溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“puppeteer是什么”,在日常操作中,相信很多人在puppeteer是什么問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”puppeteer是什么”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
一、Puppeteer簡介
Puppeteer 是一個 Node 庫,它提供了一個高級 API 來通過 DevTools 協議控制 Chromium 或 Chrome,利用Puppeteer可以獲取頁面DOM節點、網絡請求和響應、程序化操作頁面行為、進行頁面的性能監控和優化、獲取頁面截圖和PDF等,利用該神器就可以操作Chrome瀏覽器玩出各種花樣。
Puppeteer的結構也反映了瀏覽器的結構,其核心結構如下所示:
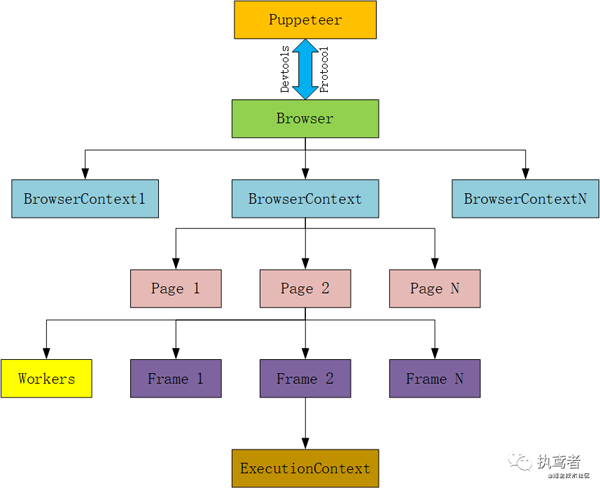
圖片
Browser:這是一個瀏覽器實例,可以擁有瀏覽器上下文,可通過 puppeteer.launch 或 puppeteer.connect 創建一個 Browser 對象。
BrowserContext:該實例定義了一個瀏覽器上下文,可擁有多個頁面,創建瀏覽器實例時默認會創建一個瀏覽器上下文(不能關閉),此外可以利用 browser.createIncognitoBrowserContext()創建一個匿名的瀏覽器上下文(不會與其它瀏覽器上下文共享cookie/cache).
Page:至少包含一個主框架,除了主框架外還有可能存在其它框架,例如iframe。
Frame:頁面中的框架,在每個時間點,頁面通過page.mainFrame()和frame.childFrames()方法暴露當前框架的細節。對于該框架中至少有一個執行上下文
ExecutionCOntext:表示一個JavaScript的執行上下文。
Worker:具有單個執行上下文,便于與 WebWorkers 交互。
該神器整體使用起來比較簡單,下面就開始我們的使用之路。
核心函數就是異步調用puppeteer.launch()函數,根據相應的配置參數創建一個Browser實例。
const path = require('path'); const puppeteer = require('puppeteer'); const chromiumPath = path.join(__dirname, '../', 'chromium/chromium/chrome.exe'); async function main() { // 啟動chrome瀏覽器 const browser = await puppeteer.launch({ // 指定該瀏覽器的路徑 executablePath: chromiumPath, // 是否為無頭瀏覽器模式,默認為無頭瀏覽器模式 headless: false }); } main();訪問頁面首先需要創建一個瀏覽器上下文,然后基于該上下文創建一個新的page,最后指定要訪問的網址。
async function main() { // 啟動chrome瀏覽器 // …… // 在一個默認的瀏覽器上下文中被創建一個新頁面 const page1 = await browser.newPage(); // 空白頁訪問該指定網址 await page1.goto('https://51yangsheng.com'); // 創建一個匿名的瀏覽器上下文 const browserContext = await browser.createIncognitoBrowserContext(); // 在該上下文中創建一個新頁面 const page2 = await browserContext.newPage(); page2.goto('https://www.baidu.com'); } main();經常需要不同類型的機型的瀏覽結果,此時就可以采用設備模擬實現,下面模擬一個iPhone X的設備的瀏覽器結果
async function main() { // 啟動瀏覽器 // 設備模擬:模擬一個iPhone X // user agent await page1.setUserAgent('Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1') // 視口(viewport)模擬 await page1.setViewport({ width: 375, height: 812 }); // 訪問某頁面 } main();獲取DOM節點有兩種方式,一種方式是直接調用page所帶的原生函數,另一種是通過執行js代碼獲取。
async function main() { // 啟動chrome瀏覽器 const browser = await puppeteer.launch({ // 指定該瀏覽器的路徑 executablePath: chromiumPath, // 是否為無頭瀏覽器模式,默認為無頭瀏覽器模式 headless: false }); // 在一個默認的瀏覽器上下文中被創建一個新頁面 const page1 = await browser.newPage(); // 空白頁訪問該指定網址 await page1.goto('https://www.baidu.com'); // 等待title節點出現 await page1.waitForSelector('title'); // 用page自帶的方法獲取節點 const titleDomText1 = await page1.$eval('title', el => el.innerText); console.log(titleDomText1);// 百度一下 // 用js獲取節點 const titleDomText2 = await page1.evaluate(() => { const titleDom = document.querySelector('title'); return titleDom.innerText; }); console.log(titleDomText2); } main();下面就來監聽一下百度中某一js腳本的請求和響應,request事件是監聽請求,response事件是監聽響應。
