溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
在我們大量使用分布式數據庫、分布式計算集群的時候,是否會遇到這樣的一些問題:
我們想分析下用戶行為(pageviews),以便我們設計出更好的廣告位
我想對用戶的搜索關鍵詞進行統計,分析出當前的流行趨勢
有些數據,存儲數據庫浪費,直接存儲硬盤效率又低
這些場景都有一個共同點:
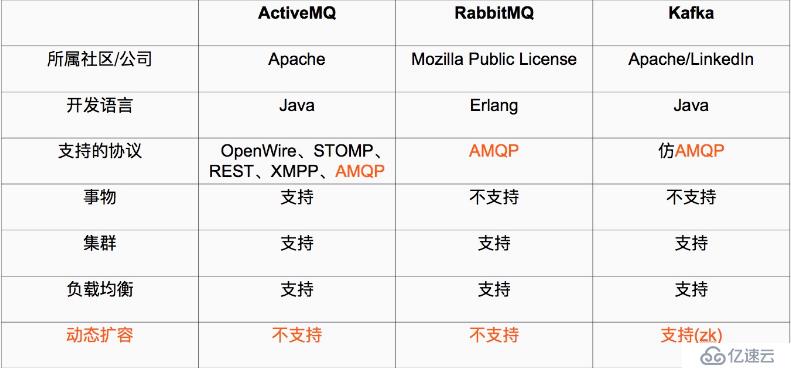
1、Java 和 scala都是運行在JVM上的語言。
2、erlang和最近比較火的和go語言一樣是從代碼級別就支持高并發的一種語言,所以RabbitMQ天生就有很高的并發性能,但是 有RabbitMQ嚴格按照AMQP進行實現,受到了很多限制。kafka的設計目標是高吞吐量,所以kafka自己設計了一套高性能但是不通用的協議,他也是仿照AMQP( Advanced Message Queuing Protocol ? 高級消息隊列協議)設計的。
3、事務的概念:在數據庫中,多個操作一起提交,要么操作全部成功,要么全部失敗。舉個例子, 在轉賬的時候付款和收款,就是一個事物的例子,你給一個人轉賬,你轉成功,并且對方正常行收到款項后,這個操作才算成功,有一方失敗,那么這個操作就是失敗的。
對應消在息隊列中,就是多條消息一起發送,要么全部成功,要么全部失敗。3個中只有ActiveMQ支持,這個是因為,RabbitMQ和Kafka為了更高的性能,而放棄了對事務的支持 。
4、集群:多臺服務器組成的整體叫做集群,這個整體對生產者和消費者來說,是透明的。其實對消費系統組成的集群添加一臺服務器減少一臺服務器對生產者和消費者都是無感之的。
5、負載均衡,對消息系統來說負載均衡是大量的生產者和消費者向消息系統發出請求消息,系統必須均衡這些請求使得每一臺服務器的請求達到平衡,而不是大量的請求,落到某一臺或幾臺,使得這幾臺服務器高負荷或超負荷工作,嚴重情況下會停止服務或宕機。
6、動態擴容是很多公司要求的技術之一,不支持動態擴容就意味著停止服務,這對很多公司來說是不可以接受的。
注:
阿里巴巴的Metal,RocketMQ都有Kafka的影子,他們要么改造了Kafka或者借鑒了Kafka,最后Kafka的動態擴容是通過Zookeeper來實現的。
1、 AMQP協議
Advanced Message Queuing Protocol (高級消息隊列協議)
