溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關分庫分表和NewSQL數據庫的原理對比是什么,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
最近與同行科技交流,經常被問到分庫分表與分布式數據庫如何選擇,網上也有很多關于中間件+傳統關系數據庫(分庫分表)與NewSQL分布式數據庫的文章,但有些觀點與判斷是我覺得是偏激的,脫離環境去評價方案好壞其實有失公允。
本文通過對兩種模式關鍵特性實現原理對比,希望可以盡可能客觀、中立的闡明各自真實的優缺點以及適用場景。
首先關于“中間件+關系數據庫分庫分表”算不算NewSQL分布式數據庫問題,國外有篇論文pavlo-newsql-sigmodrec,如果根據該文中的分類,Spanner、TiDB、OB算是第一種新架構型,Sharding-Sphere、Mycat、DRDS等中間件方案算是第二種(文中還有第三種云數據庫,本文暫不詳細介紹)。
基于中間件(包括SDK和Proxy兩種形式)+傳統關系數據庫(分庫分表)模式是不是分布式架構?我覺得是的,因為存儲確實也分布式了,也能實現橫向擴展。但是不是"偽"分布式數據庫?從架構先進性來看,這么說也有一定道理。"偽"主要體現在中間件層與底層DB重復的SQL解析與執行計劃生成、存儲引擎基于B+Tree等,這在分布式數據庫架構中實際上冗余低效的。為了避免引起真偽分布式數據庫的口水戰,本文中NewSQL數據庫特指這種新架構NewSQL數據庫。
NewSQL數據庫相比中間件+分庫分表的先進在哪兒?畫一個簡單的架構對比圖:
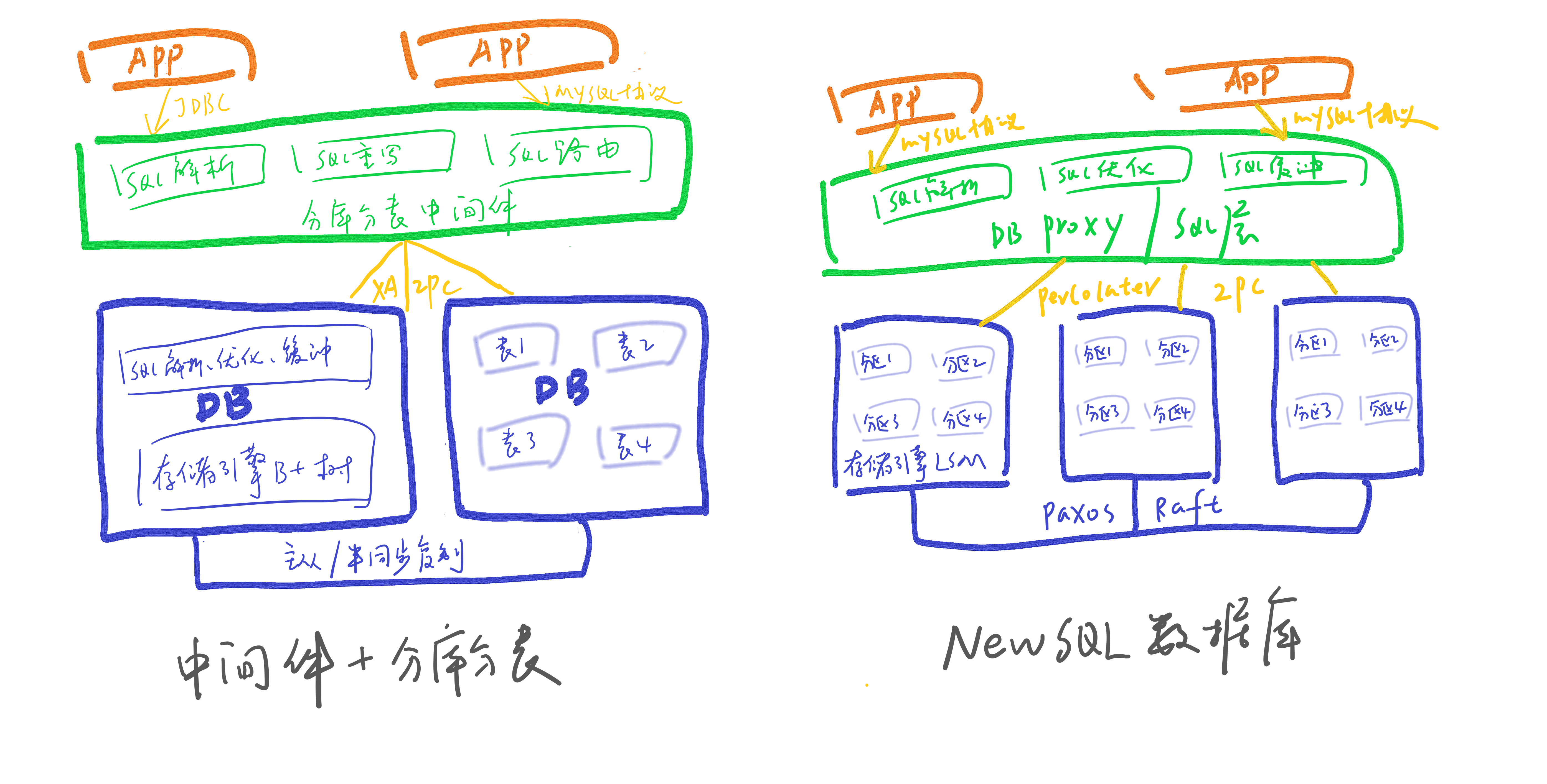
傳統數據庫面向磁盤設計,基于內存的存儲管理及并發控制,不如NewSQL數據庫那般高效利用。
中間件模式SQL解析、執行計劃優化等在中間件與數據庫中重復工作,效率相比較低;
