溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Python通過跳板機訪問數據庫的方法是什么”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Python通過跳板機訪問數據庫的方法是什么”吧!
跳板機(Jump Server):也稱堡壘機,是一類可作為跳板批量操作的遠程設備的網絡設備,是系統管理員和運維人員常用的操作平臺之一。
那么具體是做什么的呢?
現在一些比較大的互聯網企業,往往擁有大量的服務器,為了能夠統一方便管理,運維人員通過跳板機去管理對應的服務器。我們在訪問服務器的時候,先通過登陸跳板機,然后再進入相應服務器。從一定程度上提升了服務器的數據安全性,也提升了服務器的可維護性。
跳板機的本質還是ssh連接,通過paramiko 自己造輪子的話理論也是可以實現的,這邊推薦 sshtunnel 這個包,省的自己寫了。
理解了跳板機的原理,這邊的配置就比較好理解了。拿這張圖舉例,首先需要先訪問跳板機,其實就是最常見的ssh連接,可以是賬戶密碼,也可以是密鑰登錄的,如果是密鑰的話需要在 跳板機的.ssh 目錄下的某個許可文件中添加上自己的公鑰
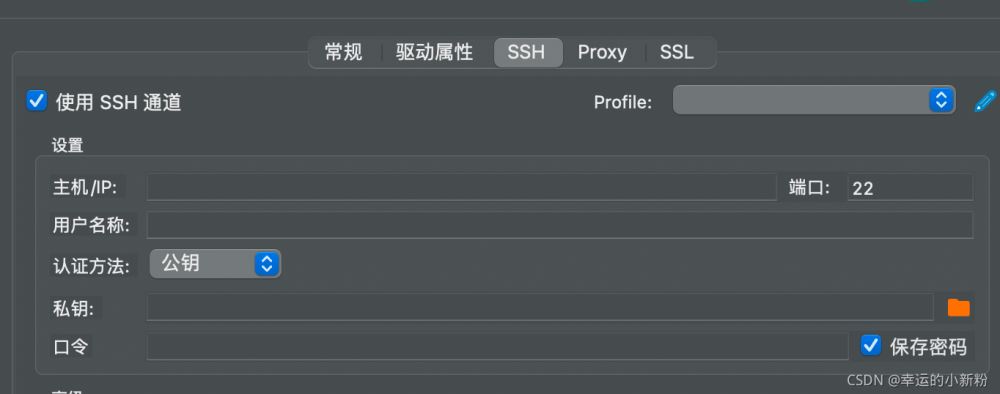
最后還需要補充一下 目標主機的ip 和端口。理解了這些,以下的這些參數就知道怎么配置了,
local_bind_address 可以不配置,不配置會隨機獲取本地的端口號,如果指定的話就會占用本地固定的端口號,推薦配置這一參數。
填寫本地的端口是因為這邊會將目標服務器ip的端口映射為本地端口,然后訪問本地端口就能實現目標端口的訪問了。
from sshtunnel import SSHTunnelForwarder server = SSHTunnelForwarder( (host_jump, int(port_jump)), # 跳板機的配置 ssh_pkey=ssh_pk_jump, #密鑰的訪問方式,如果是密碼 ssh_password=??? ssh_username=user_name_jump, remote_bind_address=(host_mysql, int(port_mysql))) # 數據庫服務器的配置 local_bind_address=(local_ip, local_port) # 開啟本地轉發端口 ) server.start() server.close()
有些人習慣用 上下文管理器,看起來更舒服些
from sshtunnel import SSHTunnelForwarder with SSHTunnelForwarder( (host_jump, int(port_jump)), # 跳板機的配置 ssh_pkey=ssh_pk_jump, #密鑰的訪問方式,如果是密碼 ssh_password=??? ssh_username=user_name_jump, remote_bind_address=(host_mysql, int(port_mysql))) # 數據庫服務器的配置 local_bind_address=(local_ip, local_port) # 開啟本地轉發端口 )as server server.start()
建立好通道后就能通過本地映射的端口訪問目標的數據庫端口了。
常見的mysql 數據庫訪問 比如 mysqldb,pymysql,mysql.connector,
mysqldb跟 pymysql 差不多,只不過前者適用python2的版本,后者適用python3的版本,mysql.connector是官方推薦的。
pymysql 跟 mysql.connector 還是有一些區別的
我這邊使用的是 mysql.connector ,在實踐中老是無法連接上,而pymysql卻是可以的。
最終終于找到了解決辦法。。。
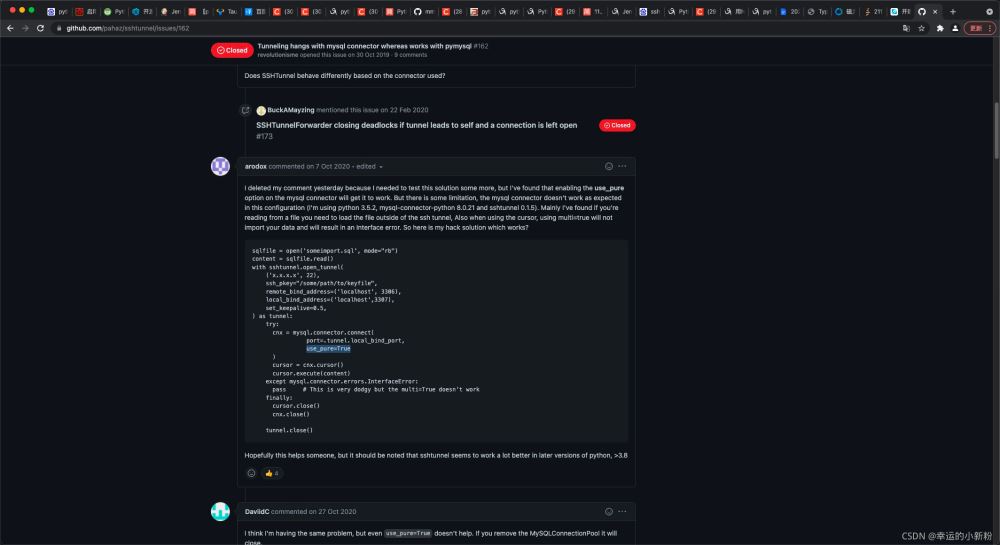
以下是我的mysql.connector 連接數據庫的樣例。
with SSHTunnelForwarder(
(host_jump, int(port_jump)), # 跳板機的配置
ssh_pkey=ssh_pk_jump,
#密鑰的訪問方式,如果是密碼 ssh_password=???
ssh_username=user_name_jump,
