溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下C++中內存模型和名稱空間的示例分析,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
和C語言一樣,C++允許甚至鼓勵程序員將組件放在獨立的文件中。可以單獨編譯這些文件,然后將它們連接成可執行程序。(通常,C++編譯器即編譯程序,也管理連接器)。如果只修改了一個文件,則可以只重新編譯該文件,然后將它與其他文件的編譯版本鏈接。這使得大程序的管理更便捷。
C++開發人員使用 #include 導入頭文件,與其將結構聲明加入到每一個文件中,不如將其放在頭文件中,然后在每一個源代碼文件中包含該頭文件。這樣,要修改結構聲明時,只需在頭文件中做一次改動即可。另外,可以將函數原型放在頭文件中。因此,可以將原來的程序分成三部分。
頭文件:包含結構聲明和使用這些結構的函數的原型
源代碼文件:包含與結構有關的函數的代碼
源代碼文件:包含調用與結構相關的函數的代碼
請不要將函數定義或變量聲明放到頭文件中。這樣做對簡單情況可能是可行的,但通常會引來麻煩。例如,如果在頭文件包含一個函數定義,然后在其他兩個文件中包含該頭文件,則同一個程序中將包含同一個函數的兩個定義,除非函數是內聯的,否則將會出錯。下面列出了頭文件中常包含的內容。
函數原型
使用#define或const定義的符號常量
結構聲明
類聲明
模板聲明
內聯函數
將結構聲明放在頭文件中是可以的,因為它們不創建變量,而只是在源代碼文件中聲明結構變量時,告訴編譯器如何創建該結構變量。同樣,模板聲明不是將被編譯的代碼,它們指示編譯器如果和生成與源代碼中的函數調用相匹配的函數定義。被聲明為const的數據和內聯函數有特殊的鏈接屬性,因此可以將其放在頭文件中,而不會引起問題。
頭文件管理
在同一個文件中只能將同一個頭文件包含一次。有一種標準的C/C++技術可以避免多次包含同一個頭文件。它是基于預處理器編譯指令 #ifndef (即 if not defined)的。下面代碼片段意味著僅當以前沒有使用預處理器編譯指令#define定義名稱COORDIN_H_時,才處理 #ifndef 和 #endif之間的語句:
#ifndef COORDIN_H_ ... #endif
通常,使用#define語句來創建符號常量,如下所示:
#define MAXIMUM 4096
但只要將#define用于名稱,就足以完成該名稱的定義,如下所示:
#ifndef COORDIN_H_ #define COORDIN_H_ // place include file contents here #endif
多個庫的鏈接
C++標準允許每個編譯器設計人員以他認為合適的方式實現名稱修飾,因此由不同編譯器創建的二進制模塊(對象代碼文件)很可能無法正確地鏈接。也就是說,兩個編譯器將為同一個函數生成不同的修飾名稱。名稱的不同將使鏈接器無法將一個編譯器生成的函數調用與另一個編譯器生成的函數定義匹配。在鏈接編譯模塊時,請確保所有對象文件或庫都是由同一個編譯器生成的。如有源代碼,通常可以用自己的編譯器重新編譯源代碼來消除鏈接錯誤。
接下來擴展存儲類別如何影響信息在文件間的共享。C++使用三種(在C++11中是四種)不同的方案來存儲數據,這些方案的區別就在于數據保留在內存中的時間。
自動存儲持續性:在函數定義中聲明的變量(包括函數參數)的存儲持續性為自動的。它們在程序開始執行其所屬的函數或代碼塊時被創建,在執行完函數或代碼塊時,它們使用的內存被釋放。C++有兩種存儲持續性為自動的變量。
靜態存儲持續性:在函數定義外定義的變量和使用關鍵字static定義的變量的存儲持續性都為靜態。它們在程序整個運行過程中都存在。C++有3中存儲持續性為靜態的變量。
線程存儲持續性:當前,多核處理器很常見,這些CPU可同時處理多個執行任務。這讓程序能夠將計算放在可并行處理的不同線程中。如果變量是使用關鍵字thread_local聲明的,則其聲明周期與所屬的線程一樣長。