The Advanced Message Queuing Protocol (AMQP):是一個標準開放的應用層的消息中間件(Message Oriented Middleware)協議。AMQP定義了通過網絡發送的字節流的數據格式。因此兼容性非常好,任何實現AMQP協議的程序都可以和與AMQP協議兼容的其他程序交互,可以很容易做到跨語言,跨平臺。
上面說的3種比較流行的消息隊列協議,要么支持AMQP協議,要么借鑒了AMQP協議的思想進行了開發、實現、設計。
2、 一些基本的概念
1、消費者:(Consumer):從消息隊列中請求消息的客戶端應用程序
2、生產者:(Producer) ?:向broker發布消息的應用程序
3、AMQP服務端(broker):用來接收生產者發送的消息并將這些消息路由給服務器中的隊列,便于fafka將生產者發送的消息,動態的添加到磁盤并給每一條消息一個偏移量,所以對于kafka一個broker就是一個應用程序的實例
kafka支持的客戶端語言
:Kafka客戶端支持當前大部分主流語言,包括:C、C++、Erlang、Java、.net、perl、PHP、Python、Ruby、Go、Javascript
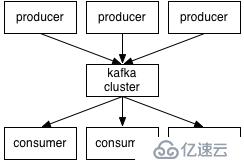
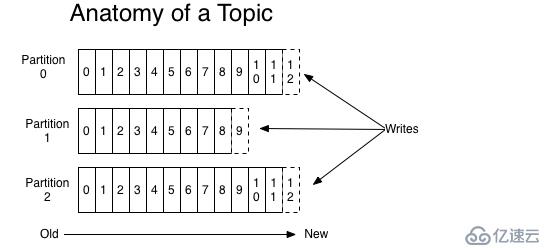
1、主題(Topic):一個主題類似新聞中的體育、娛樂、教育等分類概念,在實際工程中通常一個業務一個主題。
2、分區(Partition):一個Topic中的消息數據按照多個分區組織,分區是kafka消息隊列組織的最小單位,一個分區可以看作是一個FIFO( First Input First Output的縮寫,先入先出隊列)的隊列。
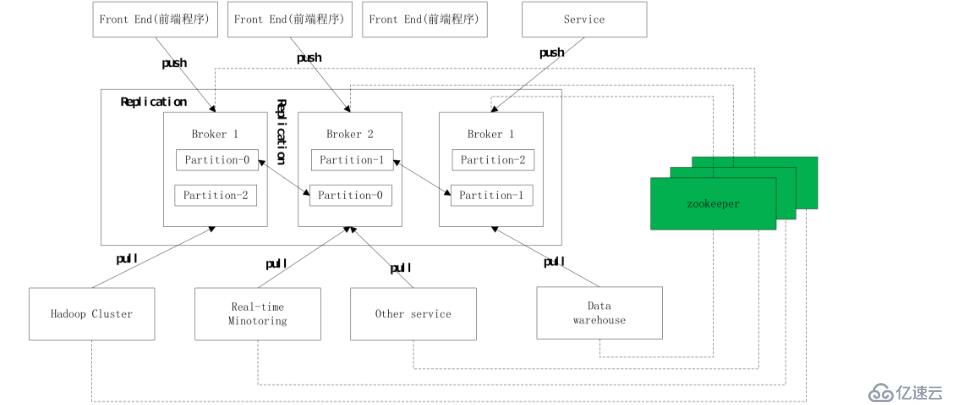
三、Zookeeper(動物園)集群搭建
kafka集群是把狀態保存在Zookeeper中的,首先要搭建Zookeeper集群。
1、軟件環境(3臺服務器-測試,一般是奇數臺服務器)
vim? /etc/hosts(3臺服務器都要寫)
192.168.11.128? server1
192.168.11.129? server2
192.168.11.130? server3
如果有四臺那么掛掉一臺還剩下三臺服務器,如果在掛掉一個就不行了,這里記住是超過半數。
2、Java jdk1.8 zookeeper是用java寫的所以他的需要JAVA環境,java是運行在java虛擬機上的
2、配置安裝zookeeper
下面的操作是: 3臺服務器統一操作
1、安裝java(我這里采用jdk安裝)
先準備jdk的包,解壓帶/usr/local下

