溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“pandas怎么實現按照Series分組”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
1 按照一個Series進行分組
2 按照多個Series進行分組
3 分組和聚合采用不同的列或Series進行
本文用到的表格內容如下:
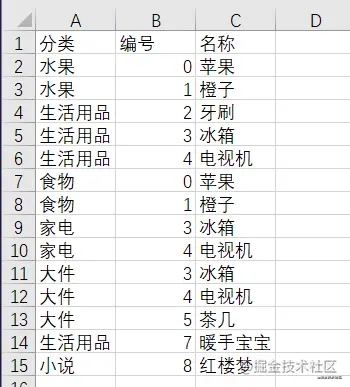
先來看一下數據情形
import pandas as pd life_df = pd.read_excel(r'C:\Users\admin\Desktop\生活用品表.xlsx') print(life_df)
result:
分類 編號 名稱
0 水果 0 蘋果
1 水果 1 橙子
2 生活用品 2 牙刷
3 生活用品 3 冰箱
4 生活用品 4 電視機
5 食物 0 蘋果
6 食物 1 橙子
7 家電 3 冰箱
8 家電 4 電視機
9 大件 3 冰箱
10 大件 4 電視機
11 大件 5 茶幾
12 生活用品 7 暖手寶寶
13 小說 8 紅樓夢
將DataFrame的其中一列取出來就是一個Series,比如life_df["分類"]就是一個Series
life_df = pd.read_excel(r'C:\Users\admin\Desktop\生活用品表.xlsx') print(life_df.groupby(life_df["分類"]))
result:
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001506806C6C8>
從上面的結果可以看出,如果只是傳入Series,分組后的結果是一個DataFrameGroupBy對象。這個對象包含著分組以后的若干組數據,但是沒有直接顯示出來,需要對這些分組數據進行匯總計算以后才會顯示出來
life_df = pd.read_excel(r'C:\Users\admin\Desktop\生活用品表.xlsx') print(life_df.groupby(life_df["分類"]).count())
result:
編號 名稱
分類
大件 3 3
家電 2 2
小說 1 1
水果 2 2
生活用品 4 4
食物 2 2
上面的代碼是根據物品分類對所有數據進行了分組,然后對分組以后的數據分別進行計數運算,最后進行合并。
由于對分組后的數據進行了計數運算,因此每一列都會有一個結果。但是如果對分組后的結果做一些數值運算,這個時候只有數據類型是數值(int、float)的列才會參與運算
import pandas as pd life_df = pd.read_excel(r'C:\Users\admin\Desktop\生活用品表.xlsx') print(life_df.groupby(life_df["分類"]).sum())
result:
編號
分類
大件 12
家電 7
小說 8
水果 1
生活用品 16
食物 1
我們把這種對分組后的數據進行匯總運算的操作稱為聚合,使用的函數稱為聚合函數。比如前面系列文章提高的非空值計數、sum求和、最大值最小值、均值、中位數、眾數、方差、標準差和分位數這些。都屬于聚合函數。
多Series分組和單Series分組差不多,只要將多個Series以列表的形式傳遞給groupby()即可。
life_df = pd.read_excel(r'C:\Users\admin\Desktop\生活用品表.xlsx') print(life_df.groupby([life_df["分類"], life_df["名稱"]]).count())
result:
編號
分類 名稱
大件 冰箱 1
電視機 1
茶幾 1
家電 冰箱 1
電視機 1
小說 紅樓夢 1
水果 橙子 1
蘋果 1
生活用品 冰箱 1
暖手寶寶 1
牙刷 1
電視機 1
食物 橙子 1
蘋果 1
life_df = pd.read_excel(r'C:\Users\admin\Desktop\生活用品表.xlsx') print(life_df.groupby([life_df["分類"], life_df["名稱"]]).sum())
result:
編號
分類 名稱
大件 冰箱 3
電視機 4
茶幾 5
家電 冰箱 3
電視機 4
小說 紅樓夢 8
水果 橙子 1
蘋果 0
生活用品 冰箱 3
暖手寶寶 7
牙刷 2
電視機 4
食物 橙子 1
蘋果 0
這里和按列分組的用法一致
life_df = pd.read_excel(r'C:\Users\admin\Desktop\生活用品表.xlsx') print(life_df.groupby(life_df["分類"])["名稱"].count())
result:
分類
大件 3
家電 2
小說 1
水果 2
生活用品 4
食物 2
Name: 名稱, dtype: int64
這里就是按照物品分類進行分組,再按照物品名稱進行匯總統計
“pandas怎么實現按照Series分組”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





