溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關正則表達式用法是怎么樣的,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
在我們寫頁面時,往往需要對表單的數據比如賬號、身份證號等進行驗證,而最有效的、用的最多的便是使用正則表達式來驗證。那什么是正則表達式呢?
正則表達式(Regular Expression)是用于描述一組字符串特征的模式,用來匹配特定的字符串。 它的應用非常廣泛,特別是在字符串處理方面。其常見的應用如下:
驗證字符串,即驗證給定的字符串或子字符串是否符合指定的特征,例如,驗證是否是合法的郵件地址、驗證是否是合法的HTTP地址等等。
查找字符串,從給定的文本當中查找符合指定特征的字符串,這樣比查找固定字符串更加靈活。
替換字符串,即查找到符合某特征的字符串之后將之替換。
提取字符串,即從給定的字符串中提取符合指定特征的子字符串。
正所謂工欲善其事必先利其器! 所以我們需要知道下面幾個主要的工具:
http://www.regexpal.com/ 這個網站中,我們可以在線測試正則表達式。
http://regexr.com/ 這個網站更為推薦,它自身還包括了一個實例使我們直接測試。
正則表達式中元字符恐怕是我們聽得最多的了。元字符(Metacharacter)是一類非常特殊的字符,它能夠匹配一個位置或者字符集合中的一個字符。 如.、\w等都是元字符。
剛剛說到,元字符既可以匹配位置,也可以匹配字符,那么我們就可以通過此來將元字符分為匹配位置的元字符和匹配字符的元字符。
即匹配位置的元字符只有^(脫字符號)、$(美元符號)和\b這三個字符。分別匹配行的開始、行的結尾以及單詞的開始或結尾。它們匹配的都只是位置。
如^zzw匹配的是以"zzw"為行開頭的"zzw"(注意:我這里想要表達的是:盡管加了一個^,它匹配的仍是字符串,而不是一整行!),如果zzw不是作為行開頭的字符串,則它不會被匹配。
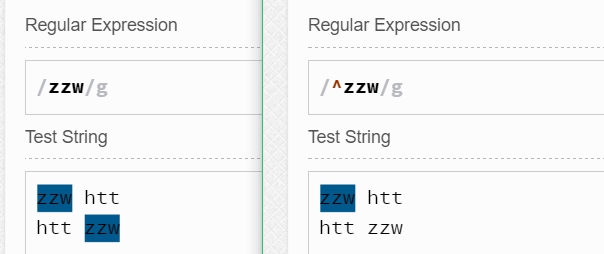
如zzw$匹配的是以"zzw"為行結尾的"zzw"(同樣,這里$只是匹配的一個位置,那個位置是零寬度,而不是一整行),如果zzw不是作為行的結尾,那么它不會被匹配。
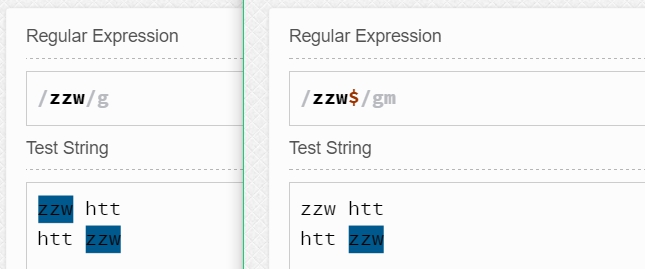
于是結合^和$我們就不難猜測^zzw$匹配的是某行中只有zzw這個字符串了。