NewSQL數據庫的分布式事務相比于XA進行了優化,性能更高;
新架構NewSQL數據庫存儲設計即為基于paxos(或Raft)協議的多副本,相比于傳統數據庫主從模式(半同步轉異步后也存在丟數問題),在實現了真正的高可用、高可靠(RTO<30s,RPO=0)
NewSQL數據庫天生支持數據分片,數據的遷移、擴容都是自動化的,大大減輕了DBA的工作,同時對應用透明,無需在SQL指定分庫分表鍵。
這些大多也是NewSQL數據庫產品主要宣傳的點,不過這些看起來很美好的功能是否真的如此?接下來針對以上幾點分別闡述下的我的理解。
這是把雙刃劍。
想想更早些出現的NoSQL數據庫為何不支持分布式事務(最新版的mongoDB等也開始支持了),是缺乏理論與實踐支撐嗎?并不是,原因是CAP定理依然是分布式數據庫頭上的頸箍咒,在保證強一致的同時必然會犧牲可用性A或分區容忍性P。為什么大部分NoSQL不提供分布式事務?
那么NewSQL數據庫突破CAP定理限制了嗎?并沒有。NewSQL數據庫的鼻主Google Spanner(目前絕大部分分布式數據庫都是按照Spanner架構設計的)提供了一致性和大于5個9的可用性,宣稱是一個“實際上是CA”的,其真正的含義是系統處于 CA 狀態的概率非常高,由于網絡分區導致的服務停用的概率非常小,究其真正原因是其打造私有全球網保證了不會出現網絡中斷引發的網絡分區,另外就是其高效的運維隊伍,這也是cloud spanner的賣點。詳細可見CAP提出者Eric Brewer寫的《Spanner, TrueTime 和CAP理論》。
推薦一篇關于分布式系統有趣的文章,站在巨人的分布式肩膀上,其中提到:分布式系統中,您可以知道工作在哪里,或者您可以知道工作何時完成,但您無法同時了解兩者;兩階段協議本質上是反可用性協議。
兩階段提交協議是否嚴格支持ACID,各種異常場景是不是都可以覆蓋?
