溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Kafka怎么讀寫副本消息,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
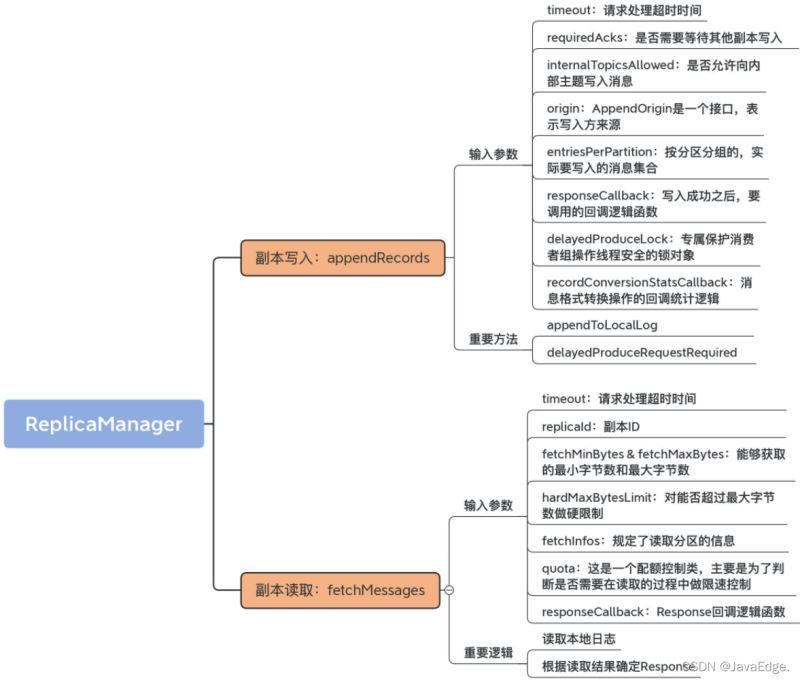
向副本底層日志寫入消息的邏輯就實現在ReplicaManager#appendRecords。
Kafka需副本寫入的場景:
生產者向Leader副本寫入消息
Follower副本拉取消息后寫入副本
僅該場景調用Partition對象的方法,其余3個都是調用appendRecords完成
消費者組寫入組信息
事務管理器寫入事務信息(包括事務標記、事務元數據等)
appendRecords方法將給定的一組分區的消息寫入對應Leader副本,并根據PRODUCE請求中acks的設置,有選擇地等待其他副本寫入完成。然后,調用指定回調邏輯。
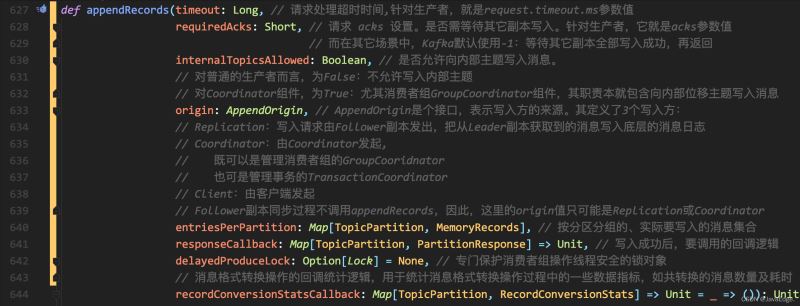
appendRecords向副本日志寫入消息的過程:


執行流程
可見,appendRecords:
實現消息寫入的方法是appendToLocalLog
判斷是否需要等待其他副本寫入的方法delayedProduceRequestRequired
appendToLocalLog寫入副本本地日志
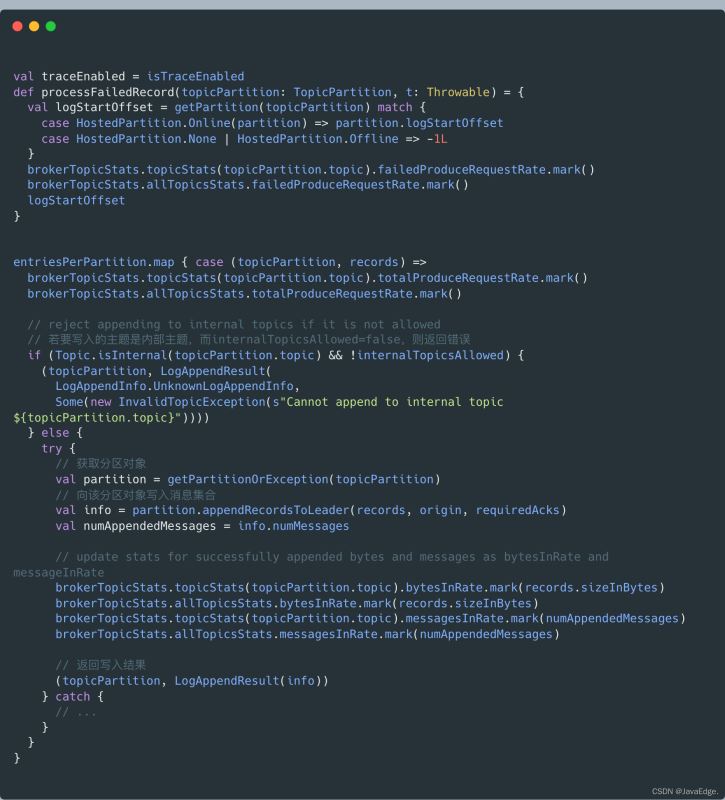
利用Partition#appendRecordsToLeader寫入消息集合,就是利用appendAsLeader方法寫入本地日志的。
delayedProduceRequestRequired
判斷消息集合被寫入到日志之后,是否需要等待其它副本也寫入成功:
private def delayedProduceRequestRequired(
requiredAcks: Short,
