溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本教程是在三臺電腦上部署的hadoop正式環境,沒有建立用戶組,而是在當前用戶下直接進行集群的部署的,總結如下:
1、三個節點的主機電腦名為:192.168.11.33 Master,192.168.11.24 Slaver2,192.168.11.4
Slaver1,并且這三臺主機用戶名都要設置一樣,我的都是hadoop的用戶。
因為本教程使用的是vim編輯器,如果沒有vim可以下載一個:sudo apt-get install vim
2、修改hosts文件:切換到root用戶下:sudo -s,然后輸入密碼,vim /etc/hosts,通過vim把三個電腦的主機名和ip地址都加進去,ip在前,主機名在后:
192.168.12.32 Master
192.168.12.24 Slaver2
192.168.12.4 Slaver1
3、修改主機的名稱,也是在root用戶下,vim /etc/hostname,把三個主機的名字分別于上面的Master,Slaver1,Slaver2,對應,一個機器對應一個主機名,不能把三個都放進去
4、在Ubuntu中查看ip地址的命令為:ifconfig
5、安裝ssh,在安裝ssh之前,首先要更新下載Ubuntu軟件的源:sudo apt-get update
安裝ssh: sudo apt-get install ssh
查看sshd服務是否啟動:ps -e | grep ssh ,如果出現 1019 ?00:00:00 sshd這樣的信息,表 示ssh已經啟動。如果沒有啟動,則輸入:/etc/init.d/ssh start或者sudo start ssh,進行啟動
6、設置ssh的無秘鑰登錄,這個不需要再root用戶下進行,不然不是在當前用戶下,則不能進行無秘鑰登錄的設置
6.1、ssh-keygen -t rsa ,然后一直按回車鍵
6.2、上述操作完畢后,會在當且用戶下有一個隱藏文件夾.ssh,可以通過:ls -al進行查看
里面的文件有:id_rsa,id_rsa.pub
6.3、進入.ssh目錄下:cd .ssh,然后執行:cat id_rsa.pub >> authorized_keys(此文件剛開始 時不存在.ssh目錄中的),執行完以后,會自動生成一個authorized_keys文件
6.4、然互在.ssh下直接登錄:ssh localhost,不出意外的話,將成功登錄并且不需要輸入密碼,登錄完成后,在.ssh下會生成一個known_hosts的文件
7、上面的三個主機都要執行6的操作
8、設置節點之間的無秘鑰登錄,配置Master對Slaver1和Slaver2的無秘鑰登錄,把Master的id_rsa.pub復制到Slaver1和Slaver2節點上,在Slaver1和Slaver2節點上的.ssh目錄下分別執行如下命令:
scp hadoop@Master:~/.ssh/id_rsa.pub ./master_rsa.pub
cat master_rsa.pub >> authorized_keys
9、完成以上操作時,在Slaver1和Slaver2上分別執行這樣的操作,即實現三個機器彼此之間都要實現無秘鑰登錄,因為在hadoop中,主節點和從節點之間要進行通訊,namenode需要管理datanode,并且datanode也要想namenode發送狀態信息,來告訴namenode自己的狀態,同時datanode之間也要進行通訊,在數據的復制中和存儲中,hadoop的把數據分成三個副本進行存儲,在復制中,是從前一個datanode獲取數據,放到當前的datanode中,所以要實現三個節點之間的相互通訊。
10、完成上面的可以進行無秘鑰登錄:ssh Slaver1、ssh Slaver2,ssh Master,退出當前用戶可以直接用exit
11、如果在步驟6的6.4需要密碼,則說明無秘鑰登錄設置失敗,辦法就是卸載ssh,在重新安裝,從6在重新開始,卸載前要先關閉sshd服務:sudo stop ssh,然后執行:
sudo apt-get autoremove openssh-server
sudo apt-get autoremove openssh-client,
同時要刪除.ssh文件目錄:sudo rm -rf .ssh,最好重啟一下,然后從步驟5重新開始。
12、安裝java jdk,在當前用戶下建立一個目錄:sudo mkdir Java,這樣不是在root用戶下進行的,而是在本用戶下進行安裝的。
12.1 解壓: tar zxvf jkd名稱 -C(大寫) /Java
12.2 把Java目錄中的文件名改為:jdk8:sudo mv jdk名稱 jdk8
12.3 配置文件java路徑:vim ~/.bashrc 在文件的最后加入下面的內容