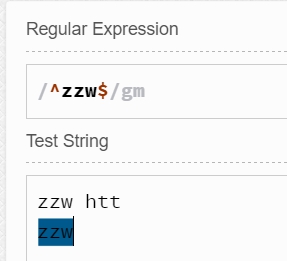
而^$匹配的則是一個空行,這個空行中不包含任何字符串。
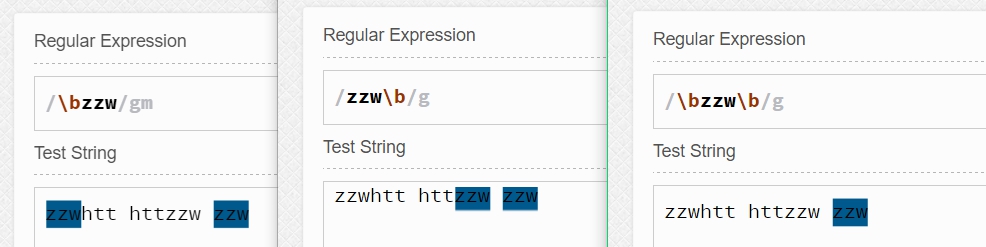
如 \bzzw匹配的是zzw之前是空格符號、標點符號或換行符號的zzw(注意:但\b匹配的僅是一個零寬度的位置,而不會匹配空格、標點符號或換行符號)。
而zzw\b匹配的是zzw之后是空格符號、標點符號或換行符號的zzw(同樣,\b匹配的是一個零寬度的位置)。
顯然 \bzzw\b匹配的就是zzw的前后必須是空格符號、標點符號或換行符號的zzw。
即匹配字符的元字符共有七個。
其中.(點號)表示匹配除換行符之外的任意字符;
\w 匹配單詞字符(不僅僅是字母,還有下劃線、數字和漢字);\W匹配任意的非單詞字符(注意,與\w剛好相反);
\s匹配的是任意的空白字符(如空格、制表符、換行符、中文全角空格等);
\S匹配的是任意的非空白字符(注意:剛好和\s相反);
\d匹配任意的數字;
\D匹配任意的非數字字符(注意:剛好和\d相反)。
例子如下所示:
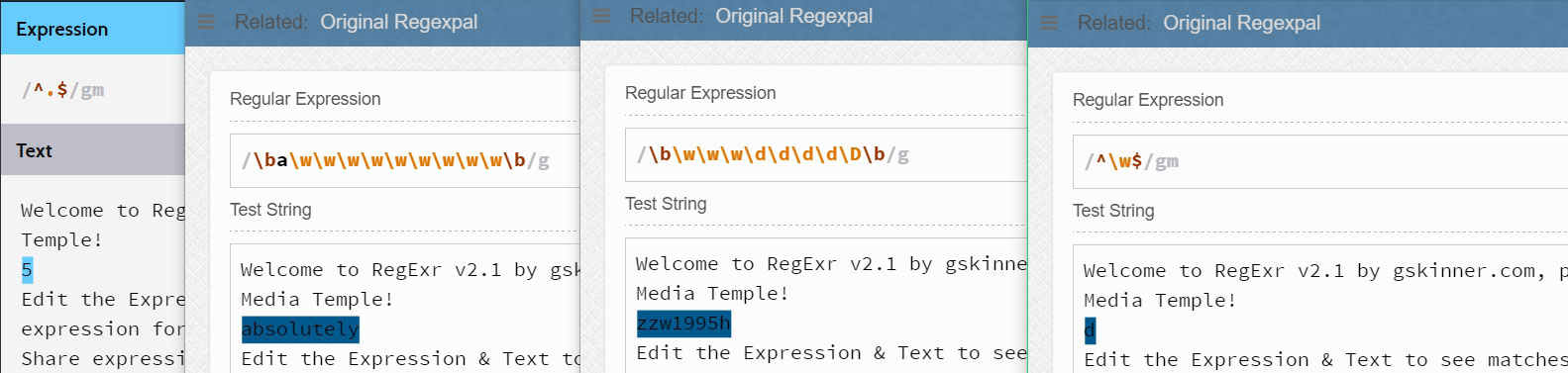
上面的四個例子從左到右依次表示:
^.$表示匹配一行中的唯一一個任意的非換行符的字符
\ba\w\w\w\w\w\w\w\w\w\b表示匹配以字母a開始的后面有9個字母字符的單詞。 (注意:其中的a并不是元字符,就是一個普通的字符,我們稱之為字符串字面值(string literal)-所謂字符串字面值,就是字面上看起來是什么就是什么)
\b\w\w\w\d\d\d\d\D\b表示匹配以3個字母字符開始后面緊跟著四個數字字符且最后一個不是數字字符的單詞。
這一部分我們將通過字符類、字符轉義、反義這幾個部分來學習。
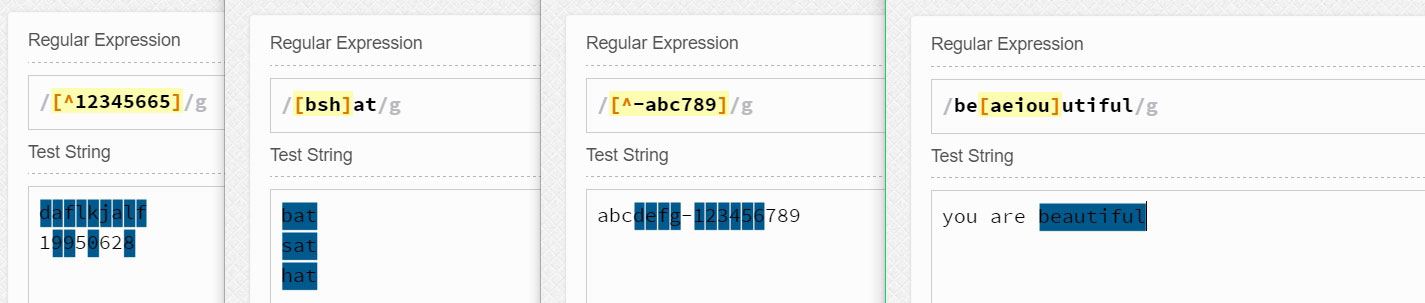
字符類是正則表達式中的“迷你”語言,可以在[]中定義。
最簡單的字符類可以由[]和幾個簡單的字母組成。比如[aeiou]可以匹配aeiou五個字母中的任意一個。[0123456]可以匹配0123456這七個數字中的任意一個。而<H[123456]>可以匹配到HTML標記中的<H1><H2><H3><H4><H5><H6>中的任意一個標記。而[bhc]at就會匹配字符串bat、hat、cat。也就是說字符類[]中的多個字符只會匹配其中一個。