動態存儲持續性:用new運算符分配的內存將一直存在,直到使用delete運算符將其釋放或程序結束為止。這種內存的存儲持續性為動態,有時被稱為自由存儲或堆。
作用域描述了名稱在文件的多大范圍內可見。例如,函數中定義的變量可在該函數中使用,但不能在其他函數中使用;而在文件中的函數定義之前定義的變量則可在所有函數中使用。鏈接性(linkage)描述了名稱如何在不同單元間共享。鏈接性為外部的名稱可在文件間共享,鏈接性為內部的名稱只能由一個文件中的函數共享。自動變量的名稱沒有鏈接性,因為它們不能共享。
C++變量的作用域有多種。作用域為局部的變量只在定義它的代碼塊中可用,代碼塊是由花括號括起的一系列語句。
C++函數的作用域可以是整個類或整個名稱空間(包括全局的),但不能是局部的(因為不能在代碼塊內定義的函數,如果函數的作用域為局部,則只對它自己是可見的,因此不能被其他函數調用。這樣的函數將無法運行)。
默認情況下,在函數中聲明的函數參數和變量的存儲持續性為自動,作用域為局部,沒有鏈接性。也就是說,如果main()中聲明了一個名為texas的變量,并在函數oil()中也聲明了一個名稱texas的變量,則創建了兩個獨立的變量——只有在定義他們的函數中才能使用它們。堆iol()的texas執行的任何操作都不會影響main()中的texas,反之亦然。另外,當程序開始執行這些變量所屬的代碼塊時,將為其分配內存;當函數結束時,這些變量都將消失。
使用C++11中的auto
在C++11中,關鍵字auto用于自動類型推斷。但在C語言和以前的C++版本中,auto的含義截然不同,它用于顯式地指出變量為自動存儲:
int froob(int n)
{
auto float ford; //ford has automatic stroage
...
}由于只能將關鍵字用于默認為自動的變量,因此程序員幾乎不使用它。它的主要用途是指出當前變量為局部自動變量。在C++11中,這種用法不再合法。
1,自動變量的初始化
可以使用任何在聲明時其值已知的表達式來初始化自動變量,下面的示例初始化變量x,y,z:
int w; int x=5; int big =INT_MAX -1; int y=x *x; int y=2*x; cin>>w; int z=3*w;
2,自動變量的初始化
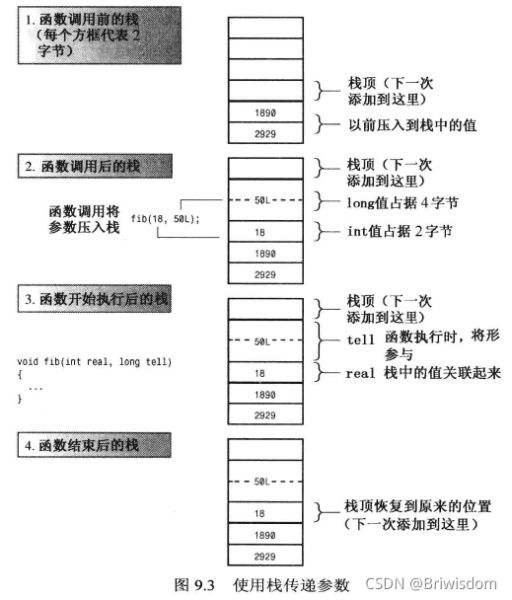
了解典型的C++編譯器如何實現自動變量有助于更深入地了解自動變量。由于自動變量的數目隨函數的開始和結束而增減,因此程序必須在運行時對自動變量進行管理。常用的方法是留出一段內存,并將其視為棧,以管理變量的增減。之所以被稱為棧,是由于新數據被象征性地放在原有數據的上面(也就是說,在相鄰的內存單元中,而不是在同一個內存單元中),當程序使用完后,將其從棧中刪除。棧的默認長度取決于實現,但編譯器通常提供改變棧長度的選項。程序使用兩個指針來跟蹤棧,一個指針指向棧底——棧的開始位置,另一個指針指向堆頂——下一個可用內存單元。當函數被調用時,其自動變量被加入到棧中,棧頂指針指向變量后面的下一個可用的內存單元。函數結束時,棧頂指針被重置為函數被調用前的值,從而釋放新變量使用的內存。
棧時LIFO(后進先出)的,即最后加入到棧中的變量首先被彈出。這種設計簡化了參數傳遞。函數調用將其參數的值放在棧頂,然后重新設置棧頂指針。被調用的函數根據其形參描述來確定每個參數的地址。下圖中,函數fib()被調用時,傳遞一個2字節的int和一個4字節的long。這些值被加入到棧中。當fib()開始執行時,它將real和tell同這兩個值關聯起來。當fib()結束時,棧頂指針重新指向以前的位置。新值沒有被刪除,但不再被標記,它們所占據的空間將被下一個將值加入到棧中的函數調用所使用。
3,寄存器變量
關鍵字register最初是由C語言引入的,它建議編譯器使用CPU寄存器來存儲自動變量:
register int count_fast; //request for a rregister variable
這旨在提高訪問變量的速度。
在C++11之前,這個關鍵字在C++中的用法始終未變,只是隨著硬件和編譯器變得越來越復雜,這種提示表明變量用的很多,編譯器可以對其做特殊處理。在C++11中,這種提示作用也失去了,編輯案子register只是顯式地指出變量是自動的。鑒于關鍵字register只能用于原本就是自動的變量,使用它唯一的原因是,指出程序員想使用一個自動變量,這個變量的名稱可能與外部變量相同。這與auto以前的用途完全相同。然而,保留關鍵字register的重要原因是,避免使用了該關鍵字的現有代碼非法。
和C語言一樣,C++也為靜態存儲持續性變量提供了3種鏈接性:外部鏈接性(可在其他文件中訪問)、內部鏈接性(只能在當前文件中訪問)和無鏈接性(只能在當前函數或代碼塊中訪問)。這3種鏈接性都在整個程序執行期間存在,與自動變量相比,它們的壽命更長。由于靜態變量的數目在程序運行期間是不變的,因此程序不需要使用特殊的裝置(如棧)來管理它們。編譯器將分配固定的內存塊來存儲所有的靜態變量,這些變量在整個程序執行期間一直存在。另外,如果沒有顯式地初始化靜態變量,編譯器將把它設置為0。在默認情況下,靜態數組和結構將每個元素或成員的所有位都設置為0。
創建外部靜態持續變量,在代碼塊外面聲明它;
創建內部的靜態持續變量,在代碼塊的外面聲明它,并使用static限定符;
創建無鏈接的靜態持續變量,在代碼塊中聲明它,并使用static限定符。
...
int global =1000; // static duration, external linkage
static int one_file =50; //static duration, internal linkage
int main()
{
...
}
void funct1(int n)
{
static int count =0; // static duration, no linkage
int llama =0;
}所有的靜態持續變量都有下述初始化特征: 未被初始化的靜態變量的所有位都被設置為0。這種變量稱為零初始化的(zero-initialized)。
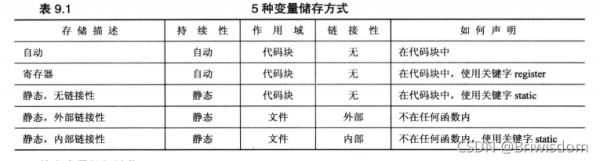
下表9.1總結了引入名稱空間之前使用的初始化特征。指出了關鍵字static的兩種用法,但含義有些不同:用于局部聲明,以指出變量是無鏈接性的靜態變量,static表示的是存儲持續性;而用于代碼塊外的聲明時,static表示內部鏈接性,而變量已經是靜態持續性了。有人稱之為關鍵字重載,即關鍵字的含義取決于上下文。
鏈接性為外部的變量通常稱為外部變量,它們的存儲持續性為靜態,作用域為整個文件。外部變量是在函數外部定義的,因此對所有函數而言都是外部的。例如,可以在main()前面或頭文件中定義它們。可以在文件中位于外部變量定義后面的任何函數中使用它,因此外部變量也稱為全局變量。
1,單定義規則
一方面,在每個使用外部變量的文件中,都必須聲明它;另一方面,C++有“單定義規則”(One Definition Rule, ODR), 該規則指出,變量只能有一次定義。為滿足這種需求,C++提供了兩種變量聲明。一種是定義聲明或簡稱定義,它給變量分配存儲空間;另一種是引用聲明或簡稱聲明,它不給變量分配存儲空間,因為它引用已有的變量。
引用聲明使用關鍵字extern,且不進行初始化;否則,聲明為定義,導致分配存儲空間。
double up; //definition, up is 0; extern int blem; //blem defined elsewhere extern char gr ='z'; //definition because initialized