export JAVA_HOME = /home/hadoop/Java/jdk8
export JRE_HOME =${JAVA_HOME}/jre
export CLASSPATH=.:{JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
12.4 退出后,執行:source ~/.bashrc使其立即生效
12.5 檢查jdk是否安裝成功:java -version,如果出現java的版本等信息,則說明安裝成功
13、安裝hadoop,在主機Master進行hadoop的安裝和配置,然后把此hadoop復制到Slaver1和Slaver2上,這樣的一種安裝雖然說不是最優的,但是對于初學者來說,是最方便的,當逐漸深入hadoop的學習時,可以在根據不同的機器以及性能,對hadoop進行調優。
13.1 把hadoop解壓到用戶的當前目錄中:tar -zxvf /Downloads/hadoop壓縮文件,壓縮文件后面沒有跟任何的路徑,就會在用戶下當前目錄建立一個解壓的hadoop目錄。
13.2 修改hadoop的文件名:mv hadoop名稱 hadoop
13.3 配置profile文件:vim /etc/profile:
export HADOOP_INSTALL =/home/hadoop/hadoop
export PATH = $PATH:${HADOOP_INSTALL}/bin
13.4 進入hadoop目錄中:cd hadoop,然后輸入:source /etc/profile 從而使剛才配置的文件生效
14、Hadoop配置文件的配置,由于hadoop1.x和hadoop2.x使用了不同的資源管理,在hadoop2.x增加了yarn來管理hadoop的資源,同時hadoop的文件目錄hadoop1.x和hadoop2.x還是有比較大的差別的,本教程采用的是hadoop2.7.0,在這里本人多說一句,有很多人建議對于初學者而言,最好使用hadoop0.2.0這樣的版本來進行學習;本人建議沒有必要這樣,因為hadoop是在不斷發展,說白了我們學習hadoop的目的是為了以后在工作中可以使用,現在公司一般都把自己的hadoop集群升級到hadoop2.x的穩定版本了,而且hadoop0.2.0與現在的hadoop版本有了很大的區別;對于理解hadoop的學習時有一定的幫助,但是沒有必要非要從頭開始學習,可以直接學習hadoop2.x,也可以不費太大的力氣就可以學會的,并且hadoop2.x的書籍中,對之前的版本是會有介紹的,而且資料也比較的多。
14.1 進入到hadoop的配置文件(這個是hadoop2.7.0版本的文件組織):
cd /hadoop/etc/hadoop
使用:ls,可以看到很多的配置信息,首先我們配置core-site.xml
14.2 配置hadoop的core-site.xml: vim core-site.xml,
在尾部添加:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.12.32:9000</value> //這個一定要用主機的ip,在eclipse 的配置中需要用到。這個在eclipse鏈接hadoop將會談到,暫且這樣來進行配置
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/temp</value>
</property>
</configuration>
在按照上面的配置時,上面的注釋一定要去掉啊
14.3 配置hadoop的hdfs-site.xml:vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address<name>
<value>192.168.12.32:50090</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop/temp/dfs/name</value>
//其中home為根目錄,第一個hadoop是我建立的hadoop用戶,第二個hadoop是安裝hadoop時,建立的hadoop文件名,這個是設置臨時文件的地方,當在初始化文件系統后,我們會在我們安裝的hadoop路徑下看見有一個temp的目錄,這個路徑的設置,大家可以根據各自的喜好進行設置,但是設置好后,自己以后能找到啊~~
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop/temp/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>2</value> //由于本人是三臺機器,可以設置2個副本,當兩個計算機2時,要設置為1
</property>