但是顯然[0123456]、<H[123456]>這樣的表示太麻煩,需要寫的很多,所以我們可以使用 -連字符)來簡寫之,如[0-6]和<H[1-6]>。于是可知[0-9]和\d的作用是一樣的。[a-z]可以表示所有的小寫字母,[A-Z]可以表示所有的大寫字母。[a-zA-Z]可以表示所有的大寫字母和小寫字母。
值得注意的是 -(連字符) 只有在字符類中的中間位置時才是“到”的意思。而[-b]5中-沒有在兩個字符之間,所以它表示的是-5或者b5。
除此之外,我們知道^時只匹配行的開頭,但是如果^出現在字符類中的第一個位置,那么它表示否定該字符類。如[^123]表示匹配不是數字1或2或3的其他任意字符。[^-]表示匹配不是-的任意字符。
由此我們也可以發現:在字符類中使用元字符(-、^等)時,不需要進行轉義運算。
更常用的有[^aeiou]匹配元音之外的字符、[0-9a-zA-Z_]匹配任何數字、字母(大寫和小寫)和下劃線,這等同于\w、[^0-9a-zA-Z_]匹配任何非數字、字母(大寫和小寫)和下劃線,這等同于\W。
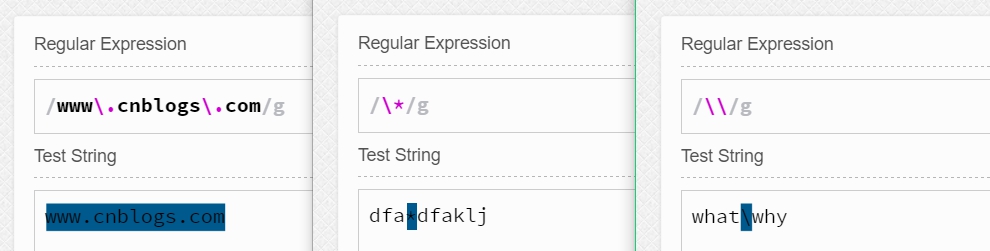
我們知道元字符如&、^、.等都表示著特殊的涵義,如果我們希望把他們看作一般的字符去匹配字符串,并且恰好他們又都不在字符類(如[&]中),我們就需要使用\(反斜杠)進行轉義了。
如我們可以使用www.mlszssj.com來匹配www.mlszssj.com。 我們可以用\*來匹配字符串中的*(通配符)。 我們還可以通過\\來匹配\。舉例如下所示:
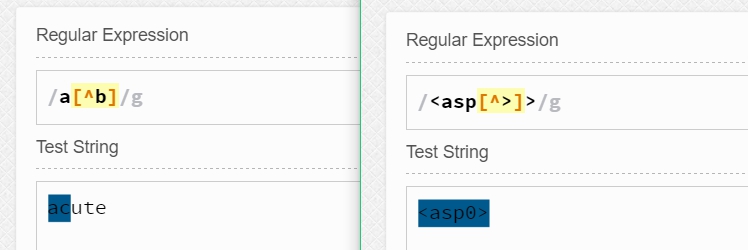
實際上我們在前面已經說過了,這里再說一遍是因為希望可以引起注意,即^再字符類中的最前面時表示對這個字符類中的字符表示否定。如a[^b]匹配a和a后面不是b的字符。又如<asp[^>]>表示匹配<asp和其后面的字符不是>的字符。舉例如下:
什么是限定符呢? 我們知道,在前面的例子中,我曾經使用過\ba\w\w\w\w\w\w\w\w\w\b表示匹配以字母a開始的后面有9個字母字符的單詞,顯然這樣寫是十分麻煩的,如果我們能把\w這些重復的用簡單的形式來寫就好了~ 沒錯,限定符就是干這個的,利用限定符我們可以重新寫成\ba\w{9}\b。對,就是這么簡單! 下面讓我們了解更多吧。
{n} 表示重復n次,如\w{5}表示匹配個單詞字符。
{n,} 表示重復至少n次,如\w{5}表示匹配至少5個單詞字符,也可以是6個,7個……