entriesPerPartition: Map[TopicPartition, MemoryRecords],
localProduceResults: Map[TopicPartition, LogAppendResult]): Boolean = {
requiredAcks == -1 && entriesPerPartition.nonEmpty &&
localProduceResults.values.count(_.exception.isDefined) < entriesPerPartition.size
}若等待其他副本的寫入,須同時滿足:
requiredAcks==-1
依然有數據尚未寫完
至少有一個分區的消息,已成功被寫入本地日志
2和3可結合來看。若所有分區的數據寫入都不成功,則可能出現嚴重錯誤,此時應不再等待,而是直接返回錯誤給發送方。
而有部分分區成功寫入,部分分區寫入失敗,則可能偶發的瞬時錯誤導致。此時,不妨將本次寫入請求放入Purgatory,給個重試機會。
ReplicaManager#fetchMessages負責讀取副本數據。無論:
Java消費者
APIFollower副本
拉取消息的主途徑都是向Broker發FETCH請求,Broker端接收到該請求后,調用fetchMessages從底層的Leader副本取出消息。
fetchMessages也可能會延時處理FETCH請求,因Broker端必須要累積足夠多數據后,才會返回Response給請求發送方。


整個方法分為:
讀取本地日志
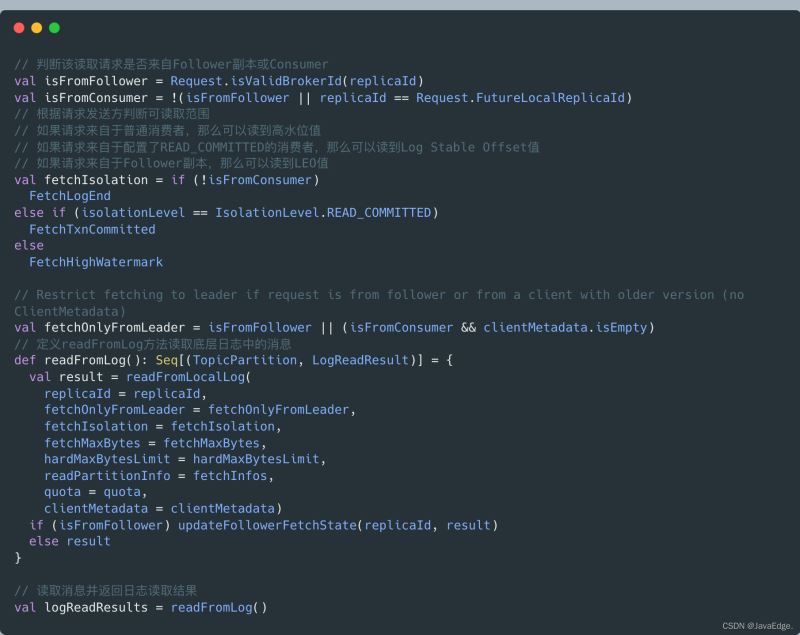
首先判斷,讀取消息的請求方,就能確定可讀取的范圍了。
fetchIsolation,讀取隔離級別:
對Follower副本,它能讀取到Leader副本LEO值以下的所有消息
普通Consumer,只能“看到”Leader副本高水位值以下的消息
