溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
基于Spark MLlib平臺的協同過濾算法---電影推薦系統
又好一陣子沒有寫文章了,阿彌陀佛...最近項目中要做理財推薦,所以,回過頭來回顧一下協同過濾算法在推薦系統中的應用。
說到推薦系統,大家可能立馬會想到協同過濾算法。本文基于Spark MLlib平臺實現一個向用戶推薦電影的簡單應用。其中,主要包括三部分內容:
協同過濾算法概述
基于模型的協同過濾應用---電影推薦
實時推薦架構分析
一、協同過濾算法概述
本人對算法的研究,目前還不是很深入,這里簡單的介紹下其工作原理。
通常,協同過濾算法按照數據使用,可以分為:
1)基于用戶(UserCF)
2)基于商品(ItemCF)
3)基于模型(ModelCF)
按照模型,可以分為:
1)最近鄰模型:基于距離的協同過濾算法
2)Latent Factor Mode(SVD):基于矩陣分解的模型
3)Graph:圖模型,社會網絡圖模型
文中,使用的協同過濾算法是基于矩陣分解的模型。
1、基于用戶(UserCF)---基于用戶相似性
基于用戶的協同過濾,通過不同用戶對物品的評分來評測用戶之間的相似性,基于用戶之間的相似性做出推薦。簡單來講,就是給用戶推薦和他興趣相似的其他用戶喜歡的物品。
舉個例子:

如圖,有三個用戶A、B、C,四個物品A、B、C、D,需要向用戶A推薦物品。這里,由于用戶A和用戶C都買過物品A和物品C,所以,我們認為用戶A和用戶C非常相似,同時,用戶C又買過物品D,那么就需要給A用戶推薦物品D。
基于UserCF的基本思想相當簡單,基于用戶對物品的偏好,找到相鄰鄰居用戶,然后將鄰居用戶喜歡的商品推薦給當前用戶。
計算上,將一個用戶對所有物品的偏好作為一個向量來計算用戶之間的相似度,找到K鄰居后,根據鄰居的相似度權重以及他們對物品的偏好,預測當前用戶沒有偏好的未涉及物品,計算得到一個排序的物品列表作為推薦。
2、基于商品(ItemCF)---基于商品相似性
基于商品的協同過濾,通過用戶對不同item的評分來評測item之間的相似性,基于item之間的相似性做出推薦。簡單來將,就是給用戶推薦和他之前喜歡的物品相似的物品。
例如:
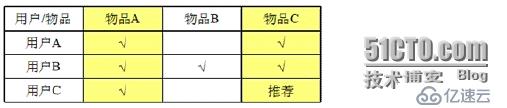
如圖,有三個用戶A、B、C和三件物品A、B、C,需要向用戶C推薦物品。這里,由于用戶A買過物品A和C,用戶B買過物品A、B、C,用戶C買過物品A,從用戶A和B可以看出,這兩個用戶都買過物品A和C,說明物品A和C非常相似,同時,用戶C又買過物品A,所以,將物品C推薦給用戶C。
基于ItemCF的原理和基于UserCF類似,只是在計算鄰居時采用物品本身,而不是從用戶的角度,即基于用戶對物品的偏好找到相似的物品,然后根據用戶的歷史偏好,推薦相似的物品給他。
從計算角度,即將所有用戶對某個物品的偏好作為一個向量來計算物品之間的相似度,得到物品的相似物品后,根據用戶歷史的偏好預測當前用戶還沒有表示偏好的物品,計算得到一個排序的物品列表作為推薦。
3、基于模型(ModelCF)
基于模型的協同過濾推薦就是基于樣本的用戶喜好信息,訓練一個推薦模型,然后根據實時的用戶喜好的信息進行預測,計算推薦。
本文使用的基于矩陣分解的模型,算法如圖:
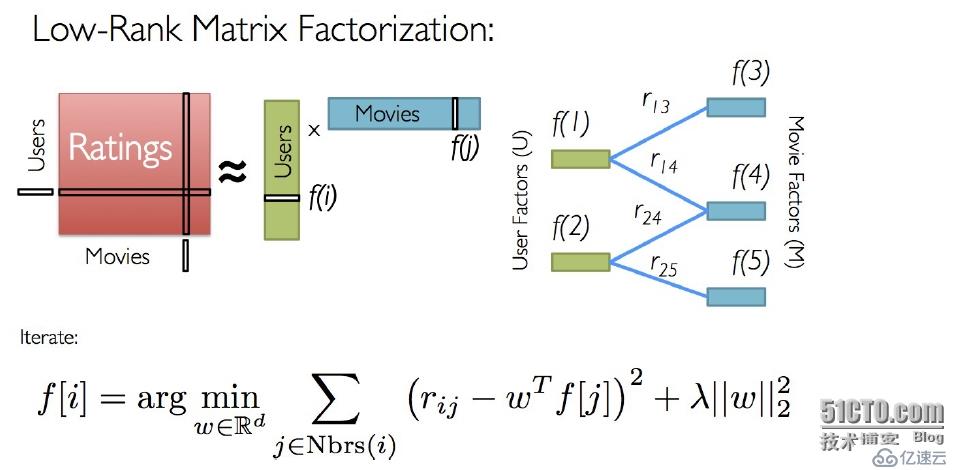
Spark MLlib當前支持基于模型的協同過濾,其中用戶和商品通過一小組隱性因子進行表達,并且這些因子也用于預測缺失的元素。MLlib使用交替最小二乘法(ALS)來學習這些隱性因子。
如果有興趣,可以閱讀Spark的這部分源代碼:
二、基于模型的協同過濾應用---電影推薦
本文實現對用戶推薦電影的簡單應用。
1、測試數據描述
本次測試數據主要包括四個數據文件:(詳細的數據描述參見README文件)
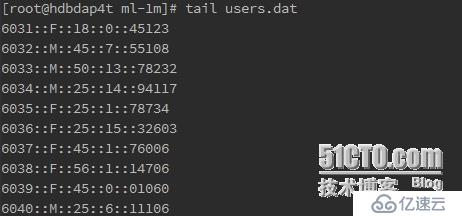
1)用戶數據文件
用戶ID::性別::年齡::職業編號::郵編
2)電影數據文件
電影ID::電影名稱::電影種類
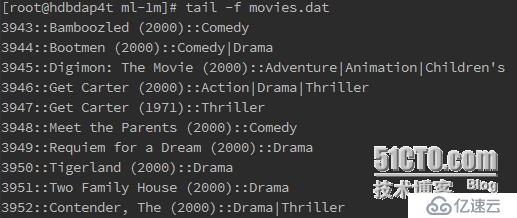
3)評分數據文件
用戶ID::電影ID::評分::時間
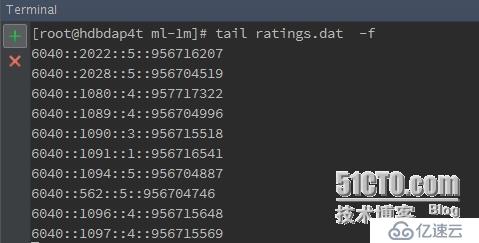
4)測試數據
用戶ID::電影ID::評分::時間
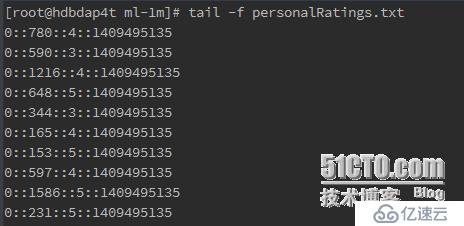
這里,前三個數據文件用于模型訓練,第四個數據文件用于測試模型。
2、實現代碼:
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.recommendation.{ALS, MatrixFactorizationModel, Rating}
import org.apache.spark.rdd._
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.SparkContext._
import scala.io.Source
object MovieLensALS {
