



整篇文章分為兩部分:1.爬取愛奇藝中該劇第一集的彈幕 2.對爬取出來的彈幕做處理,并制作詞云。
1.爬取愛奇藝彈幕
相比于其他視頻網站來說,愛奇藝的彈幕難爬一些,為啥呢,因為你爬取出來的文件是亂碼的(下邊會貼圖),需要自己再把該文件二進制編碼之后才能用。具體步驟如下:
首先,打開瀏覽器,進入愛奇藝頁面,點開該劇,彈幕打開,然后F12,瀏覽器下方或者右側會彈出一些界面,選擇Network,在我圖上標注的框中輸入“bullet”搜索彈幕相關的文件,為啥輸入這個搜索呢,因為這個單詞的意思就是彈幕,程序員命名東西一般也是有規律的,還有大多視頻網站的彈幕相關文件都是這個名字哈哈。如果你F12搜索之后無內容,那直接點擊下瀏覽器刷新按鈕即可。下圖中箭頭指的分別是Network、搜索框、彈幕文件名和彈幕內容(你可以看到,彈幕內容是亂七八糟的亂碼)。還有說明一點,彈幕文件一集不止一個,愛奇藝5分鐘加載一個彈幕文件(為啥5分鐘,下邊會解釋)。
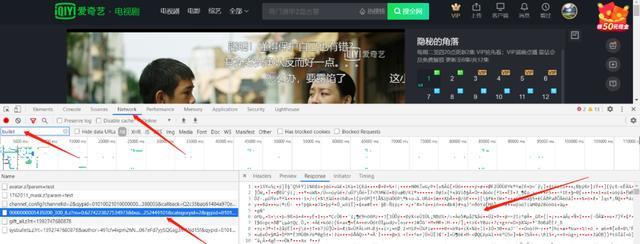
接下來,觀察彈幕文件出現的規律以及彈幕文件地址中的規律,總結為以下:
彈幕文件鏈接規律為
https://cmts.iqiyi.com/bullet/tvid倒數4位的前兩位/tvid最后兩位/tvid_300_x.z;
x的計算方式為片子總時長除以300秒向上取整,即按每5分鐘一個包。
tvid是啥呢,就是你URL導航欄里的這塊,x為啥按5分鐘一個包呢,是因為我F12之后查看兩個相鄰的彈幕文件包,它就是5分鐘加載一個。