remote_bind_address=(host_mysql, int(port_mysql))) # 數據庫服務器的配置
local_bind_address=(local_ip, local_port) # 開啟本地轉發端口
)as server
server.start()
conn = mysql.connector.connect(**{'host': '127.0.0.1',
'port': server.local_bind_port,
'user': dbcfg["user"],
'password': dbcfg["password"],
'db': dbcfg["db"],
'charset': dbcfg["charset"],
'collation': dbcfg["collation"],
'use_unicode': dbcfg["use_unicode"],
'use_pure': True})
cursor = conn.cursor(dictionary=True)
cursor.execute(sql, params)
rows = cursor.fetchall()
# conn.commit()
cursor.close()
conn.close()這樣,數據庫就能正常訪問啦
首先,就上面這樣的代碼而言,在每次查詢都需要進行跳板機的連接,對于短時間突然大量請求的情況,這種是效率極低的。所以最好是能夠將建立管道保存下來。
其次,如果同時訪問多種數據庫的情況,存在有無跳板機的場景,所以最好能夠先將所有的數據庫都進行連接,將conn保存在字典中,根據要訪問的機器調用對應的conn,最后再統一釋放。
def get_slave_conn_byProxy(dbcfg):
server = SSHTunnelForwarder(
eval(dbcfg["addr"]),
ssh_username=dbcfg["ssh_username"],
ssh_pkey=os.getenv("HOME") + "/.ssh/id_rsa",
remote_bind_address=eval(dbcfg["remote_bind_address"]),
local_bind_address=eval(dbcfg["local_bind_address"]) # 開啟本地轉發端口
)
server.start()
conn = get_db_connection({'host': '127.0.0.1',
'port': server.local_bind_port,
'user': dbcfg["user"],
'password': dbcfg["password"],
'db': dbcfg["db"],
'charset': dbcfg["charset"],
'collation': dbcfg["collation"],
'use_unicode': dbcfg["use_unicode"],
'use_pure': True})
return server, conn
def get_db_connection(dbcfg):
# logger.info(f"============ debug db config: {dbcfg}")
conn = mysql.connector.connect(**dbcfg)
return conn
# 通過輸入的連接參數判斷是否需要通過跳板機的方式
def get_slave_conn(dbcfg):
if "addr" in dbcfg:
return get_slave_conn_byProxy(dbcfg)
else:
conn = get_db_connection(dbcfg)
return None, conn
def read_slave_db_data(sql, conn, params=None, use_pdf=True):
cursor = conn.cursor(dictionary=True)
cursor.execute(sql, params)
rows = cursor.fetchall()
# conn.commit()
cursor.close()
if use_pdf:
return pd.DataFrame(rows)
else:
return rows到此,相信大家對“Python通過跳板機訪問數據庫的方法是什么”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





