溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了如何用Python爬取指定關鍵詞,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
我們此次選擇的是從移動端來對微博進行爬取。移動端的反爬就是信息校驗反爬蟲的cookie反爬蟲,所以我們首先要登陸獲取cookie。
登陸過后我們就可以獲取到自己的cookie了,有不懂的小伙伴可以看這篇文章學會Cookie,解決登錄爬取的困擾!。然后我們來觀察用戶是如何搜索微博內容的。
平時我們都是在這個地方輸入關鍵字,來進行搜索微博。

我通過在開發者模式下對這個頁面觀察發現,它每次對關鍵字發起請求后,就會返回一個XHR響應。
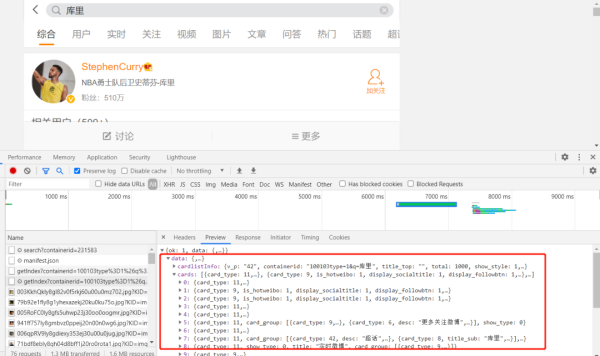
我們現在已經找到數據真實存在的頁面了,那就可以進行爬蟲的常規操作了。
在上面我們已經找到了數據存儲的真實網頁,現在我們只需對該網頁發起請求,然后提取數據即可。
01發起請求
通過對請求頭進行觀察,我們不難構造出請求代碼。
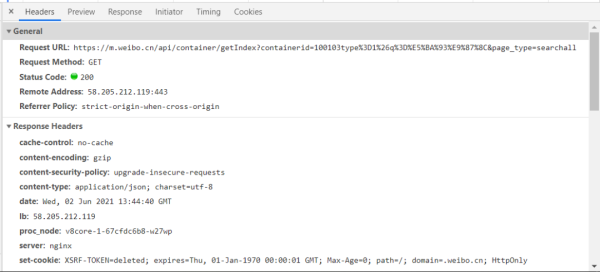
代碼如下:
key = input("請輸入爬取關鍵字:") for page in range(1,10): params = ( ('containerid', f'100103type=1&q={key}'), ('page_type', 'searchall'), ('page', str(page)), ) response = requests.get('https://m.weibo.cn/api/container/getIndex', headers=headers, params=params)02提取數據
從上面我們觀察發現這個數據可以轉化成字典來進行爬取,但是經過我實際測試發現,用正則來提取是最為簡單方便的,所以這里展示的是正則提取的方式,有興趣的讀者可以嘗試用字典方式來提取數據。代碼如下:
r = response.text title = re.findall('"page_title":"(.*?)"',r) comments_count = re.findall('"comments_count":(.*?),',r) attitudes_count = re.findall('"attitudes_count":(.*?),',r) for i in range(len(title)): print(eval(f"'{title[i]}'"),comments_count[i],attitudes_count[i])在這里有一個小問題要注意,微博的標題是用Unicode編碼的,如果直接爬取存儲,將存儲的是Unicode編碼,在這里要感謝大佬—小明哥的幫助,志斌在網上搜了好多解決方法都沒有成功,最后小明哥一個簡單的函數就給解決了,實在是佩服!
解決方案:用eval()來輸出標題,就可以將Unicode轉換成漢字了。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“如何用Python爬取指定關鍵詞”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