def main(args:Array[String]) {
//屏蔽不必要的日志顯示在終端上
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.apache.eclipse.jetty.server").setLevel(Level.OFF)
//設置運行環境
val sparkConf = new SparkConf().setAppName("MovieLensALS").setMaster("local[5]")
val sc = new SparkContext(sparkConf)
//裝載用戶評分,該評分由評分器生成(即生成文件personalRatings.txt)
val myRatings = loadRatings(args(1))
val myRatingsRDD = sc.parallelize(myRatings, 1)
//樣本數據目錄
val movielensHomeDir = args(0)
//裝載樣本評分數據,其中最后一列Timestamp取除10的余數作為key,Rating為值,即(Int,Rating)
val ratings = sc.textFile(movielensHomeDir + "/ratings.dat").map {
line =>
val fields = line.split("::")
// format: (timestamp % 10, Rating(userId, movieId, rating))
(fields(3).toLong % 10, Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble))
}
//裝載電影目錄對照表(電影ID->電影標題)
val movies = sc.textFile(movielensHomeDir + "/movies.dat").map {
line =>
val fields = line.split("::")
// format: (movieId, movieName)
(fields(0).toInt, fields(1))
}.collect().toMap
//統計有用戶數量和電影數量以及用戶對電影的評分數目
val numRatings = ratings.count()
val numUsers = ratings.map(_._2.user).distinct().count()
val numMovies = ratings.map(_._2.product).distinct().count()
println("Got " + numRatings + " ratings from " + numUsers + " users " + numMovies + " movies")
//將樣本評分表以key值切分成3個部分,分別用于訓練 (60%,并加入用戶評分), 校驗 (20%), and 測試 (20%)
//該數據在計算過程中要多次應用到,所以cache到內存
val numPartitions = 4
val training = ratings.filter(x => x._1 < 6).values.union(myRatingsRDD).repartition(numPartitions).persist()
val validation = ratings.filter(x => x._1 >= 6 && x._1 < 8).values.repartition(numPartitions).persist()
val test = ratings.filter(x => x._1 >= 8).values.persist()
val numTraining = training.count()
val numValidation = validation.count()
val numTest = test.count()
println("Training: " + numTraining + " validation: " + numValidation + " test: " + numTest)
//訓練不同參數下的模型,并在校驗集中驗證,獲取最佳參數下的模型
val ranks = List(8, 12)
val lambdas = List(0.1, 10.0)
val numIters = List(10, 20)
var bestModel: Option[MatrixFactorizationModel] = None
var bestValidationRmse = Double.MaxValue
var bestRank = 0
var bestLambda = -1.0
var bestNumIter = -1
for (rank <- ranks; lambda <- lambdas; numIter <- numIters) {
val model = ALS.train(training, rank, numIter, lambda)