創建軟鏈接

寫java環境變量
vim? ?/etc/profile.d/aa.sh

加載環境變量
source? /etc/profile(加載全部環境變量)? ?或者? source /etc/profile.d/aa.sh(加載這一個環境變量)
查看java有沒有安裝成功

如上圖所示,表示java環境已經部署成功
------------------------------------------------------------------------------------------------------------------------
用yum安裝java
yum? list? ?java*? ? &&? ?yum? -y? install? java
------------------------------------------------------------------------------------------------------------------------
2、下載Zookeeper(3臺服務器統一操作)
首先要注意在生產環境中目錄結構要定義好,防止在項目過多的時候找不到所需的項目
#目錄統一放在/opt下面
#首先創建Zookeeper項目目錄
cd? /opt
mkdir? ?zookeeper? ? ? ? ?//項目目錄
mkdir? ?zookeeper/zkdata? ? ? ? //存放快照日志
mkdir? ?zookeeper/zkdatalog? ? ? ?//存放事物日志
下載Zookeeper
#下載軟件
cd? ?/opt/zookeeper/
wget http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
解壓軟件
tar? ?xf? ??zookeeper-3.4.14.tar.gz
3、修改配置文件
進入到解壓好的目錄里面的conf目錄中,查看


3臺服務器的配置文件
vim? ? zoo.cfg
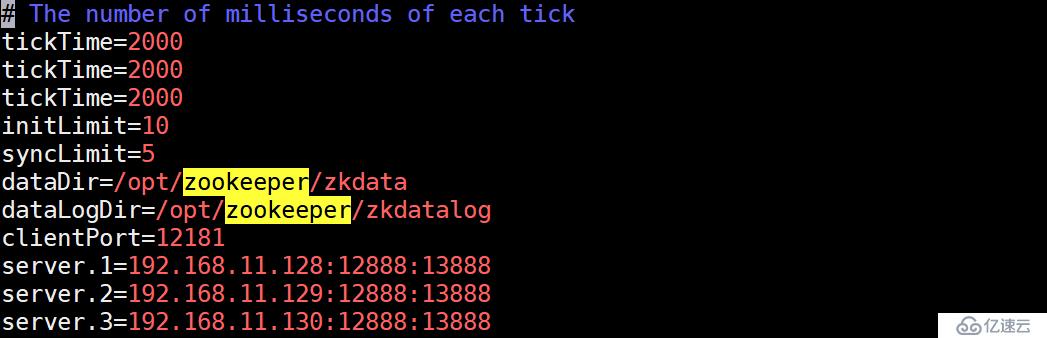

上面定義了dataDir和clientPort這2行就要注釋,否則后面起集群會報錯。
#server.1 這個1是服務器的標識也可以是其他的數字, 表示這個是第幾號服務器,用來標識服務器,這個標識要寫到快照目錄下面myid文件里
#192.168.11.139為集群里的IP地址,第一個端口是master和slave之間的通信端口,默認是2888,第二個端口是leader選舉的端口,集群剛啟動的時候選舉或者leader掛掉之后進行新的選舉的端口默認是3888
配置文件解釋:
#tickTime:
這個時間是作為 Zookeeper 服務器之間或客戶端與服務器之間維持心跳的時間間隔,也就是每個 tickTime 時間就會發送一個心跳。
#initLimit:
這個配置項是用來配置 Zookeeper 接受客戶端(這里所說的客戶端不是用戶連接 Zookeeper 服務器的客戶端,而是 Zookeeper 服務器集群中連接到 Leader 的 Follower 服務器)初始化連接時最長能忍受多少個心跳時間間隔數。當已經超過 5個心跳的時間(也就是 tickTime)長度后 Zookeeper 服務器還沒有收到客戶端的返回信息,那么表明這個客戶端連接失敗。總的時間長度就是 5*2000=10 秒
#syncLimit:
這個配置項標識 Leader 與Follower 之間發送消息,請求和應答時間長度,最長不能超過多少個 tickTime 的時間長度,總的時間長度就是5*2000=10秒
#dataDir:
快照日志的存儲路徑
#dataLogDir:
事物日志的存儲路徑,如果不配置這個那么事物日志會默認存儲到dataDir制定的目錄,這樣會嚴重影響zk的性能,當zk吞吐量較大的時候,產生的事物日志、快照日志太多
#clientPort:
這個端口就是客戶端連接 Zookeeper 服務器的端口,Zookeeper 會監聽這個端口,接受客戶端的訪問請求。修改他的端口改大點
創建myid文件(每一臺的都不一樣)
#server1
echo "1" > /opt/zookeeper/zkdata/myid
#server2
echo "2" > /opt/zookeeper/zkdata/myid
#server3
echo "3" > /opt/zookeeper/zkdata/myid
1、myid文件和server.myid ?在快照目錄下存放的標識本臺服務器的文件,他是整個zk集群用來發現彼此的一個重要標識。
2、zoo.cfg 文件是zookeeper配置文件 在conf目錄里。

zkServer.sh ?主的管理程序文件
ZooKeeper server will not remove old snapshots and log files when using the default configuration (see autopurge below), this is the responsibility of the operator
zookeeper不會主動的清除舊的快照和日志文件,這個是操作者的責任。


2、檢查服務狀態
? #檢查服務器狀態(會有一個leader和2個follower)


