溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Java NIO Buffer實現原理是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
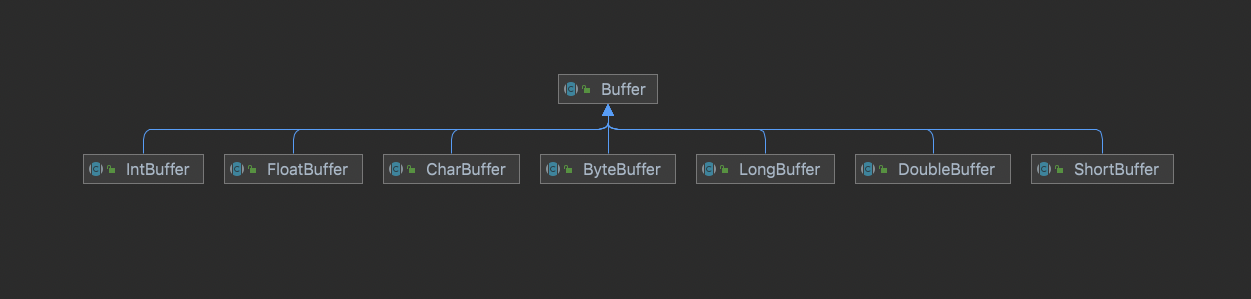
如上圖所示,對于Java中的所有基本類型,都會有一個具體的Buffer類型與之對應,一般我們最經常使用的是ByteBuffer。
舉一個IntBuffer的使用案例:
/**
* @author csp
* @date 2021-11-26 3:51 下午
*/
public class IntBufferDemo {
public static void main(String[] args) {
// 分配新的int緩沖區,參數為緩沖區容量。
// 新緩沖區的當前位置為0,其界限(限制位置)為其容量。它具有一個底層實現數組,其數組偏移量為0。
IntBuffer buffer = IntBuffer.allocate(8);
for (int i = 0; i < buffer.capacity(); i++) {
int j = 2 * (i + 1);
// 將給定整數寫入此緩沖區的當前位置,當前位置遞增。
buffer.put(j);
}
// 重設此緩沖區,將限制位置設置為當前位置,然后將當前位置設置為0。
buffer.flip();
// 查看在當前位置和限制位置之間是否有元素:
while (buffer.hasRemaining()){
// 讀取此緩沖區當前位置的整數,然后當前位置遞增。
int j = buffer.get();
System.out.print(j + " ");
}
}
}運行結果:
2 4 6 8 10 12 14 16
從該案例中可以看出,其實本質上這里就是把IntBuffer看作成一個數組容器使用,可以通過get方法向容器中讀取數據(put方法向容器中寫入數據)。
Buffer緩沖區本質上就是一個特殊類型的數組對象,與普通數組不同的地方在于,其內置了一些機制,能夠跟蹤和記錄緩沖區的狀態變化情況,如果我們使用get()方法從緩沖區獲取數據或者使用put()方法把數據寫入緩沖區,都會引起緩沖區狀態的變化。
Buffer內置數組實現狀態變化與追蹤的原理,本質上是通過三個字段變量實現的:
position:指定下一個將要被寫入或者讀取的元素索引,它的值由get()/put()方法自動更新,在新創建一個Buffer對象時,position被初始化為0。
limit:指定還有多少數據需要取出(在從緩沖區寫入通道時),或者還有多少空間可以放入數據(在從通道讀入緩沖區時)。
capacity:指定了可以存儲在緩沖區中的最大數據容量,實際上,它指定了底層數組的大小,或者至少是指定了準許我們 使用的底層數組的容量。
源碼如下:
public abstract class Buffer {
// 三個字段屬性之間的數值關系:0 <= position <= limit <= capacity
private int position = 0;
private int limit;
private int capacity;
...