2PC在commit階段發送異常,其實跟最大努力一階段提交類似也會有部分可見問題,嚴格講一段時間內并不能保證A原子性和C一致性(待故障恢復后recovery機制可以保證最終的A和C)。完備的分布式事務支持并不是一件簡單的事情,需要可以應對網絡以及各種硬件包括網卡、磁盤、CPU、內存、電源等各類異常,通過嚴格的測試。之前跟某友商交流,他們甚至說目前已知的NewSQL在分布式事務支持上都是不完整的,他們都有案例跑不過,圈內人士這么篤定,也說明了分布式事務的支持完整程度其實是層次不齊的。
但分布式事務又是這些NewSQL數據庫的一個非常重要的底層機制,跨資源的DML、DDL等都依賴其實現,如果這塊的性能、完備性打折扣,上層跨分片SQL執行的正確性會受到很大影響。
傳統關系數據庫也支持分布式事務XA,但為何很少有高并發場景下用呢? 因為XA的基礎兩階段提交協議存在網絡開銷大,阻塞時間長、死鎖等問題,這也導致了其實際上很少大規模用在基于傳統關系數據庫的OLTP系統中。
NewSQL數據庫的分布式事務實現也仍然多基于兩階段提交協議,例如google percolator分布式事務模型,
采用原子鐘+MVCC+ Snapshot Isolation(SI),這種方式通過TSO(Timestamp Oracle)保證了全局一致性,通過MVCC避免了鎖,另外通過primary lock和secondary lock將提交的一部分轉為異步,相比XA確實提高了分布式事務的性能。
SI是樂觀鎖,在熱點數據場景,可能會大量的提交失敗。另外SI的隔離級別與RR并非完全相同,它不會有幻想讀,但會有寫傾斜。
但不管如何優化,相比于1PC,2PC多出來的GID獲取、網絡開銷、prepare日志持久化還是會帶來很大的性能損失,尤其是跨節點的數量比較多時會更加顯著,例如在銀行場景做個批量扣款,一個文件可能上W個賬戶,這樣的場景無論怎么做還是吞吐都不會很高。
Spanner給出的分布式事務測試數據
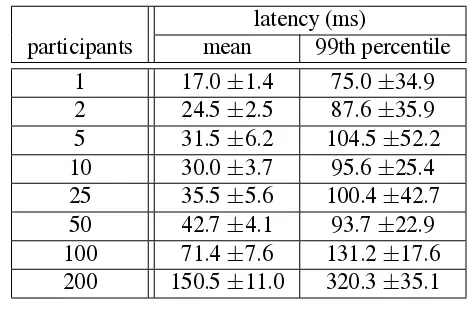
雖然NewSQL分布式數據庫產品都宣傳完備支持分布式事務,但這并不是說應用可以完全不用關心數據拆分,這些數據庫的最佳實踐中仍然會寫到,應用的大部分場景盡可能避免分布式事務。
既然強一致事務付出的性能代價太大,我們可以反思下是否真的需要這種強一致的分布式事務?尤其是在做微服務拆分后,很多系統也不太可能放在一個統一的數據庫中。嘗試將一致性要求弱化,便是柔性事務,放棄ACID(Atomicity,Consistency, Isolation, Durability),轉投BASE(Basically Available,Soft state,Eventually consistent),例如Saga、TCC、可靠消息保證最終一致等模型,對于大規模高并發OLTP場景,我個人更建議使用柔性事務而非強一致的分布式事務。關于柔性事務,筆者之前也寫過一個技術組件,最近幾年也涌現出了一些新的模型與框架(例如阿里剛開源的Fescar),限于篇幅不再贅述,有空再單獨寫篇文章。
解決分布式事務是否只能用兩階段提交協議?
oceanbase1.0中通過updateserver避免分布式事務的思路很有啟發性 ,不過2.0版后也變成了2PC。
業界分布式事務也并非只有兩階段提交這一解,也有其它方案its-time-to-move-on-from-two-phase(如果打不開,國內有翻譯版https://www.jdon.com/51588)
主從模式并不是最優的方式,就算是半同步復制,在極端情況下(半同步轉異步)也存在丟數問題,目前業界公認更好的方案是基于paxos分布式一致性協議或者其它類paxos如raft方式,Google Spanner、TiDB、cockcoachDB、OB都采用了這種方式,基于Paxos協議的多副本存儲,遵循過半寫原則,支持自動選主,解決了數據的高可靠,縮短了failover時間,提高了可用性,特別是減少了運維的工作量,這種方案技術上已經很成熟,也是NewSQL數據庫底層的標配。
