溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關python如何爬取bilibili的彈幕制作詞云,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
需要知道cid,可以F12,F5刷新,找cid,找到之后拼接url
也可以寫代碼,解析response獲取cid,然后再拼接
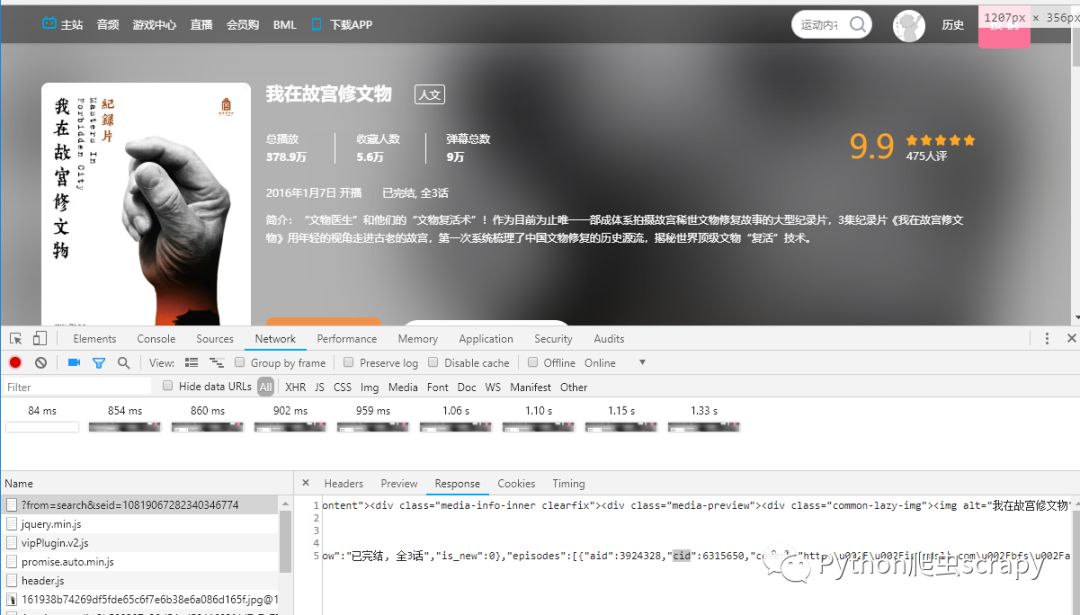

使用requests或者urllib都可以
我是用requests,請求該鏈接獲取到xml文件
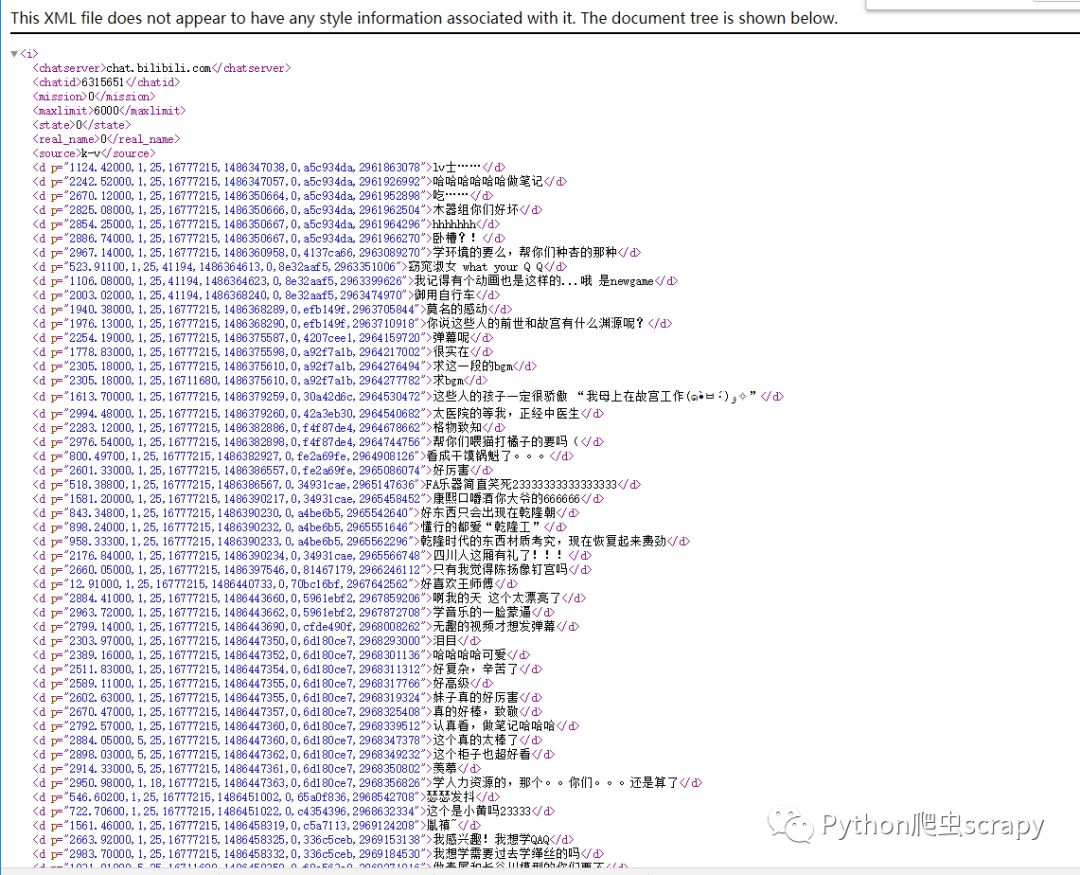
代碼:獲取xml
def get_data():
res = requests.get('http://comment.bilibili.com/6315651.xml')
res.encoding = 'utf8'
with open('gugongdanmu.xml', 'a', encoding='utf8') as f:
f.writelines(res.text)解析xml,
def analyze_xml():
f1 = open("gugongdanmu.xml", "r", encoding='utf8')
f2 = open("tanmu2.txt", "w", encoding='utf8')
count = 0
# 正則匹配解決xml的多余的字符
dr = re.compile(r'<[^>]+>', re.S)
while 1:
line = f1.readline()
if not line:
break
pass
# 匹配到之后用空代替
dd = dr.sub('', line)
# dd = re.findall(dr, line)
count = count+1
f2.writelines(dd)
print(count)去掉無用的字符和數字,找出所有的漢字
def analyze_hanzi():
f1 = open("tanmu2.txt", "r", encoding='utf8')
f2 = open("tanmu3.txt", "w", encoding='utf8')