}如果我們創建一個新的容量大小為10的ByteBuffer對象,在初始化的時候,position設置為0,limit和 capacity設置為10,在以后使用ByteBuffer對象過程中,capacity的值不會再發生變化,而其他兩個將會隨著使用而變化。
我們來看一個例子:
準備一個txt文檔,存放在項目目錄下,文檔中輸入以下內容:
Java
我們用一段代碼來驗證position、limit和capacity這三個值的變 化過程,代碼如下:
/**
* @author csp
* @date 2021-11-26 4:09 下午
*/
public class BufferDemo {
public static void main(String[] args) throws IOException {
FileInputStream fileInputStream = new FileInputStream("/Users/csp/IdeaProjects/netty-study/test.txt");
// 創建文件的操作管道
FileChannel channel = fileInputStream.getChannel();
// 分配一個容量為10的緩沖區(本質上就是一個容量為10的byte數組)
ByteBuffer buffer = ByteBuffer.allocate(10);
output("初始化", buffer);
channel.read(buffer);// 從管道將數據讀取到buffer容器中
output("調用read()", buffer);
// 準備操作之前,先鎖定操作范圍:
buffer.flip();
output("調用flip()", buffer);
// 判斷有沒有可讀數據
while (buffer.remaining() > 0){
byte b = buffer.get();
}
output("調用get()", buffer);
// 可以理解為解鎖
buffer.clear();
output("調用clear()", buffer);
// 最后把管道關閉
fileInputStream.close();
