溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“如何理解SR的圖靈完備性”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“如何理解SR的圖靈完備性”吧!
圖靈機是英國數學家阿蘭·圖靈在1936年的文章《On Computable Numbers, with an Application to the Entscheidungsproblem》中提出的抽象計算模型.

在論文的第三章講述了一個計算機的例子,即一個機器包含了一條無限長的紙帶,紙帶被分成一些Square,然后上面有一些二進制編碼的symbol。存在一個事先約定好的指令, 例如R表示機器將掃描右側的Square,同理L表示左側,E表示擦除,P表示打印等.計算即根據讀寫頭和規則表決定動作,當讀寫頭停機時,打印輸出的就是計算結果:
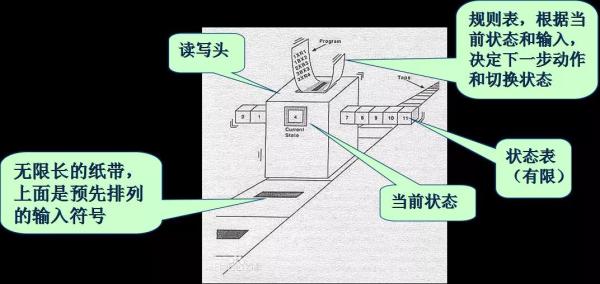
圖靈完備是指,當你設計了一套操作數據的規則后,這套指令集或者語言能夠模擬圖靈機,那么就說這套規則是圖靈完備的。通常很多編程語言的圖靈完備性影響主要需要考慮分支Branch和循環loop的問題。當然有一些語言故意設計成非圖靈完備的,例如很多區塊鏈的合約執行指令不支持分支跳轉和循環,主要的目的是它使用的場景和安全性考慮決定的。
SR本身的編碼上來看,并不是圖靈完備的. 因為SR Label只能順序執行。當然也可以做一些特殊的處理,例如Binding-SID可以看做是一個特殊的函數調用,然后借用MPLS Stack的結構,可以實現函數入棧. 同時我們也可以定義一些特殊的Label行為來進行Label跳轉, 但又有另一個缺陷,處理報文的時候,我們并沒有設計相應的狀態機。如果要設計,又會成為一個Stateful的forwarding feature,需要相應的流表和動態狀態更新。
某種意義上來講,MPLS-SR因為有棧的結構,入棧和彈出標簽相對容易。而SRv6則是一個工程上的災難,由于必須保留報文的源IP地址,一方面有uRPF的缺陷,另一方面維持IP頭并要同時操作SRH產生了一系列問題,例如交換機通常沒法同時處理這么大量的數據,SRv6標簽棧深度受限。
而針對棧結構,SRv6的SRH在報文中間。入棧和出棧對于P4一類的交換機容易,Deparser上插進去或者砍掉就好。但是傳統的CPU架構而言,都需要大量的memory move的操作,我還在開玩笑,Intel啥時候能夠出一個批量操作I/O的deparser呢,集成在網卡上或者CPU上都行....
在設計的時候,如果能丟棄原有的IPv6頭,根據SRH的信息重建便是一個更好的解決方案,這樣標簽入棧出棧的處理相對容易很多,uRPF的缺陷也可以避免。所以反過來你就能明白RFC8663 MPLS-SR over UDP的能夠在很多場景被接受的原因。但是很抱歉MPLS-SR的問題來自于標簽棧的長度,以及沒有類似于SRv6那樣定義的
我們來看另一個問題,P4設計之初是完全基于硬件能力的,一旦涉及分支Branch極易帶來流水線的Stall,因此P4早期的MAU并沒有打算支持分支預測,更多的是采用match不同的表產生新的action來將流量分擔到另一個MAU實現的。Torfino-2增加了一些功能,而為了實現更加靈活多樣的計算,Pensando的實現中直接增加了寄存器/PC/Branch器件.
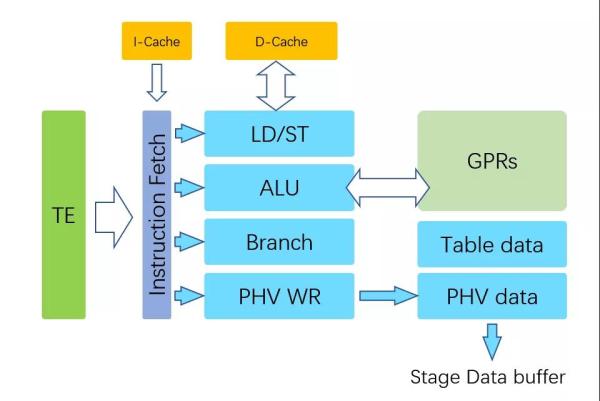
而NanoPU更是直接把一個處理器堆到了P4 MAU旁邊。
很多人總是喜歡一招鮮打遍天下,但真的有必要什么都做么?前段時間有個某云的同學發了一個朋友圈說什么指標都要追求世界第一, 我補了一句那么價格肯定也世界第一。成年人有足夠的支持時可以輕松的說不需要選擇,都要。但是技術總是需要取舍的。加法容易減法難,就是這個道理。
計算、存儲、網絡這三者的組合有其內在的精妙,存內計算(In Memory Computing)和邊緣計算提出的算力網絡都是為了解決馮諾依曼架構的缺陷,使得計算規模能夠再上一個臺階。但是另一個可信計算的問題又會困擾大家。
架構上我并不認同網絡能夠實現大量的圖靈完備的計算,而是可以通過一系列組合為計算和存儲搭起一個更好的橋梁。
感謝各位的閱讀,以上就是“如何理解SR的圖靈完備性”的內容了,經過本文的學習后,相信大家對如何理解SR的圖靈完備性這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





