溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇接著6.1 繼續講HBase。
4. Hbase容錯與恢復
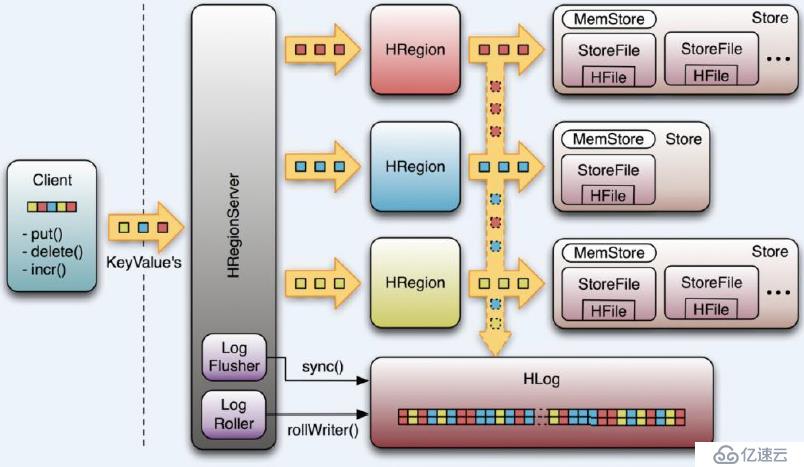
每個HRegionServer中都有一個HLog對象,HLog是一個實現Write Ahead Log的類,在每次用戶操作寫入MemStore的同時,也會寫一份數據到HLog文件中(HLog文件格式見后續),HLog文件定期會滾動出新的,并刪除舊的文件(已持久化到StoreFile中的數據)。當HRegionServer意外終止后,HMaster會通過Zookeeper感知到,HMaster首先會處理遺留的 HLog文件,將其中不同Region的Log數據進行拆分,分別放到相應region的目錄下,然后再將失效的region重新分配,領取到這些region的HRegionServer在Load Region的過程中,會發現有歷史HLog需要處理,因此會Replay HLog中的數據到MemStore中,然后flush到StoreFiles,完成數據恢復
Hbase容錯性:
1) Master容錯:Zookeeper重新選擇一個新的Master
l 無Master過程中,數據讀取仍照常進行;
l 無master過程中,region切分、負載均衡等無法進行;
2) RegionServer容錯:定時向Zookeeper匯報心跳,如果一旦時間內未出現心跳,Master將該RegionServer上的Region重新分配到其他RegionServer上,失效服務器上“預寫”日志由主服務器進行分割并派送給新的RegionServer
3) Zookeeper容錯:Zookeeper是一個可靠地服務,一般配置3或5個Zookeeper實例
Region定位流程:
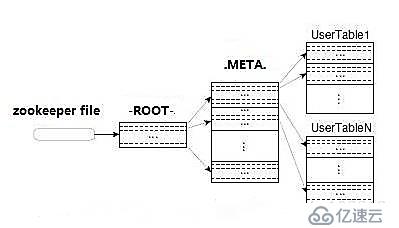
尋找RegionServer過程:ZooKeeper--> -ROOT-(單Region)--> .META.--> 用戶表
1) -ROOT-
l 表包含.META.表所在的region列表,該表只會有一個Region;
l Zookeeper中記錄了-ROOT-表的location。
2) .META.
l 表包含所有的用戶空間region列表,以及RegionServer的服務器地址。
1) 進入hbase shell console
$HBASE_HOME/bin/hbase shell |
表的管理:
2) 查看有哪些表
list |
3) 創建表
# 語法:create <table>, {NAME => <family>, VERSIONS => <VERSIONS>}
# 例如:創建表t1,有兩個family name:f1,f2,且版本數均為2 > create 't1',{NAME => 'f1', VERSIONS => 2},{NAME => 'f2', VERSIONS => 2} |
4) 刪除表
# 分兩步:首先disable,然后drop
# 例如:刪除表t1 > disable 't1' > drop 't1' |
5) 查看表的結構
# 語法:describe <table>
# 例如:查看表t1的結構 > describe 't1' |
6) 修改表結構
# 修改表結構必須先disable
# 語法:alter 't1', {NAME => 'f1'}, {NAME => 'f2', METHOD => 'delete'}
# 例如:修改表test1的cf的TTL為180天 > disable 'test1' > alter 'test1',{NAME=>'body',TTL=>'15552000'},{NAME=>'meta', TTL=>'15552000'} > enable 'test1' |
權限管理:
1) 分配權限
# 語法 : grant <user> <permissions> <table> <column family> <column qualifier> 參數后面用逗號分隔 # 權限用五個字母表示: "RWXCA". # READ('R'), WRITE('W'), EXEC('X'), CREATE('C'), ADMIN('A')
# 例如,給用戶‘test'分配對表t1有讀寫的權限, > grant 'test','RW','t1' |
2) 查看權限
# 語法:user_permission <table>
# 例如,查看表t1的權限列表 > user_permission 't1' |
3) 收回權限
# 與分配權限類似,語法:revoke <user> <table> <column family> <column qualifier>
# 例如,收回test用戶在表t1上的權限 > revoke 'test','t1' |
表數據的增刪改查:
1) 添加數據
# 語法:put <table>,<rowkey>,<family:column>,<value>,<timestamp>
# 例如:給表t1的添加一行記錄:rowkey是rowkey001,family name:f1,column name:col1,value:value01,timestamp:系統默認 > put 't1','rowkey001','f1:col1','value01' |