}
/**
* 將緩沖區里的實時狀態打印出來
*
* @param step
* @param buffer
*/
public static void output(String step, Buffer buffer) {
System.out.println(step + " : ");
// 容量(數組大小):
System.out.print("capacity" + buffer.capacity() + " , ");
// 當前操作數據所在的位置,也可以叫做游標:
System.out.print("position" + buffer.position() + " , ");
// 鎖定值,flip,數據操作范圍索引只能在 position - limit 之間:
System.out.println("limit" + buffer.limit());
System.out.println();
}
}輸出結果如下:
初始化 :
capacity10 , position0 , limit10
調用read() :
capacity10 , position4 , limit10
調用flip() :
capacity10 , position0 , limit4
調用get() :
capacity10 , position4 , limit4
調用clear() :
capacity10 , position0 , limit10
下面我們來對上面代碼的執行結果進行圖解分析(圍繞position、limit、capacity三個字段值):
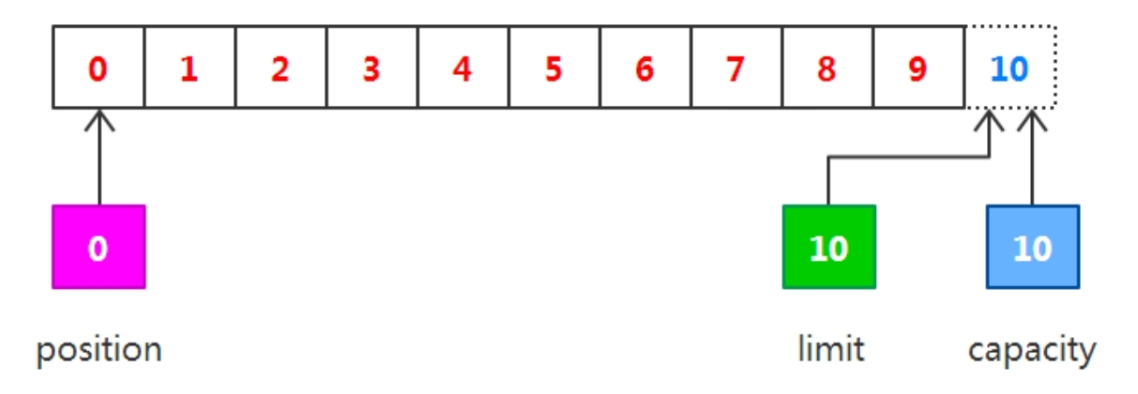
// 分配一個容量為10的緩沖區(本質上就是一個容量為10的byte數組)
ByteBuffer buffer = ByteBuffer.allocate(10);
// 從管道將數據讀取到buffer容器中
channel.read(buffer);
output("調用read()", buffer);首先從通道中讀取一些數據到緩沖區中(注意從通道讀取數據,相當于往緩沖區寫入數據)。如果讀取4個字節的數據,則此時 position的值為4,即下一個將要被寫入的字節索引為4,而limit仍然是10,如下圖所示。