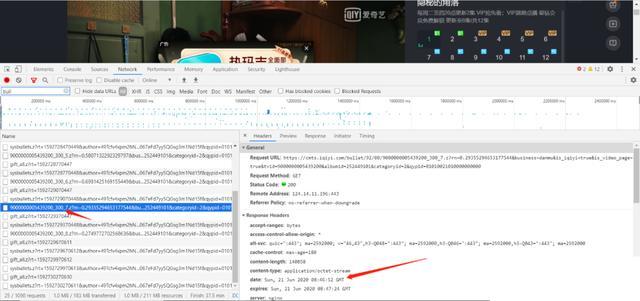
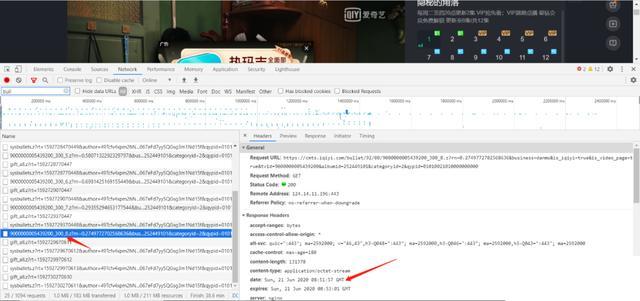
那第一集總共時長77分鐘,按5分鐘加載一個彈幕文件的話,向上取整,我們總共要抓取16個(77/5+1)彈幕文件。
抓取代碼為:
import zlib
import requests
for x in range(16):
x+=1
#x是從1到16,16怎么來的,第一集總共77分鐘,愛奇藝每5分鐘會加載新的彈幕
#77除以5向上取整
url='https://cmts.iqiyi.com/bullet/92/00/9000000005439200_300_'+str(x)+'.z'
bulletold=requests.get(url).content #這步取出來的文件是亂碼的
bulletnew = bytearray(bulletold)#將上一步的亂碼文件用二進制再編碼下
xml=zlib.decompress(bulletnew, 15+32).decode('utf-8')
#把編碼好的文件分別寫入16個xml文件中(類似于txt文件),方便后邊取數據
with open('./iqiyi'+str(x)+'.xml','a+',encoding='utf-8') as f:
f.write(xml)
f.close()
抓取出來的xml文件為下圖,能看出來content字段就是彈幕:
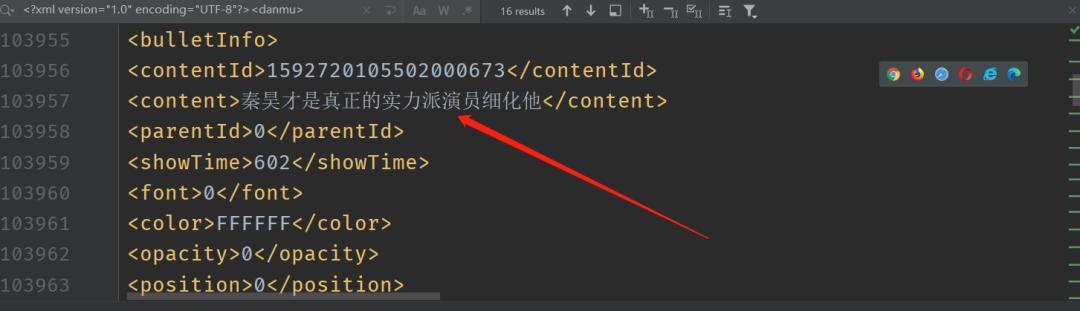
將xml文件中的content字段取出來存為dan_mu.txt文件,方便我們之后做詞云:
from xml.dom.minidom import parse
import xml.dom.minidom
for x in range(16):
x+=1
DOMTree = xml.dom.minidom.parse(r"C:\Users\dmj\PycharmProjects\test\iqiyi"+str(x)+".xml")
collection = DOMTree.documentElement
# 在集合中獲取所有entry數據
entrys = collection.getElementsByTagName("entry")
print(entrys)
for entry in entrys:
content = entry.getElementsByTagName('content')[0]
print(content.childNodes[0].data)
i = content.childNodes[0].data
with open("dan_mu.txt", mode="a+", encoding="utf-8") as f:
f.write(i)
f.write("\n")dan_mu.txt文件大概長這樣:
2.制作詞云
制作詞云使用python的wordcloud庫和jieba庫,代碼如下:
from wordcloud import WordCloud
import jieba
import matplotlib.pyplot as plt
#讀取彈幕txt文件
with open('./dan_mu.txt',encoding = 'utf-8', mode = 'r')as f:
myText = f.read()
myText = " ".join(jieba.cut(myText))
list = myText.split(" ")
#清洗無用數據
for i in range(len(list)-1,-1,-1):
if len(list[i])==1 or list[i]=="這個" or \
list[i]=="不是" or list[i]=="這么" \
or list[i]=="怎么" or list[i]=="這是"\
or list[i]=="還是":
list.remove(list[i])
#print(list)
myText= " ".join(list)
print(myText)
# 制作詞云
wordcloud = WordCloud(background_color="white", font_path="simsun.ttf", height=300, width = 400).generate(myText)
# 圖片展示
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
# 將詞云圖片導出到當前文件夾
wordcloud.to_file("wordCloudMo.png")在此處可能會遇到的問題是,wordcloud這個外部庫你在下載的時候可能會遇到各種花式報錯,如何解決呢,參見下邊這位老哥的方法:
https://blog.csdn.net/qq_42813128/article/details/82020510
詞云圖結果如下:

從詞云圖中我們可以看到,“真實”,“孩子”,“嚴良”,“普普”,“演技”等詞語出現的頻率很高。“真實”,“演技”,“厲害”等詞語是大家對這部劇的肯定;“孩子”指的是這三個主演的小孩;“普普”的演技真的很不錯,大家都猜測她會不會成為下一個張子楓。
總體來講,彈幕中大家對這部劇基本都是好評,所以還是值得一看的。

