溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關Kafka+Storm+Elasticsearch整合實時數據的示例分析,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
由于最近一個報文調閱系統的需求,在需求重,可能會涉及到報文數據的清洗落地,數據來源由網絡爬蟲實現(初步采用python scrapy實現),通過python-kafka發送MQ消息至本系統kafka服務,接收到消息后基于storm的KafkaSpout實現對數據的處理后統一落地至ES,詳細流程如下圖:
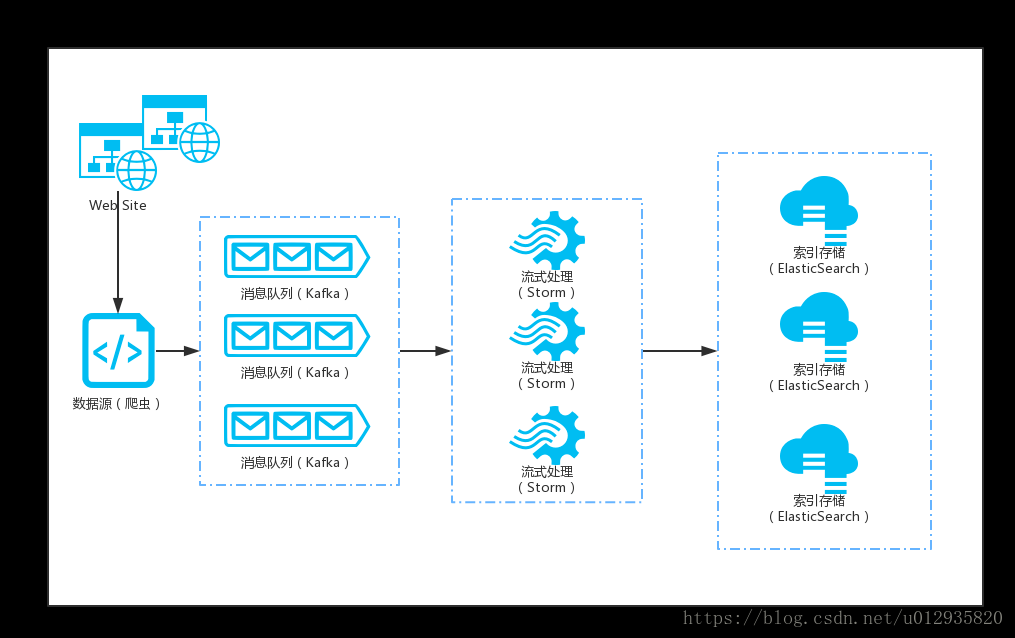
環境準備
由于環境有限,測試環境只提供了一個本地環境,即所有基于集群部署的服務均以LOCAL模式測試,具體集群部署,可參考其它資料,我這里只做代碼開發,最終應用不影響。
服務器:ubuntu server 17.10 JVM環境:jdk_1.8.0_91_64bit 服務治理:zookeeper-3.4.9 實時計算:apache-storm-1.2.2 消息隊列:kafka_2.11-2.0.0 索引存儲:elasticsearch-5.6.10 --------------------- 版權聲明:本文為CSDN博主「tanwei_」的原創文章,遵循CC 4.0 by-sa版權協議,轉載請附上原文出處鏈接及本聲明。 原文鏈接:https://blog.csdn.net/u012935820/article/details/82378609
應用開發
1、項目基于maven構建,依賴整個方便,項目架構如圖:
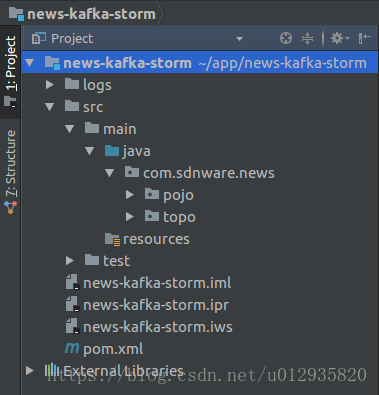
2、項目POM
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.sdnware.news</groupId>
<artifactId>news-kafka-storm</artifactId>
<version>1.0</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<junit.version>4.12</junit.version>
<kafka.version>2.0.0</kafka.version>
<storm.version>1.2.2</storm.version>
<storm-kafka.version>1.2.2</storm-kafka.version>
<storm-elasticsearch.version>1.2.2</storm-elasticsearch.version>
<lombok.version>1.18.2</lombok.version>
<gson.version>2.8.5</gson.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>${kafka.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
<!-- 當打包部署時, scope需設置為provided -->
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>${gson.version}</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>${storm-kafka.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-elasticsearch</artifactId>
<version>${storm-elasticsearch.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>com.sdnware.news.topo.KafkaTopology</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>3、基于storm-kafka的開發
注:在storm1.x以前,官方提供了storm-kafka的maven插件開發,在1.x以后雖然可用,但已經過期了,官方推薦storm-kafka-client來做開發,也是非常方便。
在開發storm實現,我們基本是針對一個topology來開發業務,本例中直接編寫KafkaTopology:
package com.sdnware.news.topo;
import com.google.gson.Gson;
import com.sdnware.news.pojo.UserInfo;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.elasticsearch.bolt.EsIndexBolt;
import org.apache.storm.elasticsearch.common.DefaultEsTupleMapper;
import org.apache.storm.elasticsearch.common.EsConfig;
import org.apache.storm.elasticsearch.common.EsTupleMapper;
import org.apache.storm.kafka.spout.KafkaSpout;
import org.apache.storm.kafka.spout.KafkaSpoutConfig;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Properties;
import java.util.UUID;
/**
* Created by sdnware on 18-8-31.