</configuration>
當大家在配置時,一定要把//后面的注釋去掉啊~~
14.4 配置mapred-site.xml,這個文件開始時不存在的,首先需要從模板中復制一份:
cp mapred-site.xml.template mapred-site.xml
如果存在這個文件,就不用使用這個操作啦
然后進行mapred-site.xml的配置:vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
14.5 配置yarn-site.xml :vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value> //這個是主機名
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
14.6 配置slaves文件:vim slaves
Slaver1
Slaver2
15、配置hadoop-env.sh文件,在此文件中有一個導入java的目錄,但是用#給注釋掉啦,去掉后#,然后,把剛才安裝的jdk8目錄放在后面:export JAVA_HOME=/home/hadoop/Java/jdk8
16、復制hadoop到Slaver1和Slaver2上:
scp -r ./hadoop Slaver1:~
scp -r ./hadoop Slaver2:~
17、由于我們步驟13的配置,把hadoop的bin加入到shell命令中,因此在當前目錄下就可以使用hadoop命令了啊:
17.1 格式化文件系統:hadoop namenode -formate
會顯示多行的配置,在倒數5行左右,如果看到sucessfull等字,說明格式化成功
17.2啟動hdfs:start-dfs.sh
17.3 啟動yarn:start-yarn.sh
17.4 查看是否啟動成功:jps,如果在Master上出現四行提示信息:
5399 Jps
5121 ResourceManager
3975 SecondaryNameNode
4752 NameNode
則表示啟動成功,顯示的順序和左邊的數字可以不一樣,
在Slaver上如果出現三行提示信息:
4645 Jps
4418 DataNode
4531 NodeManager
則表示成功;如果在Slaver上,datanode無法啟動,可能是因為以前配過偽分布式的hadoop集群,可以試著把剛才配置的temp文件夾給刪除掉,重新進行格式化:hadoop namenode -format,在進行啟動,應該可以使用啦
17.5 這個時候,我們就可以用hadoop的shell命令來進行操作了啊:
hadoop dfs -ls
這個可能會出現錯誤提示’ls’ ‘.’:no file or directiory
這個時候我們可以試試:hadoop dfs -ls /,就不會出現錯誤了啊
建立目錄:
hadoop dfs -mkdir /user
hadoop dfs -mkdir /user/hadoop
Hadoop dfs -mkdir /user/hadoop
Hadoop dfs -mkdir /user/hadoop/input
Hadoop dfs -mkdir /user/hadoop/output
完事以后,就會出現三級目錄了,然后建立一個文本,來運行一下wordcount程序:
Vim a.txt,在里面隨便寫一下東西:
Hadoop
Hadoop
Aaa
Aaa
Spark
Spark
然后把這個傳到hdfs上:hadoop dfs -copyFromLocal a.txt /user/hadoop/input/a.txt
運行wordcount程序:
hadoop jar hadoop/share/hadoop/mapreduce/hadop-mapreduce-examples-2.7.0.jar wordcount /user/hadoop/input/a.txt /user/hadoop/output/wordcount/
查看運行的結果:hadoop dfs -cat /user/hadoop/output/wordcount/part-r-00000,就可以看到單詞的統計。
18、靜態ip的設置:網上有很多的關于靜態ip的設置,本人找了一個,按照上面的教程方法,結果把Master主機上的右上角的上網圖標給弄沒有了啊,并且有些還上不了網啊,花費了一個下午的時間,終于弄明白了啊。設置永久性的靜態ip,需要三個步驟,配置三個文件即可。
18.1 設置靜態ip:sudo vim /etc/network/interfaces,會有如下信息:
auto lo
iface lo inet loopback
注釋掉:#ifacelo inet loopback
添加:
auto eth0
iface eth0 inet static