val validationRmse = computeRmse(model, validation, numValidation)
println("RMSE(validation) = " + validationRmse + " for the model trained with rank = "
+ rank + ",lambda = " + lambda + ",and numIter = " + numIter + ".")
if (validationRmse < bestValidationRmse) {
bestModel = Some(model)
bestValidationRmse = validationRmse
bestRank = rank
bestLambda = lambda
bestNumIter = numIter
}
}
//用最佳模型預測測試集的評分,并計算和實際評分之間的均方根誤差(RMSE)
val testRmse = computeRmse(bestModel.get, test, numTest)
println("The best model was trained with rank = " + bestRank + " and lambda = " + bestLambda
+ ", and numIter = " + bestNumIter + ", and its RMSE on the test set is " + testRmse + ".")
//create a naive baseline and compare it with the best model
val meanRating = training.union(validation).map(_.rating).mean
val baselineRmse = math.sqrt(test.map(x => (meanRating - x.rating) * (meanRating - x.rating)).reduce(_ + _) / numTest)
val improvement = (baselineRmse - testRmse) / baselineRmse * 100
println("The best model improves the baseline by " + "%1.2f".format(improvement) + "%.")
//推薦前十部最感興趣的電影,注意要剔除用戶已經評分的電影
val myRatedMovieIds = myRatings.map(_.product).toSet
val candidates = sc.parallelize(movies.keys.filter(!myRatedMovieIds.contains(_)).toSeq)
val recommendations = bestModel.get
.predict(candidates.map((0, _)))
.collect
.sortBy(-_.rating)
.take(10)
var i = 1
println("Movies recommended for you:")
recommendations.foreach { r =>
println("%2d".format(i) + ": " + movies(r.product))
i += 1
}
sc.stop()
}
/** 校驗集預測數據和實際數據之間的均方根誤差 **/
def computeRmse(model:MatrixFactorizationModel,data:RDD[Rating],n:Long):Double = {
val predictions:RDD[Rating] = model.predict((data.map(x => (x.user,x.product))))
val predictionsAndRatings = predictions.map{ x =>((x.user,x.product),x.rating)}
.join(data.map(x => ((x.user,x.product),x.rating))).values
math.sqrt(predictionsAndRatings.map( x => (x._1 - x._2) * (x._1 - x._2)).reduce(_+_)/n)
}
/** 裝載用戶評分文件 personalRatings.txt **/
def loadRatings(path:String):Seq[Rating] = {
val lines = Source.fromFile(path).getLines()
val ratings = lines.map{
line =>
val fields = line.split("::")
Rating(fields(0).toInt,fields(1).toInt,fields(2).toDouble)
}.filter(_.rating > 0.0)
if(ratings.isEmpty){
sys.error("No ratings provided.")