{n,m} 表示重復至少n次,最多m次,如\w{5,10} 表示匹配至少5個,最多10個單詞字符。
* 表示重復至少0次。 等同于{0,} ,即hu*t可以匹配ht或hut或huut或huuut……
+ 表示重復至少1次。 等同于{1,},即hu+t可以匹配 hut或huut或huuut……
? 表示重復0次或1次。等同于{0,1},即colou?r表示匹配color或者是colour。
顯然,上面的限定符所指的i安定都是限定的前面的某一個字符。
但是,如果我們在上面的限定符之后加上一個?呢 ,這時我們稱之為懶惰限定符。 相應地,我們稱上面幾種匹配為貪婪匹配。
{n}? 等同于{n}
{n,}? 盡可能少的使用重復,但至少使用n次
{n,m}? 重復n次到m次之間,但要盡可能少的使用重復。
*? 盡可能少的使用重復的第一個匹配
+? 盡可能少的使用重復,但至少使用1次
?? 使用零次重復(如果有可能)或者一次重復
比如:對于aabab這個要 匹配的字符串而言,使用a.*b會匹配aabab,而如果使用a.*?b就會匹配aab和ab,而不是匹配所有。

字符的運算包括替換、分組和反向引用,下面我將逐項介紹。
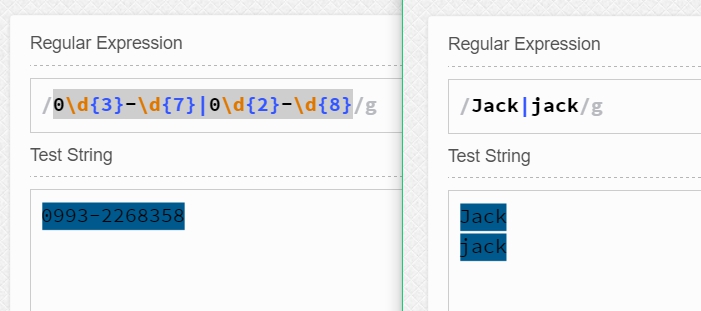
什么是替換呢? 顯然就是指一個不行,我用另一個來替換,比如0\d{3}-\d{7}|0\d{2}-\d{8} 就表示匹配前4位為區號、后7位為本地號碼的電話號碼,亦可匹配前3位為區號、后8位為本地號碼的電話號碼。| 表示的就是替換了。 又如[Jj]ack和Jack|jack的匹配效果是一樣的都是用來匹配Jack或jack的。也就是說,替換|是或運算的關系。
在一般的或運算中0 0結果為0, 0 1結果為1, 1 0結果為1, 1 1結果為1。那么在正則表達式中同樣是這樣,如果一個都匹配不上就不匹配;如果有一個能匹配上就匹配一個;如果兩個都能匹配上,就匹配兩個。 舉例如下所示:
正則表達式中,分組也是一個非常重要的概念。看似復雜,實際上分組就是使用"("和")",即左圓括號和右圓括號將某些字符括起來看成一個整體來處理。
比如我們希望匹配abcabc。如果是abc{3}匹配的就是abccc,這不能達到預期,所以我們可以對abc分組,即(abc){3}就可以匹配到我們想要的字符串了。
又如(\d{1,3}\.){3}\d{1,3}也用了分組的運算方式,它可以用來匹配簡單的IP地址,如下所示:

