溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了python中如何使用pandas對多列進行分組統計,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
使用groupby([ ]).size()統計的結果,值相同的字段值會不顯示
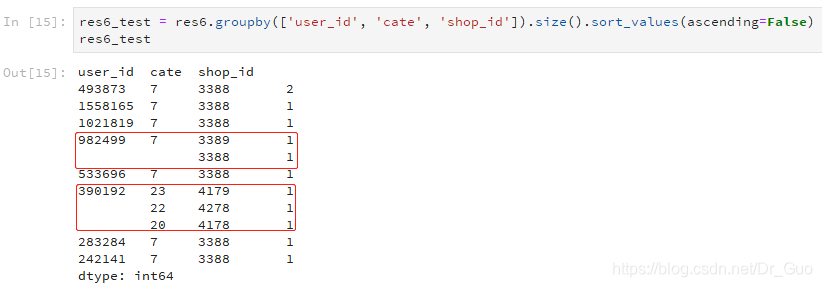
如上圖所示,第一個空著的行是982499 7 3388 1,因為此行與前面一行的這兩個字段值是一樣的,所以不顯示。第二個空著的行是390192 22 4278 1,因為此行與前面一行的第一個字段值是一樣的,所以不顯示。這樣的展示方式更直觀,但對于剛用的人,可能會讓其以為是缺失值。
如果還不明白可以看下面的全部數據及操作。
import pandas as pd
res6 = pd.read_csv('test.csv')
res6.shape(12, 3)
res6.columns
Index(['user_id', 'cate', 'shop_id'], dtype='object')
res6.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 12 entries, 0 to 11 Data columns (total 3 columns): user_id 12 non-null int64 cate 12 non-null int64 shop_id 12 non-null int64 dtypes: int64(3) memory usage: 368.0 bytes
res6.describe()
| user_id | cate | shop_id | |
|---|---|---|---|
| count | 1.200000e+01 | 12.000000 | 12.000000 |
| mean | 6.468688e+05 | 10.666667 | 3594.000000 |
| std | 3.988181e+05 | 6.665151 | 373.271775 |
| min | 2.421410e+05 | 7.000000 | 3388.000000 |
| 25% | 3.901920e+05 | 7.000000 | 3388.000000 |
| 50% | 4.938730e+05 | 7.000000 | 3388.000000 |
| 75% | 9.824990e+05 | 10.250000 | 3586.250000 |
| max | 1.558165e+06 | 23.000000 | 4278.000000 |
res6
| user_id | cate | shop_id | |
|---|---|---|---|
| 0 | 390192 | 20 | 4178 |
| 1 | 390192 | 23 | 4179 |
| 2 | 390192 | 22 | 4278 |
| 3 | 1021819 | 7 | 3388 |
| 4 | 242141 | 7 | 3388 |
| 5 | 283284 | 7 | 3388 |
| 6 | 1558165 | 7 | 3388 |
| 7 | 533696 | 7 | 3388 |
| 8 | 982499 | 7 | 3388 |
| 9 | 493873 | 7 | 3388 |
| 10 | 493873 | 7 | 3388 |
| 11 | 982499 | 7 | 3389 |
res6['user_id'].value_counts()
390192 3 982499 2 493873 2 242141 1 1021819 1 533696 1 1558165 1 283284 1 Name: user_id, dtype: int64
res6.groupby(['user_id']).size().sort_values(ascending=False)
user_id 390192 3 982499 2 493873 2 1558165 1 1021819 1 533696 1 283284 1 242141 1 dtype: int64
res6.groupby(['user_id', 'cate']).size().sort_values(ascending=False)
user_id cate 982499 7 2 493873 7 2 1558165 7 1 1021819 7 1 533696 7 1 390192 23 1 22 1 20 1 283284 7 1 242141 7 1 dtype: int64
res6_test = res6.groupby(['user_id', 'cate', 'shop_id']).size().sort_values(ascending=False) res6_test
user_id cate shop_id 493873 7 3388 2 1558165 7 3388 1 1021819 7 3388 1 982499 7 3389 1 3388 1 533696 7 3388 1 390192 23 4179 1 22 4278 1 20 4178 1 283284 7 3388 1 242141 7 3388 1 dtype: int64
感謝你能夠認真閱讀完這篇文章,希望小編分享的“python中如何使用pandas對多列進行分組統計”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





