來做進一步處理
public static String getTitle(String htmlText){
Pattern pattern = Pattern.compile("(?<=title\\>).*(?=</title)");
Matcher matcher = pattern.matcher(htmlText);
Set<String> ans = new HashSet<>();
while (matcher.find()){
return matcher.group();
}
return "";
}因為后續步驟需要對網站返回值進行分詞,所以需要對頁面中的標簽和代碼進行去除。
public static String getContent(String html) {
String ans = "";
try {
html = StringEscapeUtils.unescapeHtml4(html);
html = delHTMLTag(html);
html = htmlTextFormat(html);
return html;
} catch (Exception e) {
e.printStackTrace();
}
return ans;
}
public static String delHTMLTag(String htmlStr) {
String regEx_script = "<script[^>]*?>[\\s\\S]*?<\\/script>"; //定義script的正則表達式
String regEx_style = "<style[^>]*?>[\\s\\S]*?<\\/style>"; //定義style的正則表達式
String regEx_html = "<[^>]+>"; //定義HTML標簽的正則表達式
Pattern p_script = Pattern.compile(regEx_script, Pattern.CASE_INSENSITIVE);
Matcher m_script = p_script.matcher(htmlStr);
htmlStr = m_script.replaceAll(""); //過濾script標簽
Pattern p_style = Pattern.compile(regEx_style, Pattern.CASE_INSENSITIVE);
Matcher m_style = p_style.matcher(htmlStr);
htmlStr = m_style.replaceAll(""); //過濾style標簽
Pattern p_html = Pattern.compile(regEx_html, Pattern.CASE_INSENSITIVE);
Matcher m_html = p_html.matcher(htmlStr);
htmlStr = m_html.replaceAll(""); //過濾html標簽
return htmlStr.trim();
}分詞算法使用之前講NLP入門的文章里面提到的hanlp即可
private static Pattern ignoreWords = Pattern.compile("[,.0-9_\\- ,、:。;;\\]\\[\\/!()【】*?“”()+:|\"%~<>——]+");
public static Set<Word> separateWordAndReturnUnit(String text) {
Segment segment = HanLP.newSegment().enableOffset(true);
Set<Word> detectorUnits = new HashSet<>();
Map<Integer, Word> detectorUnitMap = new HashMap<>();
List<Term> terms = segment.seg(text);
for (Term term : terms) {
Matcher matcher = ignoreWords.matcher(term.word);
if (!matcher.find() && term.word.length() > 1 && !term.word.contains("?")) {
Integer hashCode = term.word.hashCode();
Word detectorUnit = detectorUnitMap.get(hashCode);
if (Objects.nonNull(detectorUnit)) {
detectorUnit.setCount(detectorUnit.getCount() + 1);
} else {
detectorUnit = new Word();
detectorUnit.setWord(term.word.trim());
detectorUnit.setCount(1);
detectorUnitMap.put(hashCode, detectorUnit);
detectorUnits.add(detectorUnit);
}
}
}
return detectorUnits;
}這里為了去掉詞頻過多的詞的干擾,所以只取詞頻小于50的詞的前十
public static List<String> print2List(List<Word> tmp,int cnt){
PriorityQueue<Word> words = new PriorityQueue<>();
List<String> ans = new ArrayList<>();
for (Word word : tmp) {
words.add(word);
}
int count = 0;
while (!words.isEmpty()) {
Word word = words.poll();
if (word.getCount()<50){
ans.add(word.getWord() + " " + word.getCount());
count ++;
if (count >= cnt){
break;
}
}
}
return ans;
}方法就是放到優先隊列中一個一個取出來,優先隊列是使用大頂堆實現的,所以取出來一定是有序的。如果想了解大頂堆的朋友,可以看我前面的文章。
值得注意的是,優先隊列中放入的類必須是可排序的,所以,這里的Word也是可排序的,簡化的代碼如下:
public class Word implements Comparable{
private String word;
private Integer count = 0;
... ...
@Override
public int compareTo(Object o) {
if (this.count >= ((Word)o).count){
return -1;
}else {
return 1;
}
}
}好了,現在準備工作已經做好了。下面開始實現程序邏輯部分。
利用廣度優先遍歷網站連通塊,之前的文章有專門講利用隊列寫廣度優先遍歷。現在就使用該方法。
public void doTask() {
String root = "http://" + this.domain + "/";
Queue<String> urls = new LinkedList<>();
urls.add(root);
Set<String> tmpDomains = new HashSet<>();
tmpDomains.add(DomainUtils.getDomainWithCompleteDomain(root));
while (!urls.isEmpty()) {
String url = urls.poll();
SendReq.ResBody html = doRequest(url, "GET", new HashMap<>());
System.out.println("當前的請求為 " + url + " 隊列的大小為 " + urls.size() + " 結果為" + html.getCode());
if (html.getCode().equals(0)) {
ignoreSet.add(DomainUtils.getDomainWithCompleteDomain(url));
try {
GenerateFile.createFile2("moneyframework/generate/ignore", "demo.txt", ignoreSet.toString());
} catch (IOException e) {
e.printStackTrace();
}
continue;
}
OnePage onePage = new OnePage();
onePage.setUrl(url);
onePage.setDomain(DomainUtils.getDomainWithCompleteDomain(url));
onePage.setCode(html.getCode());
String title = HtmlUtil.getTitle(html.getResponce()).trim();
if (!StringUtils.hasText(title) || title.length() > 100 || title.contains("?")) continue;
onePage.setTitle(title);
String content = HtmlUtil.getContent(html.getResponce());
Set<Word> words = Nlp.separateWordAndReturnUnit(content);
List<String> wordStr = Nlp.print2List(new ArrayList<>(words), 10);
handleWord(wordStr, DomainUtils.getDomainWithCompleteDomain(url), title);
onePage.setContent(wordStr.toString());
if (html.getCode().equals(200)) {
List<String> domains = HtmlUtil.getUrls(html.getResponce());
for (String domain : domains) {
int flag = 0;
for (String i : ignoreSet) {
if (domain.endsWith(i)) {
flag = 1;
break;
}
}
if (flag == 1) continue;
if (StringUtils.hasText(domain.trim())) {
if (!tmpDomains.contains(domain)) {
tmpDomains.add(domain);
urls.add("http://" + domain + "/");
}
}
}
}
}
}@Service
public class Task {
@PostConstruct
public void init(){
new Thread(new Runnable() {
@Override
public void run() {
while (true){
try {
HttpClientCrawl clientCrawl = new HttpClientCrawl("http://www.mengwa.store/");
clientCrawl.doTask();
}catch (Exception e){
e.printStackTrace();
}
}
}
}).start();
}
}關于“怎么用Java實現網站聚合工具”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