count = 0
# dr = re.compile(r'<[^>]+>',re.S)
# 所有的漢字[一-龥]
dr = re.compile(r'[一-龥]+',re.S)
while 1:
line = f1.readline()
if not line:
break
pass
# 找出無用的符號和數字
# dd = dr.sub('',line)
dd = re.findall(dr, line)
count = count+1
f2.writelines(dd)
print(count)
# pattern = re.compile(r'[一-龥]+')使用jieba分詞,生成詞云
def show_sign():
content = read_txt_file()
segment = jieba.lcut(content)
words_df = pd.DataFrame({'segment': segment})
stopwords = pd.read_csv("stopwords.txt", index_col=False, quoting=3, sep=" ", names=['stopword'], encoding='utf-8')
words_df = words_df[~words_df.segment.isin(stopwords.stopword)]
print(words_df)
print('-------------------------------')
words_stat = words_df.groupby(by=['segment'])['segment'].agg(numpy.size)
words_stat = words_stat.to_frame()
words_stat.columns = ['計數']
words_stat = words_stat.reset_index().sort_values(by=["計數"], ascending=False)
# 設置詞云屬性
color_mask = imread('ciyun.png')
wordcloud = WordCloud(font_path="simhei.ttf", # 設置字體可以顯示中文
background_color="white", # 背景顏色
