溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Hadoop這個名字現在對很多開發者來說,并不陌生,但是很多開發者對其工作原理和架構并不了解。Hadoop怎么實現的分布式存儲和分布式計算,其計算性能為什么會提高那么多。本文將從其基本工作原理方面解釋上上述問題,博主是初學者,不喜勿噴,還請前輩多多指教。
一、Hadoop名字的起源
大家在網上搜索Hadoop關鍵字的時候,出現的圖片絕大多數是一頭可愛的***的小象,很多人并不理解這個分布式平臺和小象有什么關系。Hadoop是Apache公司對Google GFS(Google FileSystem)和MapReduce的開源實現,該項目組的負責人Doug Cutting后來解釋說,其實“Hadoop”這個詞并不在字典中,是一個虛擬的詞,源于他的小兒子,他的小兒子有一個***的小象玩具,并且叫這個玩具Hadoop(發音類似),Doug Cutting覺得這個很有意思,簡單的拼寫,容易本人記住,并且不容易被用在別處,也沒有其他的意義,非常合適作為這個開源項目的名字,于是這個名字就被用上了,***小象也成了Hadoop的代名詞。
二、Hadoop是什么
首先了解一下什么是分布式計算,所謂的分布式計算,既是說把一個很負責計算或者一個計算量很大計算,拆分成由很多小型的計算同時進行,提高計算的效率,縮小時間成本。他是和集中式計算想對應的,分布式計算往往和計算機集群聯系在一起,比較依賴計算資源。Hadoop比較官方的說法是,Hadoop是一個由Apache基金會所開發的分布式系統基礎架構(百度百科)。簡單的說,Hadoop就是分布式系統架構中的一款產品,也是其中功能實現比較齊全、使用最方便和最廣泛的一款產品。
Hadoop主要是實現了分布式文件系統(HDFS)及其對應分布式計算模型MapReduce。Hadoop可以部署在廉價的機器上,并且能保證高容錯性,計算機集群又能保證高數據吞吐量,并且能充分利用MapReduce分布式計算模型實現大批量數據計算,使得很多企業越來越傾向于使用Hadoop來開發自己的產品。
三、Hadoop的架構
從Hadoop本身來說,如上述,Hadoop主要由兩部分組成,分布式文件系統HDFS和分布式計算模型MapReduce,HDFS位于Hadoop的底層,主要提供文獻存儲功能,其上層是MapReduce,其數據計算來源主要是HDFS中的數據,計算完成的輸出結果往往也會保存到HDFS中,也可以保存在本地,這個后面會詳細介紹。
HDFS
從用戶client的角度來說,HDFS就像是一個普通的文件系統,和Linux系統中的文件系統功能很相似,其文件操作也和linux系統的文件操作命令類似,所以,熟悉linux的朋友不會對Hadoop陌生,操作簡介方便這也是Hadoop被開發者廣泛接受的原因之一。
但是從系統的角度來說,并不是那么簡單,HDFS由很多臺服務器共同組成,多臺服務器共同完成分布式存儲功能。文件數據在其中是以block的方式存儲的,每一個block的大小默認是64M(可以修改配置更改),既是說一個大文件在存儲時會被切割成64M大小的block,存儲在HDFS中,結尾不足64M的部分獨占一個block,并且每一個block都默認有三個備份(可以修改配置更改備份數量),即數據冗余。HDFS有很多優點:
易擴展:由于是部署在集群上的,所以其容量會隨著集群的擴張而擴展,如果配置高質量的集群管理,擴展到千萬結點上也很輕松。
(1)高吞吐量:由于其和集群的密切關系,并且擴展性非常好,所以HDFS可以很輕松的存儲T級別或者更大量的數據,只要集群裝得下。
(2)高可靠性:由于HDFS采用的數據冗余策略,每一個block都有備份,既是出現部分服務器宕機,也不會影響數據的完整性。
(3)高效性:由于其數據是分布式存儲的,并且block可以在結點之間快速移動,保持結點平衡,所以很高效的支持分布式計算。
(4)廉價:由于Hadoop的設計初衷就是在廉價的服務器上部署分布式計算,使得很多規模不大的小公司能夠承擔得起這方面的消費。
缺點:
HDFS不適合實時計算,其數據是一次寫入,多次讀取,并且數據訪問時間延遲比較大,其設計初衷是高吞吐量,所以就犧牲了實時性。
MapReduce
MapReduce是Hadoop的另外一個核心技術:分布式計算,其實非常簡單,就是利用HDFS分布式存儲的特點,在此基礎上在每一個block或者文件邏輯單元上建立一個子計算,犧牲計算空間來換取計算時間。其計算模型分為兩個步驟,即Map(映射)和Reduce(集合),Map部分為每一條數據建立一個<key, value>映射并進行簡單的計算,Reduce部分將Map的輸出結果收集起來,形成輸出。具體內容以后會詳細介紹。
從集群的角度來說,Hadoop是由NameNode,DataNode,SecondaryNameNode和Client組成,如下圖所示(圖片來源于百度百科):
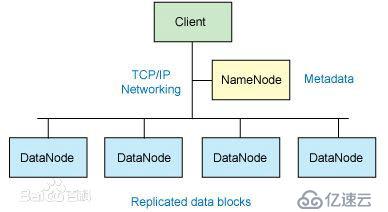
NameNode是Hadoop集群的主節點,也是集群的控制節點,SecondaryNameNode是二級主節點,可以理解為NameNode的備份,主節點掛掉時,SecondaryNameNode補上,作為主節點。主節點本身并不存儲大量數據,也不提供計算資源,只是為集群提供命名空間,其中保存的有文件映射,即Metadata,通過這種方式找到文件系統中的文件。DataNode是集群中的數據結點,用于保存大批量數據,和提供計算所需計算資源,MapReduce實際運行在DataNode中,NameNode只是控制作用。Client是客戶端。集群中通信是以TCP/IP的方式來完成的。
Hadoop的架構先介紹到這里,后面有需要會補充,謝謝!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