async function main() { // 啟動chrome瀏覽器 const browser = await puppeteer.launch({ // 指定該瀏覽器的路徑 executablePath: chromiumPath, // 是否為無頭瀏覽器模式,默認為無頭瀏覽器模式 headless: false }); // 在一個默認的瀏覽器上下文中被創建一個新頁面 const page1 = await browser.newPage(); page1.on('request', request => { if (request.url() === 'https://s.bdstatic.com/common/openjs/amd/eslx.js') { console.log(request.resourceType()); console.log(request.method()); console.log(request.headers()); } }); page1.on('response', response => { if (response.url() === 'https://s.bdstatic.com/common/openjs/amd/eslx.js') { console.log(response.status()); console.log(response.headers()); } }) // 空白頁剛問該指定網址 await page1.goto('https://www.baidu.com'); } main();默認情況下request事件只有只讀屬性,不能夠攔截請求,若想攔截該請求則需要通過page.setRequestInterception(value)啟動請求攔截器,然后利用request.abort, request.continue 和 request.respond 方法決定該請求的下一步操作。
async function main() { // 啟動chrome瀏覽器 const browser = await puppeteer.launch({ // 指定該瀏覽器的路徑 executablePath: chromiumPath, // 是否為無頭瀏覽器模式,默認為無頭瀏覽器模式 headless: false }); // 在一個默認的瀏覽器上下文中被創建一個新頁面 const page1 = await browser.newPage(); // 攔截請求開啟 await page1.setRequestInterception(true);// true開啟,false關閉 page1.on('request', request => { if (request.url() === 'https://s.bdstatic.com/common/openjs/amd/eslx.js') { // 終止該請求 request.abort(); console.log('該請求被終止!!!'); } else { // 繼續該請求 request.continue(); } }); // 空白頁訪問該指定網址 await page1.goto('https://www.baidu.com'); } main();截圖是一個很有用的功能,通過截取就可以保存一份快照,方便后期問題的排查。(注:在無頭模式下進行截圖,否則截的圖可能有問題)
async function main() { // 啟動瀏覽器,訪問頁面的操作 // 截屏操作,使用Page.screenshot函數 // 截取整個頁面:Page.screenshot函數默認截取整個頁面,加上fullPage參數就是全屏截取 await page1.screenshot({ path: '../imgs/fullScreen.png', fullPage: true }); // 截取屏幕中一個區域的內容 await page1.screenshot({ path: '../imgs/partScreen.jpg', type: 'jpeg', quality: 80, clip: { x: 0, y: 0, width: 375, height: 300 } }); browser.close(); } main();除了利用截圖保留快照外,還可以使用pdf保留快照。
async function main() { // 啟動瀏覽器,訪問頁面的操作 // 根據網頁內容生成pdf文件,使用Page.pdf——注意:必須在無頭模式下才可以調用 await page1.pdf({ path: '../pdf/baidu.pdf' }); browser.close(); } main();到此,關于“puppeteer是什么”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