max_words=1000, # 詞云顯示的最大詞數
mask=color_mask, # 設置背景圖片
max_font_size=100, # 字體最大值
random_state=42,
width=1000, height=860, margin=2,
# 設置圖片默認的大小,但是如果使用背景圖片的話, # 那么保存的圖片大小將會按照其大小保存,margin為詞語邊緣距離
)
# 生成詞云, 可以用generate輸入全部文本,也可以我們計算好詞頻后使用generate_from_frequencies函數
word_frequence = {x[0]: x[1] for x in words_stat.head(1000).values}
print(word_frequence)
# for key,value in word_frequence:
# write_txt_file(word_frequence)
word_frequence_dict = {}
for key in word_frequence:
word_frequence_dict[key] = word_frequence[key]
wordcloud.generate_from_frequencies(word_frequence_dict)
# 從背景圖片生成顏色值
image_colors = ImageColorGenerator(color_mask)
# 重新上色
wordcloud.recolor(color_func=image_colors)
# 保存圖片
wordcloud.to_file('output.png')
plt.imshow(wordcloud)
plt.axis("off")
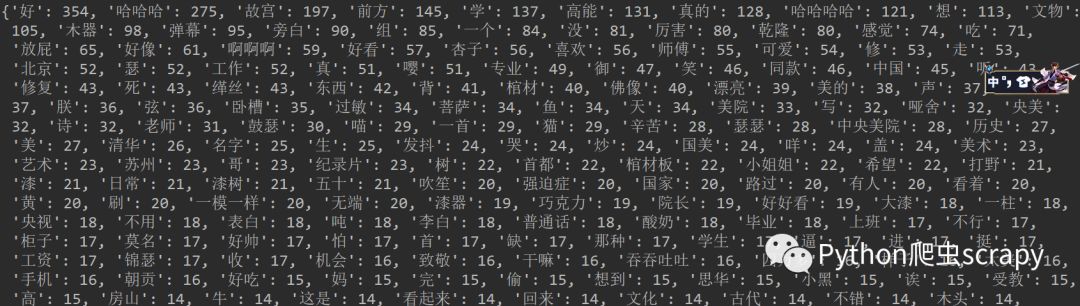
plt.show()運行程序,結果:


統計的結果
完成!
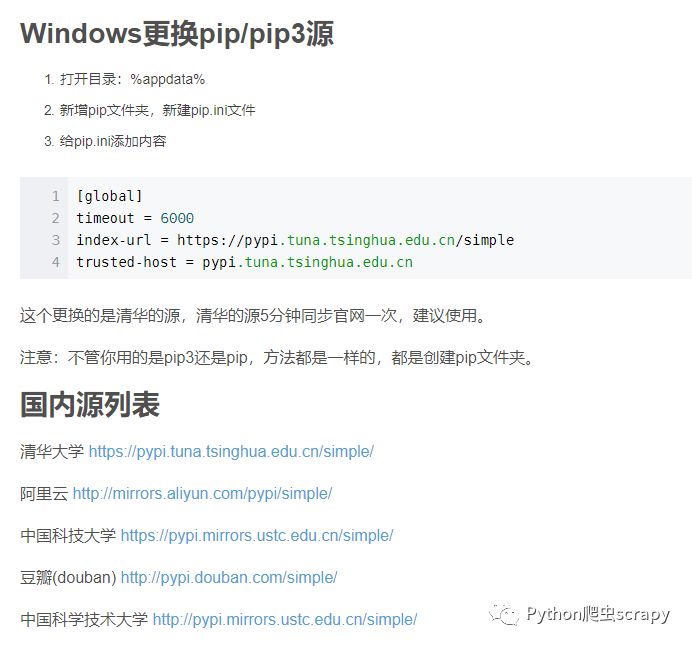
pip的換源,原來的太慢,然后將你自己沒有庫裝上
關于“python如何爬取bilibili的彈幕制作詞云”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