當然這種方式其實也可以用在傳統關系數據庫,阿里、微信團隊等也有將MySQL存儲改造支持paxos多副本的,MySQL也推出了官方版MySQL Group Cluster,預計不遠的未來主從模式可能就成為歷史了。
分布式一致性算法本身并不難,但具體在工程實踐時,需要考慮很多異常并做很多優化,實現一個生產級可靠成熟的一致性協議并不容易。例如實際使用時必須轉化實現為multi-paxos或multi-raft,需要通過batch、異步等方式減少網絡、磁盤IO等開銷。
需要注意的是很多NewSQL數據庫廠商宣傳基于paxos或raft協議可以實現【異地多活】,這個實際上是有前提的,那就是異地之間網絡延遲不能太高。以銀行“兩地三中心”為例,異地之間多相隔數千里,延時達到數十毫秒,如果要多活,那便需異地副本也參與數據庫日志過半確認,這樣高的延時幾乎沒有OLTP系統可以接受的。
數據庫層面做異地多活是個美好的愿景,但距離導致的延時目前并沒有好的方案。之前跟螞蟻團隊交流,螞蟻異地多活的方案是在應用層通過MQ同步雙寫交易信息,異地DC將交易信息保存在分布式緩存中,一旦發生異地切換,數據庫同步中間件會告之數據延遲時間,應用從緩存中讀取交易信息,將這段時間內涉及到的業務對象例如用戶、賬戶進行黑名單管理,等數據同步追上之后再將這些業務對象從黑名單中剔除。由于雙寫的不是所有數據庫操作日志而只是交易信息,數據延遲只影響一段時間內數據,這是目前我覺得比較靠譜的異地度多活方案。
另外有些系統進行了單元化改造,這在paxos選主時也要結合考慮進去,這也是目前很多NewSQL數據庫欠缺的功能。
paxos算法解決了高可用、高可靠問題,并沒有解決Scale橫向擴展的問題,所以分片是必須支持的。NewSQL數據庫都是天生內置分片機制的,而且會根據每個分片的數據負載(磁盤使用率、寫入速度等)自動識別熱點,然后進行分片的分裂、數據遷移、合并,這些過程應用是無感知的,這省去了DBA的很多運維工作量。以TiDB為例,它將數據切成region,如果region到64M時,數據自動進行遷移。
分庫分表模式下需要應用設計之初就要明確各表的拆分鍵、拆分方式(range、取模、一致性哈希或者自定義路由表)、路由規則、拆分庫表數量、擴容方式等。相比NewSQL數據庫,這種模式給應用帶來了很大侵入和復雜度,這對大多數系統來說也是一大挑戰。
分庫分表模式也能做到在線擴容,基本思路是通過異步復制先追加數據,然后設置只讀完成路由切換,最后放開寫操作,當然這些需要中間件與數據庫端配合一起才能完成。
這里有個問題是NewSQL數據庫統一的內置分片策略(例如tidb基于range)可能并不是最高效的,因為與領域模型中的劃分要素并不一致,這導致的后果是很多交易會產生分布式事務。舉個例子,銀行核心業務系統是以客戶為維度,也就是說客戶表、該客戶的賬戶表、流水表在絕大部分場景下是一起寫的,但如果按照各表主鍵range進行分片,這個交易并不能在一個分片上完成,這在高頻OLTP系統中會帶來性能問題。
常見的單分片SQL,這兩者都能很好支持。NewSQL數據庫由于定位與目標是一個通用的數據庫,所以支持的SQL會更完整,包括跨分片的join、聚合等復雜SQL。中間件模式多面向應用需求設計,不過大部分也支持帶拆分鍵SQL、庫表遍歷、單庫join、聚合、排序、分頁等。但對跨庫的join以及聚合支持就不夠了。
NewSQL數據庫一般并不支持存儲過程、視圖、外鍵等功能,而中間件模式底層就是傳統關系數據庫,這些功能如果只是涉及單庫是比較容易支持的。
NewSQL數據庫往往選擇兼容MySQL或者PostgreSQL協議,所以SQL支持僅局限于這兩種,中間件例如驅動模式往往只需做簡單的SQL解析、計算路由、SQL重寫,所以可以支持更多種類的數據庫SQL。
SQL支持的差異主要在于分布式SQL執行計劃生成器,由于NewSQL數據庫具有底層數據的分布、統計信息,因此可以做CBO,生成的執行計劃效率更高,而中間件模式下沒有這些信息,往往只能基于規則RBO(Rule-Based-Opimization),這也是為什么中間件模式一般并不支持跨庫join,因為實現了效率也往往并不高,還不如交給應用去做。