如果要在多個文件中使用外部變量,只需在一個文件中包含該變量的定義(單定義規則),但在使用變量的其他所有文件中,都必須使用關鍵字extern聲明它。
全局變量和局部變量
既然可以選擇使用全局變量或局部變量,那么到底應使用哪種呢?首先,全局變量很有吸引力——因為所有的函數能訪問全局變量,因此不用傳遞參數。但易于訪問的代價很大——程序不可靠。計算經驗表明,程序越能避免對數據進行不必要的訪問,就越能保持數據的完整性。通常情況下,應使用局部變量,應在需要知曉時才傳遞數據,而不應不加區分地使用全局變量來使數據可用。
將static限定符用于作用域為整個文件的變量時,該變量的鏈接性將為內部的。在多文件程序中,內部鏈接性和外部鏈接性之間的差別很有意義。鏈接性為內部的變量只能在其所屬的文件中使用,但常規外部變量都具有外部鏈接性,即可以在其他文件中使用。
可使用外部變量在多文件程序的不同部分之間共享數據;可使用鏈接性為內部的靜態變量在同一個文件中的多個函數之間共享數據(名稱空間提供了另外一種共享數據的方法)。另外,如果將作用域為整個文件的變量變為靜態的,就不必擔心其名稱與其他文件中的作用域為整個文件的變量發生沖突。
無鏈接性的局部變量是這樣創建的,將static限定符用于在代碼塊中定義的變量。在代碼塊中使用static時,將導致局部變量的存儲持續性為靜態的。這意味著雖然該變量只在該代碼塊中可用,但它在該代碼塊不處于活動狀態時仍然存在。因此在兩次函數調用之間,靜態局部變量的值將保持不變。(靜態變量適用于再生)。另外,如果初始化了靜態局部變量,則程序只在啟動時進行一次初始化。以后再調用函數時,將不會像自動變量那樣再次被初始化。
有些被稱為存儲說明符或cv-限定符的C++關鍵字提供了其他有關存儲的信息。下面是存儲說明符:
auto(在C++11中不再是說明符)
register;
static
extern
thread_local(C++11新增的)
mutable
其中的大部分已經介紹過了,在同一個聲明中不能使用多個說明符,但thread_local除外,它可與static或extern結合使用。前面講過,在C++11之前,可以在聲明中使用關鍵字auto指出變量為自動變量;但在C++11中,auto用于自動類型推斷。關鍵字register用于在聲明中指示寄存器存儲,而在C++11中,它只是顯式地指出變量是自動的。關鍵字static被用在作用域為整個文件的聲明中時,表示內部鏈接性;被用于局部聲明中,表示局部變量的存儲持續性為靜態的。關鍵字extern表明是引用聲明,即聲明在其他地方定義的變量。關鍵字thread_local指出變量的持續性與其所屬線程的持續性相同。thread_local變量之于線程,猶如常規靜態變量之于整個程序。關鍵字mutable的含義將根據const來解釋,因此先來介紹cv-限定符,然后再解釋它。
1. cv-限定符
下面就是cv限定符
const
volatile
const是常見的cv-限定符,它表明,內存被初始化后,程序便不能再對它進行修改。
關鍵字volatile表明,即使程序代碼沒有對內存單元進行修改,其值也可能發生變化。聽起來似乎很神秘,實際上并非如此。例如,可以將一個指針指向某個硬件位置,其中包含了來自串行端口的時間或信息。在這種情況下,硬件(而不是程序)可能修改其中的內容。或者兩個程序可能互相影響,共享數據。該關鍵字的作用是改善編譯器的優化能力。例如,假設編譯器發現,程序在幾條語句中兩次使用了某個變量的值,則編譯器可能不是讓程序查找這個值兩次,而是將這個值緩存到寄存器中。這種優化假設變量的值在這兩次使用之間不會變化。如果不將變量聲明為volatile,則編譯器將進行這種優化,將變量聲明為volatile,相當于告訴編譯器,不要進行這種優化。
2. mutable
現在回到mutable。可以用它來指出,即使結構(或類)變量為const。其某個成員也可以被修改。例如:
struct data
{
char name[30];
mutable int accesses;
...