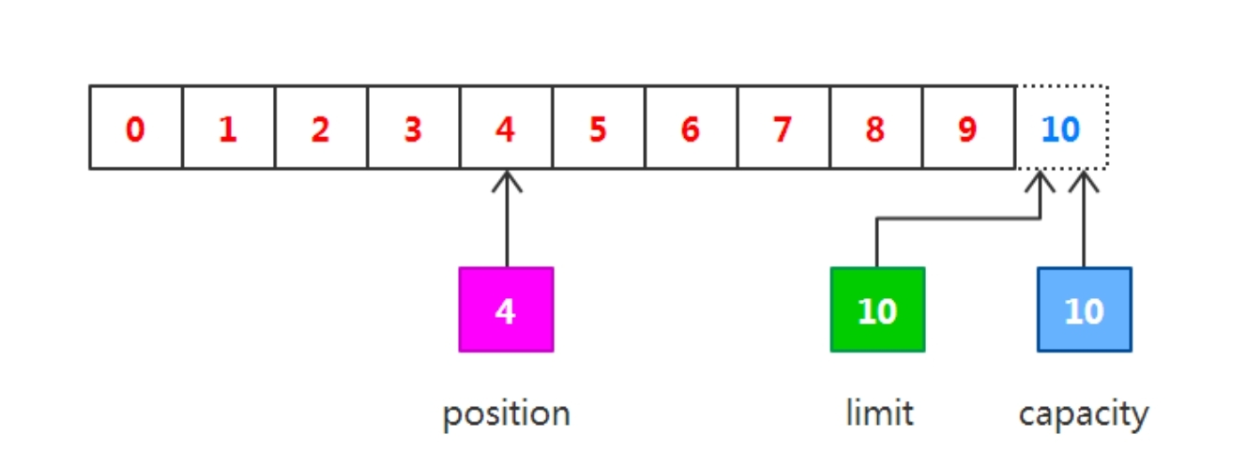
// 準備操作之前,先鎖定操作范圍:
buffer.flip();
output("調用flip()", buffer);下一步把讀取的數據寫入輸出通道,相當于從緩沖區中讀取數據,在此之前,必須調用flip()方法。該方法將會完成以下兩件事情:
一是把limit設置為當前的position值。
二是把position設置為 0。
由于position被設置為0,所以可以保證在下一步輸出時讀取的是緩沖區的第一個字節,而limit被設置為當前的position,可以保證讀取的數據正好是之前寫入緩沖區的數據,如下圖所示。
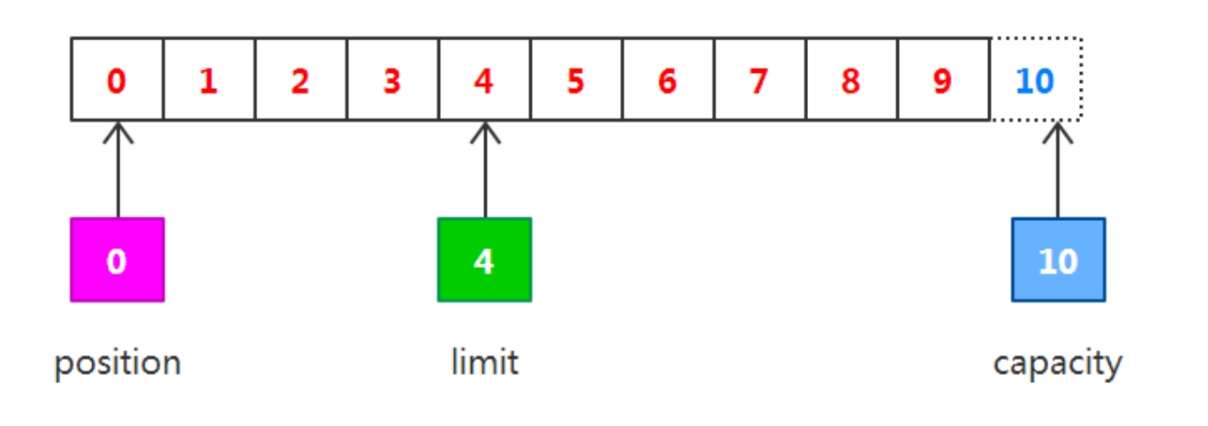
// 判斷有沒有可讀數據
while (buffer.remaining() > 0){
byte b = buffer.get();
}
output("調用get()", buffer);調用get()方法從緩沖區中讀取數據寫入輸出通道,這會導致 position的增加而limit保持不變,但position不會超過limit的值, 所以在讀取之前寫入緩沖區的4字節之后,position和limit的值都為 4,如下圖所示。
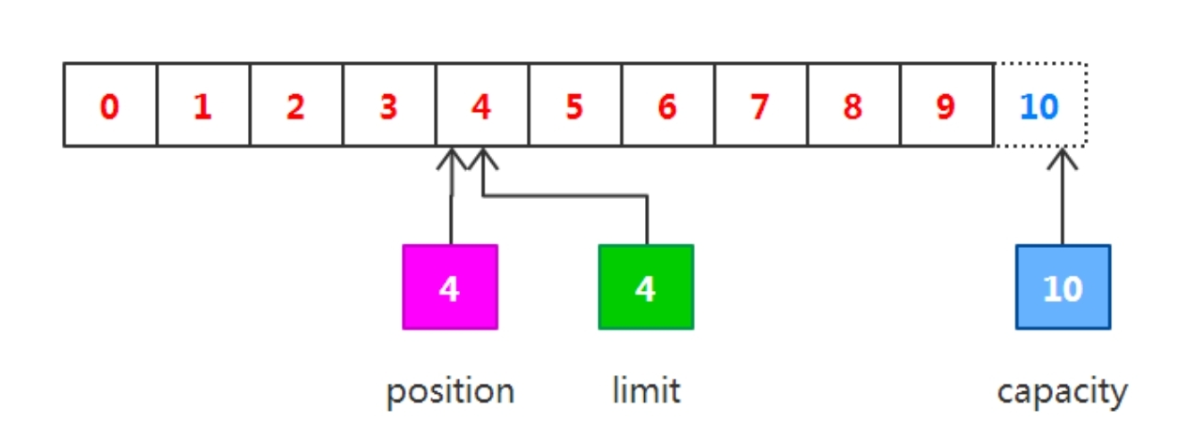
// 可以理解為解鎖
buffer.clear();
output("調用clear()", buffer);
// 最后把管道關閉
fileInputStream.close();在從緩沖區中讀取數據完畢后,limit的值仍然保持在調用flip()方法時的值,調用clear()方法能夠把所有的狀態變化設置為初始化時的值,最后關閉流,如下圖所示。
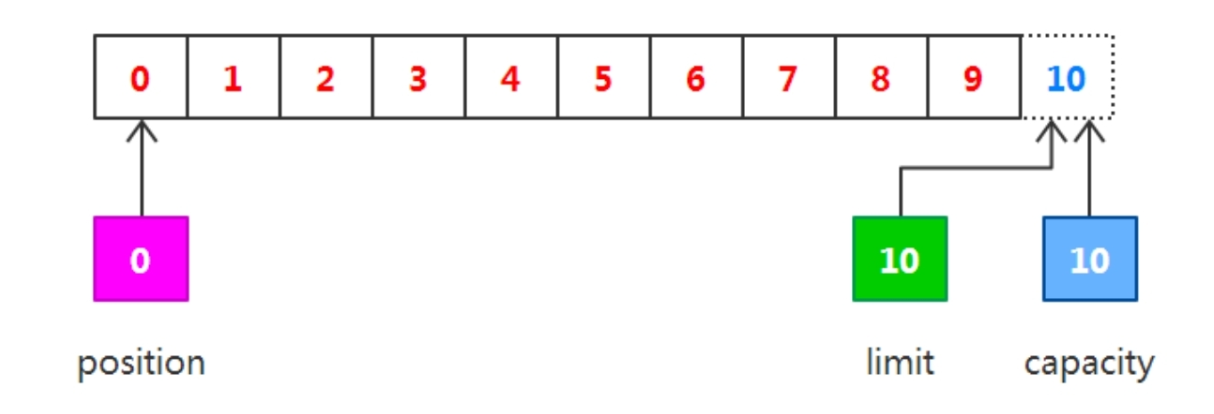
通過上述案例,更能突出Buffer是一個特殊的數組容器,與普通數組區別就在于其內置三個 “指針變量”:position、limit、capacity 用于跟蹤和記錄緩沖區的狀態變化情況!