這里也可以看出中間件+分庫分表模式的架構風格體現出的是一種妥協、平衡,它是一個面向應用型的設計;而NewSQL數據庫則要求更高、“大包大攬”,它是一個通用底層技術軟件,因此后者的復雜度、技術門檻也高很多。
傳統關系數據庫的存儲引擎設計都是面向磁盤的,大多都基于B+樹。B+樹通過降低樹的高度減少隨機讀、進而減少磁盤尋道次數,提高讀的性能,但大量的隨機寫會導致樹的分裂,從而帶來隨機寫,導致寫性能下降。NewSQL的底層存儲引擎則多采用LSM,相比B+樹LSM將對磁盤的隨機寫變成順序寫,大大提高了寫的性能。不過LSM的的讀由于需要合并數據性能比B+樹差,一般來說LSM更適合應在寫大于讀的場景。當然這只是單純數據結構角度的對比,在數據庫實際實現時還會通過SSD、緩沖、bloom filter等方式優化讀寫性能,所以讀性能基本不會下降太多。NewSQL數據由于多副本、分布式事務等開銷,相比單機關系數據庫SQL的響應時間并不占優,但由于集群的彈性擴展,整體QPS提升還是很明顯的,這也是NewSQL數據庫廠商說分布式數據庫更看重的是吞吐,而不是單筆SQL響應時間的原因。
分布式數據庫是個新型通用底層軟件,準確的衡量與評價需要一個多維度的測試模型,需包括發展現狀、使用情況、社區生態、監控運維、周邊配套工具、功能滿足度、DBA人才、SQL兼容性、性能測試、高可用測試、在線擴容、分布式事務、隔離級別、在線DDL等等,雖然NewSQL數據庫發展經過了一定時間檢驗,但多集中在互聯網以及傳統企業非核心交易系統中,目前還處于快速迭代、規模使用不斷優化完善的階段。
相比而言,傳統關系數據庫則經過了多年的發展,通過完整的評測,在成熟度、功能、性能、周邊生態、風險把控、相關人才積累等多方面都具有明顯優勢,同時對已建系統的兼容性也更好。
對于互聯網公司,數據量的增長壓力以及追求新技術的基因會更傾向于嘗試NewSQL數據庫,不用再考慮庫表拆分、應用改造、擴容、事務一致性等問題怎么看都是非常吸引人的方案。
對于傳統企業例如銀行這種風險意識較高的行業來說,NewSQL數據庫則可能在未來一段時間內仍處于探索、審慎試點的階段。基于中間件+分庫分表模式架構簡單,技術門檻更低,雖然沒有NewSQL數據庫功能全面,但大部分場景最核心的訴求也就是拆分后SQL的正確路由,而此功能中間件模式應對還是綽綽有余的,可以說在大多數OLTP場景是夠用的。
限于篇幅,其它特性例如在線DDL、數據遷移、運維工具等特性就不在本文展開對比。
如果看完以上內容,您還不知道選哪種模式,那么結合以下幾個問題,先思考下NewSQL數據庫解決的點對于自身是不是真正的痛點:
強一致事務是否必須在數據庫層解決?
數據的增長速度是否不可預估的?
擴容的頻率是否已超出了自身運維能力?
相比響應時間更看重吞吐?
是否必須做到對應用完全透明?
是否有熟悉NewSQL數據庫的DBA團隊?
如果以上有2到3個是肯定的,那么你可以考慮用NewSQL數據庫了,雖然前期可能需要一定的學習成本,但它是數據庫的發展方向,未來收益也會更高,尤其是互聯網行業,隨著數據量的突飛猛進,分庫分表帶來的痛苦會與日俱增。當然選擇NewSQL數據庫你也要做好承擔一定風險的準備。
如果你還未做出抉擇,不妨再想想下面幾個問題:
最終一致性是否可以滿足實際場景?
數據未來幾年的總量是否可以預估?
擴容、DDL等操作是否有系統維護窗口?
對響應時間是否比吞吐更敏感?
是否需要兼容已有的關系數據庫系統?
是否已有傳統數據庫DBA人才的積累?
是否可容忍分庫分表對應用的侵入?
如果這些問題有多數是肯定的,那還是分庫分表吧。在軟件領域很少有完美的解決方案,NewSQL數據庫也不是數據分布式架構的銀彈。相比而言分庫分表是一個代價更低、風險更小的方案,它最大程度復用傳統關系數據庫生態,通過中間件也可以滿足分庫分表后的絕大多數功能,定制化能力更強。在當前NewSQL數據庫還未完全成熟的階段,分庫分表可以說是一個上限低但下限高的方案,尤其傳統行業的核心系統,如果你仍然打算把數據庫當做一個黑盒產品來用,踏踏實實用好分庫分表會被認為是個穩妥的選擇。
關于分庫分表和NewSQL數據庫的原理對比是什么就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