*/
public class KafkaTopology {
public static void main(String[] args) throws Exception{
/** 這里只是基于storm-kafka編寫的一段偽代碼:
BrokerHosts zkHosts = new ZkHosts(ZK_HOSTS);
SpoutConfig config = new SpoutConfig(zkHosts, KAFKA_TOPIC, ZK_ROOT + KAFKA_TOPIC,
UUID.randomUUID().toString());
config.scheme = new SchemeAsMultiScheme(new StringScheme());
config.zkServers = Arrays.asList(ZK_SERVERS.split(","));
config.zkPort = ZK_PORT;
config.socketTimeoutMs = socketTimeoutMs; **/
TopologyBuilder topologyBuilder = new TopologyBuilder(); // 定義topo構造器
Properties properties = new Properties();
properties.setProperty("group.id", "test-news-topic"); // kafka server的基本配置
// 定義一個KafkaSpoutConfig
KafkaSpoutConfig<String, String> kafkaSpoutConfig = KafkaSpoutConfig.builder("192.168.100.39:9092",
"news-topic")
.setFirstPollOffsetStrategy(KafkaSpoutConfig.FirstPollOffsetStrategy.UNCOMMITTED_EARLIEST)
.setProp(properties).build();
KafkaSpout<String, String> kafkaSpout = new KafkaSpout<>(kafkaSpoutConfig); // KafkaSpout實現
topologyBuilder.setSpout("kafka-spout", kafkaSpout, 1); // 注入Spout
topologyBuilder.setBolt("kafka-bolt", new NewsBlot(), 1).shuffleGrouping("kafka-spout"); // 通過storm獲取kafka-spout數據
EsConfig esConfig = new EsConfig(new String[]{"http://192.168.100.39:9200"}); // 定義一個ES的配置信息
EsTupleMapper esTupleMapper = new DefaultEsTupleMapper(); // 定義ES的默認映射
EsIndexBolt indexBolt = new EsIndexBolt(esConfig, esTupleMapper); //定義一個索引Bolt
topologyBuilder.setBolt("es-bolt", indexBolt, 1).shuffleGrouping("kafka-bolt"); // 向topology注入indexBolt以處理kafka-bolt的數據
// 提交到storm集群
Config config = new Config();
config.setMessageTimeoutSecs(90);
if (args.length > 0) { // 集群模式
config.setDebug(false);
StormSubmitter.submitTopology(args[0],
config, topologyBuilder.createTopology());
} else { // 本地測試模式,一般測試使用這個
// config.setDebug(true);
config.setNumWorkers(2);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("local-kafka-storm-topology",
config, topologyBuilder.createTopology());
}
}
// 自定義處理一個kafka的消息映射Bolt
static class NewsBlot extends BaseBasicBolt {
// 當有消息時執行,封裝消息發送,格式與定義輸出字段一一對應declarer.declare(xxx)
public void execute(Tuple input, BasicOutputCollector collector) {
// System.err.println(input.getValues());
String id = UUID.randomUUID().toString();
UserInfo userInfo = new UserInfo();
userInfo.setId(id);
userInfo.setUsername("tanwei");
userInfo.setPassword("sdnware");
Gson gson = new Gson();
String source = gson.toJson(userInfo);
collector.emit(new Values(source, "idx_sys", "tb_user", id));
}
// 定義消息發送的字段映射,這里是EsTupleMapper所需要的字段映射邏輯,可跟蹤源代碼理解
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("source", "index", "type", "id"));
}
}
}在上面代碼中,有些人可能會很疑惑,為什么沒有看到storm的配置?代碼運行就能找到storm嗎,這個我第一次開發時也很疑惑,后面跟蹤源碼,發現所有storm配置都是基于storm-core這個包中的defaults.yaml來運行的,具體修改參照官方說明,我這里是本地測試,所以不影響測試。
在NewsBlot這個類中execute方法,由于是接受到kafka的消息,默認Tuple是一個List,包含了kafka的topic、group、offset、message信息,正式環境我們需要按業務需求封裝message為一個我們所要存儲到ES中的數據格式,這里測試我簡單模擬了一個NewsInfo對象信息存儲,一般ES的source是一個json格式,key表示ES中的字段,value即為對應值。
后記
由于只是簡單寫了一個demo,大概介紹了其基本實現,在整個報文系統中,需要考慮到數據的定向分組消費等問題,總之,萬變不離其宗,多看源碼,豁然開朗。
以上就是Kafka+Storm+Elasticsearch整合實時數據的示例分析,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