}else{
ratings.toSeq
}
}
}
3、運行程序
1)設置參數,運行程序
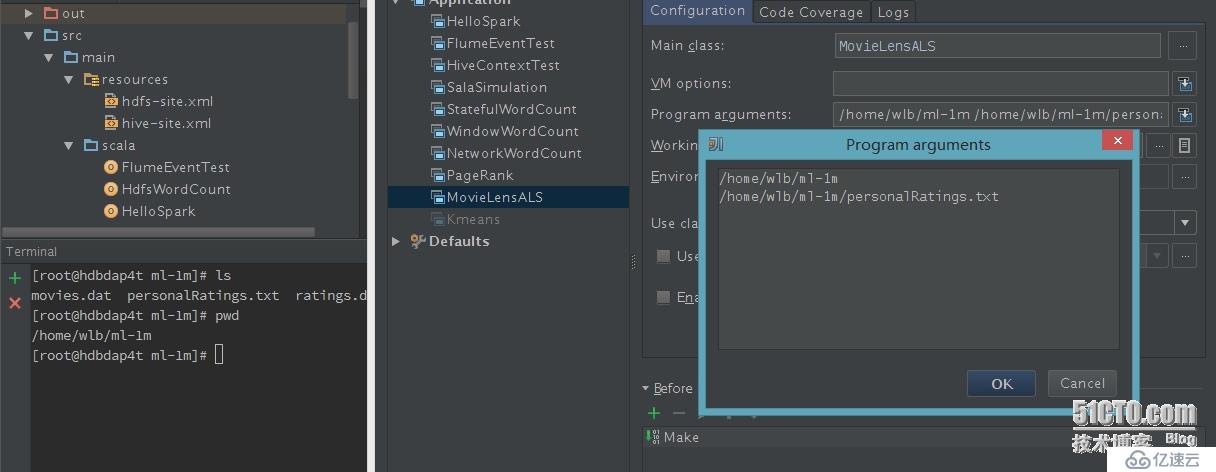
這里有兩個輸入參數:第一個是數據文件目錄,第二個是測試數據。
2)程序運行效果---模型訓練過程
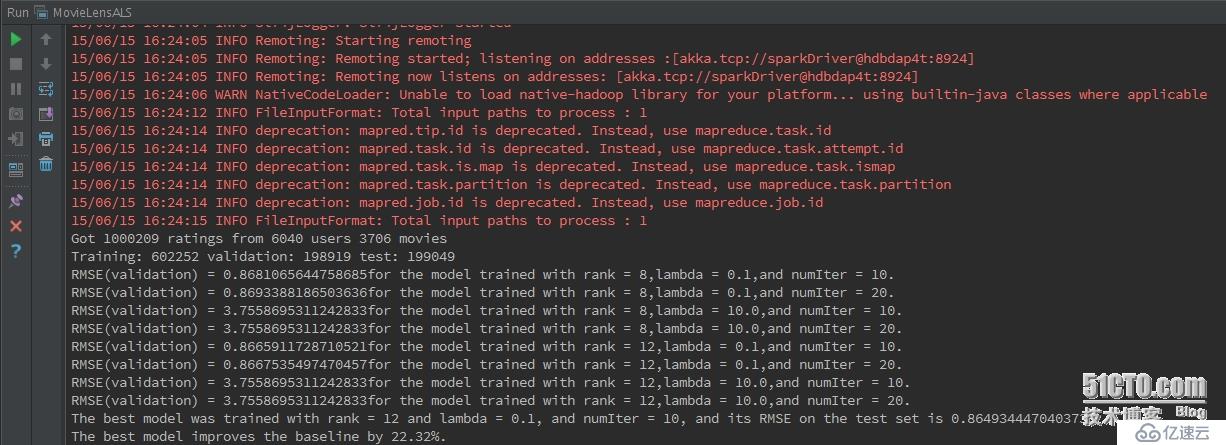
從運行效果來看,總共有6040個用戶,3706個電影(已經去重),1000209條評分數據;如程序,我們把所有數據分為三部分:60%用于訓練、20%用戶校驗、20%用戶測試模型;接下來是模型在不同參數下的均方根誤差(RMSE)值,以及對應的參數,最優的參數選擇均方根誤差(RMSE---0.8665911...)最小的參數值---即最優參數模型建立;接著,使用20%的測試模型數據來測試模型的好壞,也就是均方根誤差(RMSE),這里計算的結果為0.86493444...,在最優參數模型基礎上提升了22.32%的準確率。
說明下,其實在數據的劃分上(60%+20%+20%),最好隨機劃分數據,這樣得到的結果更有說服力。
3)程序運行效果---電影推薦結果
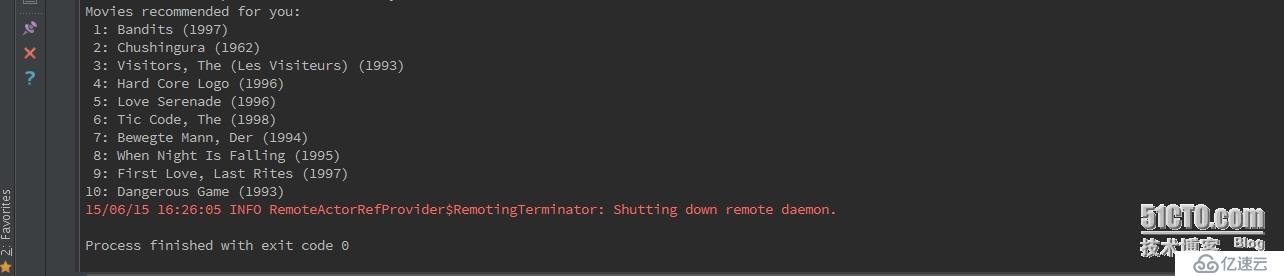
最后,給用戶推薦10部自己未看過的電影。
4、總結
這樣,一個簡單的基于模型的電影推薦應用就算OK了。