在創建一個緩沖區對象時,會調用靜態方法allocate()來指定緩沖區的容量,其實調用allocate()方法相當于創建了一個指定大小的數組,并把它包裝為緩沖區對象。
allocate()源碼如下:
// 位于ByteBuffer下
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
// 新建一個ByteBuffer數組對象,容量為:capacity,limit參數值為:capacity
return new HeapByteBuffer(capacity, capacity);
}
// 位于HeapByteBuffer下,父類為:ByteBuffer
HeapByteBuffer(int cap, int lim) {
super(-1, 0, lim, cap, new byte[cap], 0);// 調用ByteBuffer的有參構造函數
}
// 位于ByteBuffer下,父類為:Buffer
ByteBuffer(int mark, int pos, int lim, int cap,
byte[] hb, int offset){
super(mark, pos, lim, cap);// 調用 Buffer構造函數
this.hb = hb;// final byte[] hb; 不可變的byte數組
this.offset = offset;// 偏移量
}
// Buffer構造函數
Buffer(int mark, int pos, int lim, int cap) {
if (cap < 0)
throw new IllegalArgumentException("Negative capacity: " + cap);
this.capacity = cap;// 數組容量
limit(lim);// 數組的了limit
position(pos);// 數組的positio
if (mark >= 0) {
if (mark > pos)
throw new IllegalArgumentException("mark > position: ("
+ mark + " > " + pos + ")");
this.mark = mark;
}
}本質上等同于如下代碼:
// 初始化一個byte數組 byte[] bytes = new byte[10]; // 將該數組包裝給ByteBuffer ByteBuffer buffer = ByteBuffer.wrap(bytes);
Java NIO中,可以根據先用的緩沖區Buffer對象創建一個子緩沖區。即,在現有緩沖區上切出一片作為一個新的緩沖區,但現有的緩沖區與創建的子緩沖區在底層數組層面上是數據共享的。
示例代碼如下所示:
/**
* @author csp
* @date 2021-11-28 6:20 下午
*/
public class BufferSlice {
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(10);
// 向緩沖區中put數據: 0~9
for (int i = 0; i < buffer.capacity(); i++) {
buffer.put((byte) i);
}
// 創建子緩沖區:即從數組下標為3的位置到下標為7的位置
buffer.position(3);
buffer.limit(7);
ByteBuffer slice = buffer.slice();
// 改變子緩沖區的內容
for (int i = 0; i < slice.capacity(); i++) {
byte b = slice.get(i);
b *= 10;
slice.put(i, b);
}
// position和limit恢復到初始位置:
buffer.position(0);
buffer.limit(buffer.capacity());
// 輸出buffer容器中的內容:
while (buffer.hasRemaining()) {
System.out.println(buffer.get());
}
}
}在該示例中,分配了一個容量大小為10的緩沖區,并在其中放入 了數據0~9,而在該緩沖區基礎上又創建了一個子緩沖區,并改變子緩沖區中的內容,從最后輸出的結果來看,只有子緩沖區“可見的” 那部分數據發生了變化,并且說明子緩沖區與原緩沖區是數據共享 的,輸出結果如下所示:
0
1
2
30
40
50
60
7
8
9
只讀緩沖區,顧名思義就是只可以從緩沖區中讀取數據,而不可以向其中寫入數據。
將現有緩沖區讓其調用asReadOnlyBuffer()方法,使其轉換成只讀緩沖區。這個方法返回一個與原緩沖區完全相同的緩沖區,并與原緩沖區共享數據,只不過它是只讀的。如果原緩沖區的 內容發生了變化,只讀緩沖區的內容也隨之發生變化。
示例代碼如下所示:
/**
* @author csp
* @date 2021-11-28 6:33 下午
*/
public class ReadOnlyBuffer {
public static void main(String[] args) {
// 初始化一個容量為10的緩沖區
ByteBuffer buffer = ByteBuffer.allocate(10);
// 向緩沖區中put數據: 0~9
for (int i = 0; i < buffer.capacity(); i++) {
buffer.put((byte) i);
}
// 將該緩沖區轉變為只讀緩沖區
ByteBuffer readOnlyBuffer = buffer.asReadOnlyBuffer();
// 由于buffer和readOnlyBuffer本質上共享一個byte[]數組對象,
// 所以,改變buffer緩沖區的內容時,會導致只讀緩沖區readOnlyBuffer的內容也隨著改變。
for (int i = 0; i < buffer.capacity(); i++) {
byte b = buffer.get(i);
b *= 10;
buffer.put(i, b);
}
// position和limit恢復到初始位置:
readOnlyBuffer.position(0);
readOnlyBuffer.limit(buffer.capacity());
// 輸出readOnlyBuffer容器中的內容:
while (readOnlyBuffer.hasRemaining()) {
System.out.println(readOnlyBuffer.get());
}
}
}輸出結果如下:
0
10
20
30
40
50
60
70
80
90
如果嘗試修改只讀緩沖區的內容,則會報 ReadOnlyBufferException異常。只可以把常規緩沖區轉換為只讀緩沖區,而不能將只讀緩沖區轉換為 可寫的緩沖區。
參考文章:Java NIO學習篇之直接緩沖區和非直接緩沖區
對于直接緩沖區的定義,《深入理解Java虛擬機》這本書是這樣介紹的:
Java NIO字節緩沖區(ByteBuffer)要么是直接的,要么是非直接的。如果為直接字節緩沖區,則java虛擬機會盡最大努力直接在此緩沖區上執行本機的IO操作,也就是說,在每次調用基礎操作系統的一個本機IO操作前后,虛擬機都會盡量避免將內核緩沖區內容復制到用戶進程緩沖區中,或者反過來,盡量避免從用戶進程緩沖區復制到內核緩沖區中。
直接緩沖區可以通過調用該緩沖區類的allocateDirect(int capacity) 方法創建,此方法返回的緩沖區進行分配和取消分配所需的成本要高于非直接緩沖區。直接緩沖區的內容駐留在垃圾回收堆之外,因此他們對應用程序內存(JVM內存)需求不大。所以建議直接緩沖區要分配給那些大型,持久(就是緩沖區的數據會被重復利用)的緩沖區,一般情況下,最好僅在直接緩沖區能在程序性能帶來非常明顯的好處時才分配它們。
直接緩沖區還可以通過FileCHannel的map()方法將文件區域映射到內存中來創建,該方法返回MappedByteBuffer。Java平臺的實現有助于通過JNI本地代碼創建直接字節緩沖區,如果以上這些緩沖區中某個緩沖區實例指向的是不可訪問的內存區域,則試圖方法該區域不會更改緩沖區的內容,并且會在訪問期間或者稍后的某個時間導致報出不確定性異常。
字節緩沖區是直接緩沖區還是非直接緩沖區可以通過調用其isDIrect()方法來判斷。
案例代碼:
/**
* @author csp
* @date 2021-11-28 7:07 下午
*/
public class DirectBuffer {
public static void main(String[] args) throws IOException {
// 從磁盤中讀取test.txt文件內容
FileInputStream fileInputStream = new FileInputStream("/Users/csp/IdeaProjects/netty-study/test.txt");
// 創建文件的操作管道
FileChannel inputStreamChannel = fileInputStream.getChannel();
// 把讀取的內容寫入到新的文件中
FileOutputStream fileOutputStream = new FileOutputStream("/Users/csp/IdeaProjects/netty-study/test2.txt");
FileChannel outputStreamChannel = fileOutputStream.getChannel();
// 創建直接緩沖區
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024);
while (true){
byteBuffer.clear();
int read = inputStreamChannel.read(byteBuffer);
if (read == -1){
break;
}
byteBuffer.flip();
outputStreamChannel.write(byteBuffer);
}
}
}要分配 直接緩沖區,需要調用allocateDirect()方法,而不是allocate()方 法,使用方式與普通緩沖區并無區別。
內存映射是一種讀和寫文件數據的方法,可以比常規的基于流或者基于通道的I/O快得多。內存映射文件I/O通過使文件中的數據表現為內存數組的內容來完成,這初聽起來似乎不過就是將整個文件讀到內存中,但事實上并不是這樣的。一般來說,只有文件中實際讀取或 寫入的部分才會映射到內存中。來看下面的示例代碼:
/**
* @author csp
* @date 2021-11-28 7:16 下午
*/
public class MapperBuffer {
static private final int start = 0;
static private final int size = 10;
public static void main(String[] args) throws IOException {
RandomAccessFile randomAccessFile = new RandomAccessFile("/Users/csp/IdeaProjects/netty-study/test.txt", "rw");
FileChannel channel = randomAccessFile.getChannel();
// 把緩沖區跟文件系統進行一個映射關聯,只要操作緩沖區里面的內容,文件內容也會隨之改變
MappedByteBuffer mappedByteBuffer = channel.map(FileChannel.MapMode.READ_WRITE, start, size);
mappedByteBuffer.put(4, (byte) 97);// a
mappedByteBuffer.put(5, (byte) 122);// z
randomAccessFile.close();
}
}原來test.txt文件內容為:
Java
執行完上述代碼之后,test.txt文件內容更新為:
Javaaz
“Java NIO Buffer實現原理是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





