溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
namenode的文件存儲
namenode數據存儲分為兩個文件,fsp_w_picpath與edits文件,edits文件記錄了所有namenode的操作,相當于日志記錄。fsp_w_picpath記錄了namenode的數據。在namenode啟動時,會加載fsp_w_picpath的數據到內存中,并從edits文件中解析所有數據信息到內存,兩個數據合并后共同組成了namenode全量信息。
secondarynamenode的作用
secondarynamenode 按一定規則將edits文件和fsp_w_picpath文件合并,合并后namenode會啟用新的edits文件,這樣會減小edits文件的文件大小,控制edits文件的大小會減少namenode在啟動階段解析加載edits文件的時長。
secondarynamenode合并文件規則
配置 fs.checkpoint.period 執行檢查點合并文件檢查時間 默認3600s
fs.checkpoint.size 實行檢查點合并文件閥值大小 默認64M
兩個條件滿足其一則合并文件
工作原理示意圖
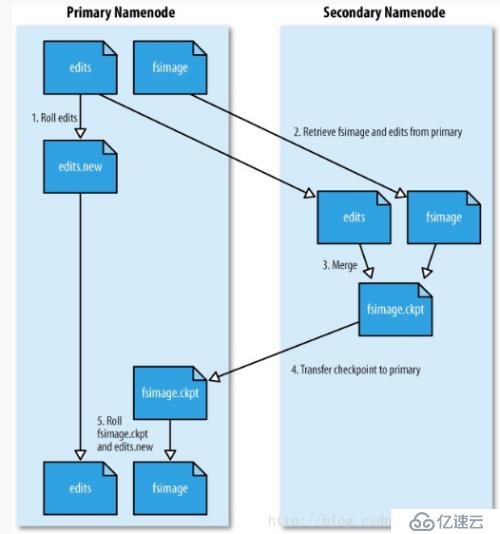
架構分析
fsp_w_picpath與edits文件對于namenode存儲數據有什么區別,為什么要分開兩個文件進行存儲?
fsp_w_picpath存儲著所有目錄和文件的序列化信息,而edits保存了所有寫或更新的信息,在namenode運行過程中只向edits文件中寫相關的操作信息和文件信息
分兩個文件存儲是因為fsp_w_picpath由于保存了所有namenode的信息,所以文件大小通常比較大,這樣在一個大的文件中進行寫操作比較費系統資源而且延遲了系統的反應時間,而edits文件由于有secondarynamenode進行合并,通常大小要小于fsp_w_picpath,所以在edits文件中進行更新寫操作會降低系統資源的消耗。
為什么會引入sencondarynamenode,只用namenode會有什么問題?
由于namenode進行分文件保存,但又不能使edits文件過大,所以需要進行文件合并,但進行文件合并會占用系統內存等資源,如果直接使用namenode進行文件合并,會導致在合并文件期間,系統文件管理能力下降卡頓等。另外由于secondarynamenode與namenode進行分離,可以將namenode和secondarynamenode分開部署到不同機器上,提高系統的穩定與安全性。除此之外,secondarynamenode由于進行了檢查點,在namenode完全宕機數據丟失的情況下,secondarynamenode可以在檢查點上恢復系統數據,當然,也會造成檢查點之后的數據丟失。
-----史龍剛
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