上面我們通過()可以進行分組,而分組的同時,每一個組被自動賦予了一個組號,該組號可以代表該組的表達式。
編組的規則是:從左到右、以分組的左括號"("為標志,第一個分組的組號為1,第二個分組的組號為2,以此類推。
這時,反向引用就派上用場啦。我們就可以用它來反向引用使用()括起來的字符組了。具體怎么引用呢?規則如下:
\數字,使用數字命名的反向引用。注:這個是通用的一種方式。
\k<name>,使用指定命名的反向引用。注:這個是.NET Frameword支持的一種方式。
下面的幾個例子是使用數字命名的反向引用:
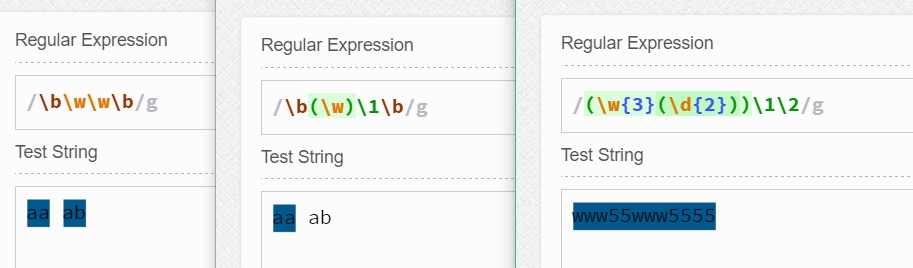
其中我們可以看到第一個和第二個匹配的并不相同---第一個匹配的是兩個任意單詞字符組成的單詞,而第二個由于是使用了反向引用,那么它就必須是兩個重復單詞字符組成的單詞。
最后一個我使用了兩個分組,根據分組規則可知\w{3}\d{2}是第一個分組,\d{2}是第二個分組。 同樣注意:反向引用的是同樣的字符,如www55www5566,最后兩位不同,這就無法正確匹配了。
使用指定命名(也就是自定義命名)的反向引用
對于上面的第二個例子,我們用自定義命名的反向引用可以寫成\b(?<myName>\w)\k<myName>\b或者是\b(? 'myName' \w)\k<myName>\b。 本想舉例試一下,結果都提示錯誤,可能是上面提到的兩個在線網站不支持吧~
當然,如果我們希望只是將之看作一個整體,而不希望給其編號,可以使用(?:expression)的方式。如下所示:

另外,下面幾個也是常用的分組:
(?=expression)匹配字符串expression前面的位置
(?!expression)匹配后面不是字符串expression的位置
(?<=expression)匹配字符串expresssion后面的位置
(?<!expression)匹配前面不是字符串expression的位置
(?>expression)只匹配字符串expression一次
之前介紹的^和$都是匹配的一個滿足一定條件的位置。這里把滿足的一個條件成為斷言或零寬度斷言。
常用的有:
^ 匹配行的開始位置
$ 匹配行的結束位置
\A 匹配必須出現在字符串的開頭
\Z 匹配必須出現在字符串的結尾或字符串結尾處的\換行符好n之前
\z 匹配必須出現在字符串的結尾
\G 匹配必須出現在上一個匹配結束的地方
\b 匹配字符的開始或結束位置
\B 匹配不是在字符的開始或結束位置