確定可讀取范圍后,調用readFromLog讀取本地日志上的消息數據,并將結果賦給logReadResults變量。readFromLog調用readFromLocalLog,在待讀取分區上依次調用其日志對象的read方法執行實際的消息讀取。
根據讀取結果確定Response
根據上一步讀取結果創建對應Response:
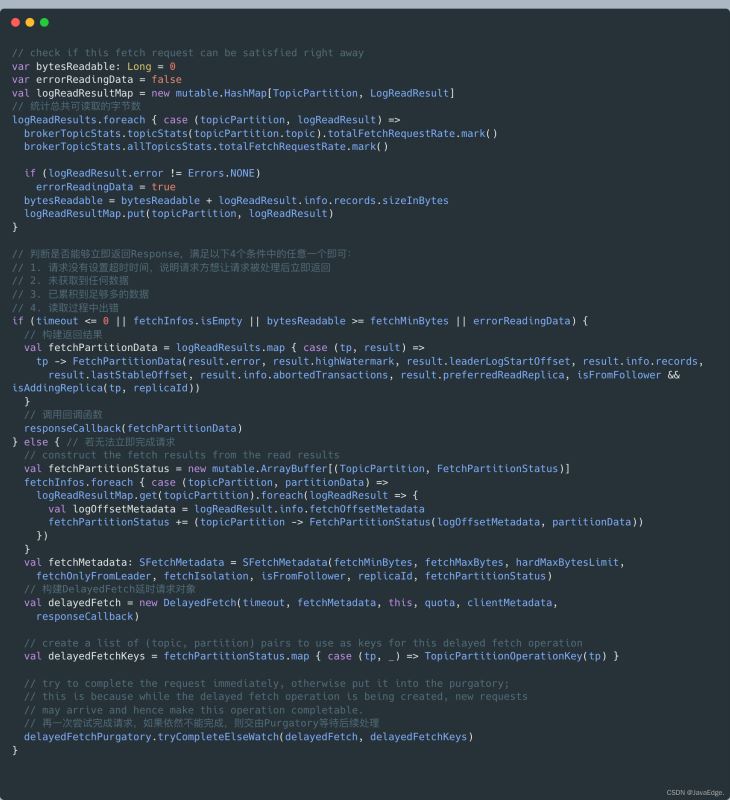
根據上一步得到的讀取結果,統計可讀取的總字節數,然后判斷此時是否能夠立即返回Reponse。
副本管理器讀寫副本的兩個方法appendRecords和fetchMessages本質上在底層分別調用Log的append和read方法,以實現本地日志的讀寫操作。完成讀寫操作后,這兩個方法還定義了延時處理的條件。一旦滿足延時處理條件,就交給對應Purgatory處理。
從這倆方法可見單個組件融合一起的趨勢。雖然我們學習單個源碼文件的順序是自上而下,但串聯Kafka主要組件功能的路徑卻是自下而上。
如副本寫入操作,日志對象append方法被上一層的Partition對象中的方法調用,而后者又進一步被副本管理器中的方法調用。我們按自上而下閱讀了副本管理器、日志對象等單個組件的代碼,了解了各自的獨立功能。
現在開始慢慢地把它們融合一起,構建Kafka操作分區副本日志對象的完整調用路徑。同時采用這兩種方式來閱讀源碼,就能更高效弄懂Kafka原理。
Kafka副本狀態機類ReplicaManager讀寫副本的核心方法:
appendRecords:向副本寫入消息,利用Log#append方法和Purgatory機制實現Follower副本向Leader副本獲取消息后的數據同步操作
fetchMessages:從副本讀取消息,為普通Consumer和Follower副本所使用。當它們向Broker發送FETCH請求時,Broker上的副本管理器調用該方法從本地日志中獲取指定消息
以上是“Kafka怎么讀寫副本消息”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