2) 查詢數據——查詢某行記錄
# 語法:get <table>,<rowkey>,[<family:column>,....]
# 例如:查詢表t1,rowkey001中的f1下的col1的值 > get 't1','rowkey001', 'f1:col1' # 或者: > get 't1','rowkey001', {COLUMN=>'f1:col1'}
# 查詢表t1,rowke002中的f1下的所有列值 hbase(main)> get 't1','rowkey001' |
3) 查詢數據——掃描表
# 語法:scan <table>, {COLUMNS => [ <family:column>,.... ], LIMIT => num} # 另外,還可以添加STARTROW、TIMERANGE和FITLER等高級功能
# 例如:掃描表t1的前5條數據 > scan 't1',{LIMIT=>5} |
4) 查詢表中的數據行數
# 語法:count <table>, {INTERVAL => intervalNum, CACHE => cacheNum} # INTERVAL設置多少行顯示一次及對應的rowkey,默認1000;CACHE每次去取的緩存區大小,默認是10,調整該參數可提高查詢速度
# 例如,查詢表t1中的行數,每100條顯示一次,緩存區為500 > count 't1', {INTERVAL => 100, CACHE => 500} |
5) 刪除數據——刪除行中的某個列值
# 語法:delete <table>, <rowkey>, <family:column> , <timestamp>,必須指定列名
# 例如:刪除表t1,rowkey001中的f1:col1的數據 > delete 't1','rowkey001','f1:col1' |
6) 刪除數據——刪除行
# 語法:deleteall <table>, <rowkey>, <family:column> , <timestamp>,可以不指定列名,刪除整行數據
# 例如:刪除表t1,rowk001的數據 > deleteall 't1','rowkey001' |
7) 刪除數據——刪除表中的所有數據
# 語法: truncate <table> # 其具體過程是:disable table -> drop table -> create table
# 例如:刪除表t1的所有數據 > truncate 't1' |
Region管理:
1) 移動Region
# 語法:move 'encodeRegionName', 'ServerName' # encodeRegionName指的regioName后面的編碼,ServerName指的是master-status的Region Servers列表
# 示例 >move '4343995a58be8e5bbc739', 'db-41.xxx.xxx.org,60020,139' |
2) 開啟/關閉region
# 語法:balance_switch true|false hbase(main)> balance_switch |
3) 手動split
# 語法:split 'regionName', 'splitKey' |
4) 手動觸發major compaction
#語法: #Compact all regions in a table: > major_compact 't1' #Compact an entire region: > major_compact 'r1' #Compact a single column family within a region: > major_compact 'r1', 'c1' #Compact a single column family within a table: > major_compact 't1', 'c1' |

此時你已經學會了安裝hadoop集群,了解了HDFS文件系統,MapReduce計算框架和Zookeeper協作服務(Zookeeper數據模型、訪問控制、應用場景),今天學完了HBase,下一篇我們介紹hadoop的數據庫工具——Hive。
如何用4個月學會Hadoop開發并找到年薪25萬工作?
免費分享一套17年最新Hadoop大數據教程和100道Hadoop大數據必會面試題。
因為鏈接經常被和諧,需要的朋友請加微信 ganshiyun666 來獲取最新下載鏈接,注明“51CTO”
教程已幫助300+人成功轉型Hadoop開發,90%起薪超過20K,工資比之前翻了一倍。
百度Hadoop核心架構師親自錄制
內容包括0基礎入門、Hadoop生態系統、真實商業項目實戰3大部分。其中商業案例可以讓你接觸真實的生產環境,訓練自己的開發能力。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