之前所提到的(?=expression)、(?!expression)、(?<=expression)、(?<!expression)也都是匹配一個位置。
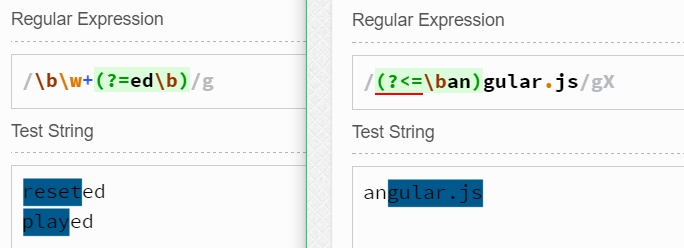
其中(?=expression)稱為零寬度預測先行斷言,它斷言自身位置的后面能夠匹配表達式expression。如\b\w+(?=ed\b)可以匹配以字符串ed結尾的單詞的前面部分,如reseted中的reset。
其中(?<=expression)又稱為零寬度正回顧后發斷言,它斷言自身位置的前面能夠匹配表達式expression。如(?<=\ban)\w+\b可以匹配除字符串an之外的部分。
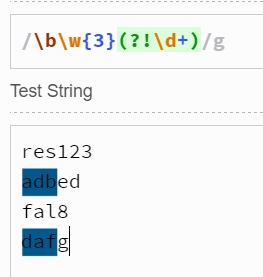
(?!expression)稱為負向零寬度斷言,即斷言自身位置的后面不能匹配字符串expression。
如\b\w{3}(?!\d)匹配的是后面不是數字的以三個單詞字符開頭的三個單詞字符。如下所示:
正則表達式中存在元字符、轉義符、限定符、|等運算或表達式。在匹配過程中,正則表達式都事先規定了這些運算或表達式的優先級。正則表達式也可以像數學表達式一樣來求值。也就是說,正則表達式可以從左到右、并按照一個給定的優先級來求值。
優先級順序表(優先級由高到低)如下:
轉義符:\
圓括號和方括號:()、(?:)、(?=)、[]
限定符: *、+、?、{n}、{n,}、{n,m}
位置和順序:^、$、\(元字符)
或運算:|
我們可以看到或運算的優先級是最低的。
我們可以通過下面的正則表達式來精確匹配windows運算系統的名稱
windows\s*((95)|(98)|(2000)|(2003)|(ME)|(XP)|(7)|(8)|(10))
這樣就可以精準匹配windows的各種版本的運算系統了,顯然這個是非常冗長的,我們還可以用一種不精準的方式匹配,如下所示:
windows\s*\w+
其中s*表示至少重復0次。即windows10(無空格), windows 10(一個空格), windows 10(兩個空格)等都可以正確匹配。
HTML標記一般由尖括號包圍,如<a>、<table>、<input>等等。所以我們可以使用下面的正則表達式來匹配HTML標記。
<[a-zA-Z][^>]*>

以上就是正則表達式用法是怎么樣的,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