};
const data veep = {"Claybourne Clodde",0, ...};
strcpy(veep.name, "Joye Joux"); //not allowed
veep.accesses++; //allowedveep的const限定符禁止程序修改veep的成員,但access成員的mutable說明符使得access不受這種限制。
3. 再談const
在C++(但不是在C語言)中,const限定符對默認存儲類型稍有影響。在默認情況下全局變量的鏈接性為外部的,但const全局變量的鏈接性為內部的,也就是說,在C++看來,全局const定義就像使用了static說明符一樣
const int fingers =10; //same as static const int fingers =10;
int main(void)
{
...
}C ++修改了常量類型的規則,讓程序員更輕松。例如,假設將一組常量放在頭文件中,并在同一個程序的多個文件中使用該頭文件。那么預處理器將頭文件的內容包含到每個源文件中,所有的源文件都將包含類似下面的定義:
const int finers =10; const char * warning ="Wak!";
如果全局const聲明的鏈接性像常規變量那樣是外部的,則根據單定義規則,這將出錯。也就是說,只能有一個文件可以包含前面的聲明,而其他文件必須使用extern關鍵字來提供引用聲明。另外,只有使用extern關鍵字的聲明才能進行初始化:
//extern would be required if ocnst had external linkage extern const int fingers; //can't be initialized extern const char *warning;
因此,需要為某個文件使用一組定義,而其他文件使用另一組聲明。然而,由于外部定義const數據的鏈接性為內部的,因此可以在所有文件中使用相同的聲明。
內部鏈接性還意味著,每個文件都有自己的一組常量,而不是所有文件共享一組常量。每個定義都是其所屬文件私有的,這就是能夠將常量定義放在頭文件中的原因。這樣,只要在兩個源代碼文件中包括同一個頭文件,則他們將獲得同一組常量。
如果出于某種原因,程序員希望某個常量的鏈接性為外部的,則可以使用extern關鍵字來覆蓋默認的內部鏈接性。
在函數或代碼塊中聲明const時,其作用域為代碼塊,即僅當程序執行該代碼塊中的代碼時,該常量才是可用的。這意味著在函數或代碼塊中創建常量時,不必擔心其名稱與其他地方定義的常量發生沖突。
和變量一樣,函數也有鏈接性,雖然可選擇的范圍比變量小。和C語言一樣,C++不允許在一個函數中定義另外一個函數,因此所有的存儲持續性都自動為靜態的,即在整個程序執行期間都一直存在。在默認情況下,函數的鏈接性為外部的,即可以在文件間共享。
實際上,可在函數原型中使用關鍵字extern來指出函數是在另一個文件中定義的,不過這是可選的(要讓程序在另一個文件中查找函數,該文件必須作為程序的組成部分被編譯,或者是由鏈接程序搜索的庫文件)。還可以使用關鍵字static將函數的鏈接性設置為內部的,使之只能在一個文件中使用。必須同時在原型和函數定義中使用該關鍵字。
static int private(double x);
...
static int private(double x)
{
...
}這意味著該函數只在這個文件中課件,還意味著可以在其他文件中定義同名的函數。和變量一樣,在定義靜態函數的文件中,靜態函數將覆蓋外部定義,因此即使在外部定義了同名的函數,該文件仍將用靜態函數。
單定義規則也適用于非內聯函數,因此對于每個非內聯函數,程序只能包含一個定義,對于鏈接性為外部的函數來說,這意味著在多文件程序中,只能有一個文件(該文件可能是庫文件,而不是您提供的)包含該函數的定義,但使用該函數的每個文件都應包含其函數原型。
內聯函數不受這項規則的約束,這允許程序員能夠將內聯函數的定義放在頭文件中。這樣,包含了頭文件的每個文件都有內聯函數的定義。然而,C++要求同一個函數的所有內聯定義都必須相同。
另一種形式的鏈接性——稱為語言鏈接性也對函數有影響。鏈接程序要求每個不同的函數都有不同的符號名。在C語言中,一個名稱只對應一個函數,因此這很容易實現。為滿足內部需求,C語言編譯器可能將spiff這樣的函數名翻譯為 _spiff。這種方法被稱為C原因鏈接性。但在C++中,同一個名稱可能對應多個函數,必須將這些函數翻譯為不同的符號名稱。因此,C++編譯器執行名稱矯正或名稱修飾,為重載函數生成不同的符號名稱。例如,可能將spiff(int)轉換為_spoff_i,而將spiff(double, double)轉換為_spiff_d_d。這種方法被稱為C++語言鏈接。