可以用jps查看zk的進程,這是整個工程的main
#執行命令jps

四,kafka集群搭建
1,軟件環境
1、linux一臺或多臺,大于等于2
2、已經搭建好的zookeeper集群
2、創建目錄并下載安裝軟件(3臺服務器一起操作)
#創建目錄
cd ? /opt
mkdir ? kafka ? #創建項目目錄
cd ? kafka
mkdir ? kafkalogs ? ?#創建kafka消息目錄,主要存放kafka消息
#下載軟件
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.2.0/kafka_2.11-2.2.0.tgz
#解壓軟件
tar -zxvf kafka_2.11-2.2.0.tgz
3,修改配置文件
進入到config目錄
cd /opt/kafka/kafka_2.11-2.2.0/config/
修改配置文件
broker.id=0? #當前機器在集群中的唯一標識,和zookeeper的myid性質一樣
port=19092 #當前kafka對外提供服務的端口默認是9092
host.name=192.168.7.100 #這個參數默認是關閉的,在0.8.1有個bug,DNS解析問題,失敗率的問題。
num.network.threads=3 #這個是borker進行網絡處理的線程數
num.io.threads=8 #這個是borker進行I/O處理的線程數
log.dirs=/opt/kafka/kafkalogs/ #消息存放的目錄,這個目錄可以配置為“,”逗號分割的表達式,上面的num.io.threads要大于這個目錄的個數這個目錄,如果配置多個目錄,新創建的topic他把消息持久化的地方是,當前以逗號分割的目錄中,那個分區數最少就放那一個
socket.send.buffer.bytes=102400 #發送緩沖區buffer大小,數據不是一下子就發送的,先回存儲到緩沖區了到達一定的大小后在發送,能提高性能
socket.receive.buffer.bytes=102400 #kafka接收緩沖區大小,當數據到達一定大小后在序列化到磁盤
socket.request.max.bytes=104857600 #這個參數是向kafka請求消息或者向kafka發送消息的請請求的最大數,這個值不能超過java的堆棧大小
num.partitions=1 #默認的分區數,一個topic默認1個分區數
log.retention.hours=168 #默認消息的最大持久化時間,168小時,7天
message.max.byte=5242880? #消息保存的最大值5M
default.replication.factor=2? #kafka保存消息的副本數,如果一個副本失效了,另一個還可以繼續提供服務
replica.fetch.max.bytes=5242880? #取消息的最大直接數
log.segment.bytes=1073741824 #這個參數是:因為kafka的消息是以追加的形式落地到文件,當超過這個值的時候,kafka會新起一個文件
log.retention.check.interval.ms=300000 #每隔300000毫秒去檢查上面配置的log失效時間(log.retention.hours=168 ),到目錄查看是否有過期的消息如果有,刪除
log.cleaner.enable=false #是否啟用log壓縮,一般不用啟用,啟用的話可以提高性能
zookeeper.connect=192.168.11.139:12181,192.168.11.140:12181,192.168.11.141:1218 #設置zookeeper的連接端口
上面是參數的解釋,實際的修改項為:




配置文件修改結束
4,啟動kafka集群并測試
啟動服務

2.檢查服務是否啟動
#執行命令jps

3. 創建Topic驗證是否創建成功
#創建Topic(話題)

#解釋
--replication-factor 2? ?#復制兩份
--partitions 1 #創建1個分區
--topic #主題為meinv
'''在一臺服務器上創建一個發布者'''
#創建一個broker,發布者

'''在一臺服務器上創建一個訂閱者'''

到此,服務搭建結束
5.1、日志說明
默認kafka的日志是保存在/opt/kafka/kafka_2.11-2.2.0/logs目錄下的,這里說幾個需要注意的日志
server.log #kafka的運行日志
state-change.log ?#kafka他是用zookeeper來保存狀態,所以他可能會進行切換,切換的日志就保存在這里
controller.log #kafka選擇一個節點作為“controller”,當發現有節點down掉的時候它負責在游泳分區的所有節點中選擇新的leader,這使得Kafka可以批量的高效的管理所有分區節點的主從關系。如果controller down掉了,活著的節點中的一個會備切換為新的controller.
5.2、上面的大家你完成之后可以登錄zk來查看zk的目錄情況
#使用客戶端進入zk
cd/opt/zookeeper/zookeeper-3.4.14/bin
./zkCli.sh -server 192.168.11.139:12181 ?#默認是不用加’-server‘參數的因為我們修改了他的端口
#查看目錄情況 執行“ls /”
[zk: 127.0.0.1:12181(CONNECTED) 0] ls /
#顯示結果:[consumers, config, controller, isr_change_notification, admin, brokers, zookeeper, controller_epoch]
'''
上面的顯示結果中:只有zookeeper是,zookeeper原生的,其他都是Kafka創建的
'''
#標注一個重要的
[zk: 127.0.0.1:12181(CONNECTED) 1] get /brokers/ids/1
{"jmx_port":-1,"timestamp":"1456125963355","endpoints":["PLAINTEXT://192.168.7.100:19092"],"host":"192.168.7.100","version":2,"port":19092}
cZxid = 0x1000001c1
ctime = Mon Feb 22 15:26:03 CST 2016
mZxid = 0x1000001c1
mtime = Mon Feb 22 15:26:03 CST 2016
pZxid = 0x1000001c1
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x152e40aead20016
dataLength = 139
numChildren = 0
[zk: 127.0.0.1:12181(CONNECTED) 2]
#還有一個是查看partion
[zk: 127.0.0.1:12181(CONNECTED) 7] get /brokers/topics/shuaige/partitions/0
null
cZxid = 0x100000029
ctime = Mon Feb 22 10:05:11 CST 2016
mZxid = 0x100000029
mtime = Mon Feb 22 10:05:11 CST 2016
pZxid = 0x10000002a
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
[zk: 127.0.0.1:12181(CONNECTED) 8]
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