address 192.168.12.32 ip地址
netmask 255.255.255.0 子網掩碼
gateway 192.168.12.1 網關
network 192.168.0.0
broadcast 192.168.11.255 廣播
然后保存退出
18.2 配置DNS服務器,這個網上有很多,關于這個的配置,但是當我們重啟Ubuntu后,又恢復默認的配置,導致無法正常上網,因此我們需要設置永久的DNS服務器:
sudo vim /etc/resolvconf/resolv.conf/base
在里面添加:nameserver 202.96.128.86 DNS服務器(這個是我的DNS地址),如果不知道自己的DNS服務,可以從windows中的網絡中查看,網上有很多放法,這里就不多說了啊
然后保存退出
18.3 配置Networkmanager.conf文件
sudo vim /etc/NetworkManager/NetworkManager.conf
里面的managed=false,如果是false,則需要把它改為true,否則不加修改,保存退出
18.4 一定要是重新啟動機器,如果啟動機器時,無法上網,則需要看18.3,的文件是否是false,需要改過來,再重啟機器就可以上網了啊。
19、上面是關于正式環境的集群,已經搭建成功;然后我們一般不會再Master上進行開發的,我們需要在windows環境下的eclipse進行開發,并在eclipse進行測試,因此,我們下面需要做得就是在windows7+eclipse下構建hadoop的開發環境;
19.1、下載eclipse的hadoop組件,由于hadoop2.x以后,Apache就不在提供eclipse的hadoop組件,只提供源碼,我們需要自己構建。我是從網上下載一個eclipse的hadoop組件。
如果采用的hadoop是2.7.0版本的,使用hadoop2.6.0的hadoop組件是可以使用的,我的hadoop版本是2.7.0,而eclipse的hadoop組件是hadoop2.6.0,
下載組件地址:
19.2、選擇eclipse的版本,我采用的是spring-tool,它是集成了eclipse的,采用這個的原因是實習的時候用的就是這個版本,而且從網上看到好多直接用eclipse的人,需要版本的選擇,以及出現的錯誤比較多。
下載地址:http://spring.io/tools,點擊下圖的地方進行下載,下載后直接解壓到一個磁盤上就可以使用啦。
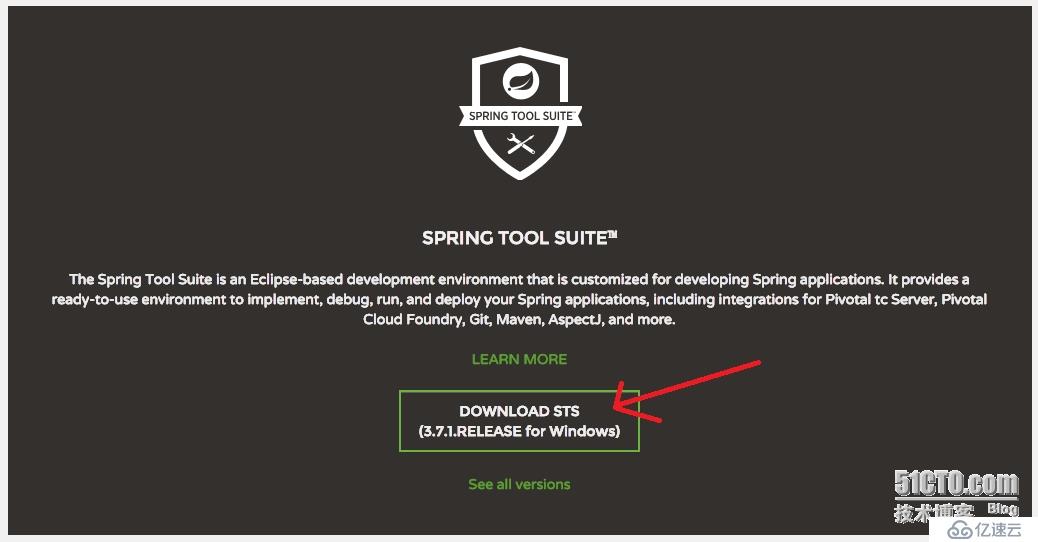
進入到sts-3.7.1RELEASE里面,有一個STL.exe就可以打開了。
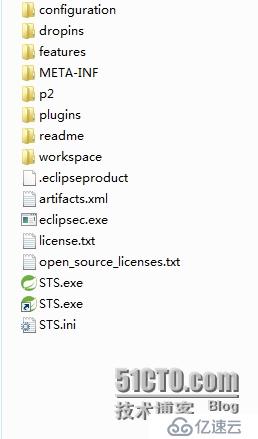
19.3、把剛才下載的eclipse的hadoop組件2.6.0放到上圖中plugins里面,就可以重啟STL,然后點擊Window->Preferences,就會看到
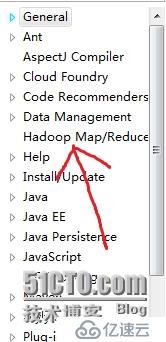
則表示組件安裝成功,然后點擊Window->Perspective->Open Perspectiver->other,就會在左上角看到:
在正下方會看到:

右鍵點擊上圖的Location,會出現這個三個選項,點擊New Hadoop Location,就會彈出如下信息:
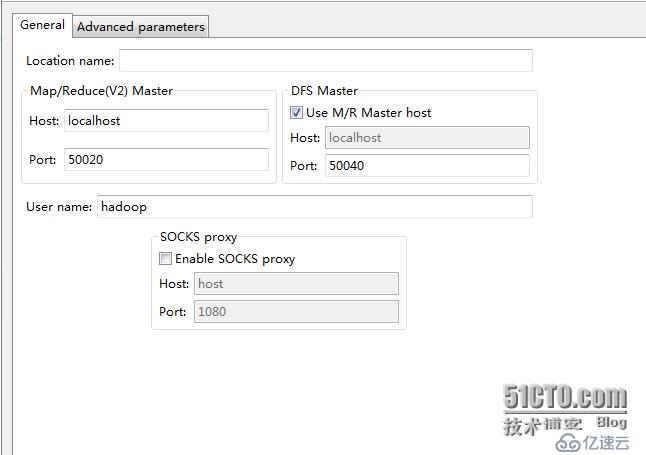
上面的Location name:可以自己隨便填寫一個名字我起的是:myhadoop
Host:192.168.12.32,這個是我們安裝集群的Master的ip地址,而不是直接填寫Master,是因為當填寫Master時,當鏈接hdfs時,會出現listing folder content錯誤,而且,我們在配置core-site.xml,文件的時,也是建議大家用ip地址,而不是Master,用意就是在這個地方。
Port:9001,這個是和我們設置的core-site.xml的配置一樣的,
DFS Master中,Prot:9000,
然后保存退出;
19.4、然后點擊這個的DFS Locations
會出現
 這個名字,和剛才我們設置的一樣啊,
這個名字,和剛才我們設置的一樣啊,
然后再點擊myhadoop,會出現:
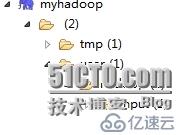
這個是我建立的hadoop目錄。到這里整個hadoop的安裝,以及hadoop在windows下的遠程開發都已經基本介紹完畢。但是真正實現hadoop的開發,還需要在eclipse中進行maven的安裝學習。這個以后再慢慢寫吧
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