鏈接程序尋找與C++函數調用匹配的函數時,使用的方法與C語言不同。但如果要在C++程序中使用C庫中預編譯的函數,將出現什么情況呢?例如,假設有下面的代碼:
spiff(22); //want spiff(int) from a C library
它在C庫文件中的符號名稱為_spiff, 但對于我們假設的鏈接程序來說,C++查詢約定時查找符號名稱 _spiff_i。為解決這種問題,可以用函數原型來指出要使用的約定:
extern "C" void spiff(int); //use C protocol for name look-up extern void spoff(int); //use C++ protocol for name look-up extern "C++" void spaff(int); //use C++ protocol for name look-up
第一個原型使用C語言鏈接性;而后面的兩個使用C++語言鏈接性。第二個原型是通過默認方式指出這一點的,而第三個顯式地指出了這一點。
C和C++鏈接性是C++標準制定的說明符,但實現可提供其他語言鏈接性說明符。
前面介紹C++用來為變量(包括數組和結構)分配內存的5種方案(線程內存除外),他們不適用于使用C++運算符new(或C函數malloc())分配的內存,這種內存被稱為動態內存。動態內存運算符由new和delete控制,而不是由作用域和鏈接性規則控制。因此,可以在一個函數中分配動態內存,而在另一個函數中將其釋放。與自動內存不同,動態內存不是LIFO,其分配和釋放順序要取決于new和delete在何時以何種方式被使用。通常,編譯器使用三塊獨立的內存:一塊用于靜態變量,一塊用于自動變量,另外一塊用于動態存儲。
雖然存儲方案概念不適用于動態內存,但適用于用來跟蹤動態內存的自動和靜態指針變量。例如,假設在一個函數中包含下面的語句:
float * p_free =new float [20];
由new分配的80個字節(假設float為4個字節)的內存將一直保留在內存中,直到使用delete運算符將其釋放。但當包含該聲明語句塊執行完畢時,p_fees指針將消失。如果希望另一個函數能夠使用這80個字節的內存,則必須將其地址傳遞或返回給該函數。另一方面,如果將p_fees的鏈接性聲明為外部的,則文件中位于該聲明后面的所有函數都可以使用它。另外,通過在另一個文件中使用下述聲明,便可在其中使用該指針:
extern float * p_fees;
1. 使用new運算符初始化
如果要初始化動態分配的變量,該如何辦呢?在C++98中,有時候可以這樣做,C++11增加了其他可能性。
如果要為內置的標量類型(如int或double)分配存儲空間并初始化,可在類型名后面加上初始值,并將其用括號括起:
int *pi =new int(6); double * pd =new double (99.99);
這種括號語法也有可用于構造函數的類,這將在本書后面介紹。
然而,要初始化常規結構或數組,需要使用大括號的列表初始化,這要求編譯器支持C++11。C++11允許您這樣做:
struct where {double x; double y; double z;};
where * one =new where {2.5, 5.3, 7.2}; //C++11
int * ar =new int [4] {2,4,6,7}; //C++11在C++11中,還可將列表初始化用于單值變量:
int *pin =new int {};
double *pdo= new double {99.99};2. new 失敗時
new可能找不到請求的內存量。在最初10年中,C++在這種情況下讓new返回空指針,但現在將引發一場std::bad_alloc。
3. new: 運算符、函數和替換函數
運算符new和new[]分別調用如下函數:
void * operator new(std::size_t); //used by new void * operator new[] (std:: size_t) //used by new[]
這些函數被稱為分配函數,他們位于全局名稱空間中。同樣也有delete和delete[]調用的釋放函數:
void operator delete(void *); void operator delete [](void *);
4. 定位new運算符
通常,new負責在堆中找到一個足以能夠滿足要求的內存塊。new運算符還有另一種變體,被稱為定位new運算符,它讓您能夠指定要使用的位置。程序員可能使用這種特性來設置其內存管理規程、處理需要通過特定地址進行訪問的硬件或在特定位置創建對象。
要使用定位new特性,首先需要包含頭文件new,它提供了這種版本的new運算符的原型;然后將new運算符用于提供了所需地址的參數。除需要指定參數外,句法與常規new運算符相同。具體地說,使用定位new運算符,變量后面可以有方括號,也可以沒有。下面演示了new運算符的4種用法:
#include <new>
struct chaff
{
char dross[20];
int slag;
} ;
char buffer1[50];
int *p3, *p4;
//first, the regular forms of new
p1 = new chaff; //place structure in heap
p3 = new int [20]; // place int array in heap
//now, the two forms of placement new
p2 = new (buffer1) chaff; //place structure in buffer1
p4 = new (buffer2) int[20]; //place int array in buffer2
...出于簡化的目的,這個示例使用兩個靜態數組來為定位new運算符提供內存空間。因此,上述代碼從buffer1中分配空間給結構chaff, 從buffer2中分配空間給一個包含20個元素的int數組。
C++中,名稱可以是變量、函數、結構、枚舉。類以及類和結構的成員。當隨著項目的增大,名稱相互沖突的可能性也將增加。使用多個廠商的類庫時,可能導致名稱沖突。例如,兩個庫可能都定義了名稱為List、Tree和Node的類,但定義的方式不兼容。用戶可能希望使用一個庫的List類,而使用另一個庫的Tree類。這種沖突被稱為名稱空間問題。
C++標準提供了名稱空間工具,以便更好地控制名稱的作用域。經過了一段時間后,編譯器才支持名稱空間,但現在這種支持很普遍。
介紹C++中新增的名稱空間特性之前,先復習一下C++中已有的名稱空間屬性,以及概念。
聲明區域。聲明區域是可以在其中進行聲明的區域。例如,可以在函數外面聲明全局變量,對于這種變量,其聲明區域為其所在的文件。對于在函數中聲明的變量,其聲明區域為其聲明所在的代碼塊。
潛在作用域。變量的潛在作用域從聲明點開始,到其聲明區域的結尾。因此潛在作用域比聲明區域小,這是由于變量必須定義后才能使用。
然而,變量并非在其潛在作用域內的任何位置都是可見的。例如,它可能被另一個嵌套聲明區域中聲明的同名變量隱藏。例如,在函數中聲明的局部變量將隱藏在同一個文件中聲明的全局變量。變量對程序而言可見的范圍被稱為作用域。
C++關于全局變量和局部變量的規則定義了一種名稱空間層次。每個聲明區域都可以聲明名稱,這些名稱獨立于在其他聲明區域中聲明的名稱。在一個函數中聲明的局部變量不會與在另一個函數中聲明的局部變量發生沖突。
C++新增了這樣一種功能,即通過定義一種新的聲明區域來創建命名的名稱空間,這樣做得目的之一是提供一個聲明名稱的區域。一個名稱空間中的名稱不會與另外一個名稱空間的相同名稱發生沖突,同時允許程序的其他部分使用該名稱空間中聲明的東西。
名稱空間可以是全局的,也可以位于另一個名稱空間中,但不能位于代碼塊中。因此,在默認情況下,在名稱空間中聲明的名稱的鏈接性為外部的。
除了用戶定義的名稱空間外,還存在另一個名稱空間——全局名稱空間。它對應于文件級聲明區域,因此前面所說的全局變量現在被描述為位于全局名稱空間中。
任何名稱空間中的名稱都不會與其他名稱空間中的名稱發生沖突。名稱空間中的聲明和定義規則同全局聲明和定義規則相同。
名稱空間是開放的,即可以把名稱空間加入到已有的名稱空間中。下面這條語句將名稱goose添加到Jill中已有的名稱列表中:
namespace Jill {
char * goose(const char *);
}同樣,原來的Jack名稱空間為fetch()函數提供了原型。可以在該文件后面(或另外一個文件中)再次使用Jack名稱空間來提供該函數的代碼:
namespace Jack{
void fetch()
{
...