三、實時推薦架構分析
上面,實現了簡單的推薦系統應用,但是,僅僅實現用戶的定向推薦,在實際應用中價值不是非常大,如果體現價值,最好能夠實現實時或者準實時推薦。
下面,簡單介紹下實時推薦的一個架構:
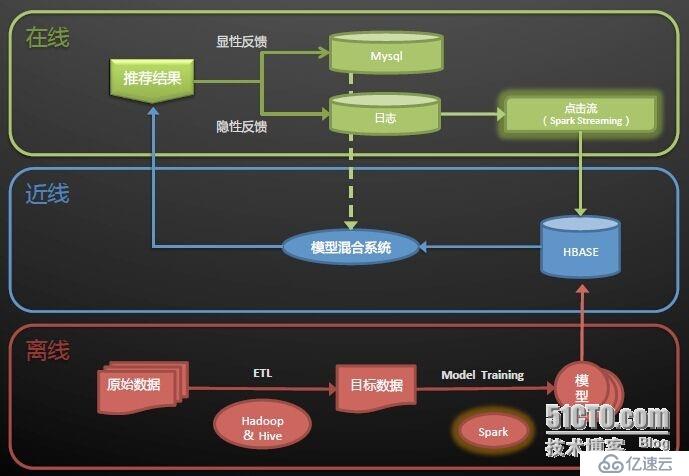
該架構圖取自淘寶Spark On Yarn的實時架構,這里,給出一些個人的觀點:
架構圖分為三層:離線、近線和在線。
離線部分:主要實現模型的建立。原始數據通過ETL加工清洗,得到目標數據,目標業務數據結合合適的算法,學習訓練模型,得到最佳的模型。
近線部分:主要使用HBase存儲用戶行為信息,模型混合系統綜合顯性反饋和隱性反饋的模型處理結果,將最終的結果推薦給用戶。
在線部分:這里,主要有兩種反饋,顯性和隱性,個人理解,顯性反饋理解為用戶將商品加入購物車,用戶購買商品這些用戶行為;隱性反饋理解為用戶在某個商品上停留的時間,用戶點擊哪些商品這些用戶行為。這里,為了實現實時/準實時操作,使用到了Spark Streaming對數據進行實時處理。(有可能是Flume+Kafka+Spark Streaming架構)
這里是個人的一些理解,不足之處,望各位指點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