}
}當然,需要有一種方法來訪問給定名稱空間中的名稱。最簡單的方法是,通過作用域解析運算符::,使用名稱空間來限定該名稱:
Jack:: pail =12.34; //use a variable Jill::Hill mole; //create a type Hill structure Jack::fetch(); //use a function
未被裝飾的名稱稱為未限定的名稱;包含名稱空間的名稱稱為限定的名稱。
1. using聲明和using編譯指令
C++提供兩種機制(using聲明和using編譯指令)來簡化對名稱空間中名稱的使用。using聲明使特定的標識符可用,using編譯指令使整個名稱空間可用。
using聲明由被限定的名稱和它前面的關鍵字using組成,using聲明將特定的名稱添加到它所屬的聲明區域中。
using聲明使一個名稱可用,而using編譯指令使所有的名稱都可用。using編譯指令由名稱空間名和它前面的關鍵字using namespace組成,它使名稱空間中的所有名稱都可用,而不需要使用作用域解析運算符。
在全局聲明區域中使用using編譯指令,將使該名稱空間的名稱全局可用。在函數中使用using 編譯指令,將使其中的名稱在該函數中可用。
2. using編譯指令和using聲明之比較
使用using編譯指令導入一個名稱空間中所有的名稱與使用多個using聲明使不一樣的,而更像是大量使用作用域解析運算符。使用using聲明時,就好像聲明了相應的名稱一樣。如果某個名稱已經在函數中聲明了,則不能用using聲明導入相同的名稱。然而,使用using編譯指令時,將進行名稱解析,就像在包含using聲明和名稱空間本身的最小聲明區域中聲明了名稱一樣。
注意:假設名稱空間和聲明區域定義了相同的名稱。如果試圖使用using聲明將名稱空間的名稱導入該聲明區域,則這兩個名稱會發生沖突,從而出錯。如果使用using編譯指令將該名稱空間的名稱導入該聲明區域,則局部版本將隱層名稱空間版本。
一般來說,使用using聲明比使用using編譯指令更安全,這是由于它只導入指定的名稱。如果該名稱與局部名稱發生沖突,編譯器將發出指示。using編譯指令導入所有名稱,包括可能并不需要的名稱。如果與局部名稱發生沖突,則局部名稱將覆蓋名稱空間版本,而編譯器并不會發出警告。另外,名稱空間的開放性意味著名稱空間的名稱可能分散在多個地方,這使得難以準確知道添加了哪些名稱。
3. 名稱空間的其他特性
可以將名稱空間聲明進行嵌套:
namespace elements
{
namespace fire
{
int flame;
...
}
float water;
}4. 未命名的名稱空間
可以通過省略名稱空間的名稱來創建未命名的名稱空間
namespace //unnamed namespace
{
int ice;
int bandycoot;
}這就像后面跟著using編譯指令一樣,也就是說,在該名稱空間中聲明的名稱潛在作用域為:從聲明點到該聲明區域末尾。從這個方面看,它們與全局變量相似。然而,由于這種名稱空間沒有名稱,因此不能顯式地使用using編譯指令或using聲明來使它在其他位置都可用。具體的說,不能在未命名名稱空間所屬文件之外的其他文件中,使用該名稱空間中的名稱。這提供了鏈接性為內部的靜態變量的替代品。
隨著程序員逐漸熟悉名稱空間,將出現統一的編程理念。下面是當前的一些指導原則。
使用在已命名的名稱空間中聲明的變量,而不是使用外部全局變量。
使用在已命名的名稱空間中聲明的變量,而不是使用靜態全局變量。
如果開發了一個函數庫或類庫,將其放在一個名稱空間中。事實上,C++當前提倡將標準函數庫放在名稱空間std中,這種做法擴展到了來自C語言中的函數。例如,頭文件math.h是與C語言兼容的,沒有使用名稱空間,但C++頭文件cmath應將各種數學庫函數放在名稱空間std中。實際上,并非所有的編譯器都完成了這種過渡。
僅將編譯指令using作為一種將舊代碼轉換為使用名稱空間的權宜之計。
不要在頭文件中使用using編譯指令。首先,這樣做掩蓋了要讓哪些名稱可用;另外,包含頭文件的順序可能影響程序的行為。如果非要使用編譯指令using,應將其放在所有預處理器編譯指令#include之后。
導入名稱時,首選使用作用域解析運算符或using聲明的方法。
對于using聲明,首選將其作用域設置為局部而不是全局。
使用名稱空間的主旨是簡化大型編程項目的管理工作。對于只有一個文件的簡單程序,使用using編譯指令并非什么大逆不道的事。
以上是“C++中內存模型和名稱空間的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





