溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Spark基礎面試題有哪些”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
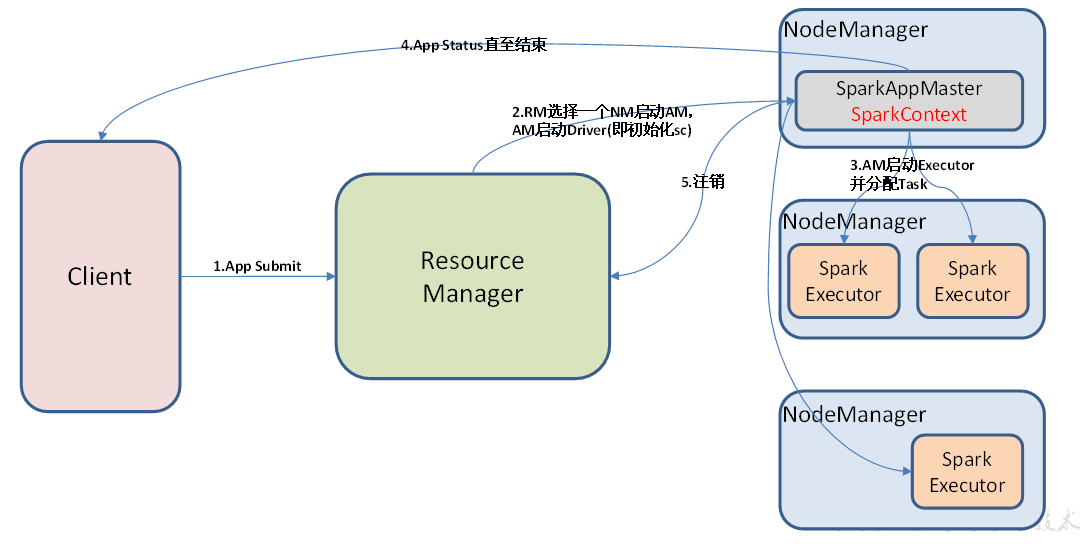
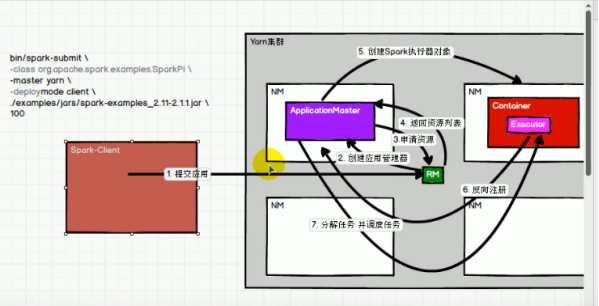
兩張圖一起看,左側圖是簡化版,右側圖較完整。
YARN-Cluster任務提交流程:
1 由client向RM提交請求,并上傳jar到HDFS上 ;
2 RM選擇一個NM創建SparkAppMaster(AM),AM啟動Driver(即初始化sc);
3 AM向RM申請資源;
4 RM給AM返回資源列表;
5 AM申請啟動Executor;
6 Executor向AM反向注冊;
Executor反向注冊完成后,AM就會知道自己有哪些資源可以用(Executor),然后就會去執行job,拆分stage,提交stage的Task,進行Task調度,分配到Executor上去執行;
7 AM分配任務給Executor執行,Executor執行任務,并向AM匯報運行的狀態和進度;
8 等到所有的任務執行完畢后,AM 向 RM 申請注銷并關閉自己,釋放資源 ;
參考鏈接:https://www.jianshu.com/p/e1cf4c58ae35
Yarn模式,Spark客戶端直接連接Yarn,不需要額外構建Spark集群。有yarn-client和yarn-cluster兩種模式,區別如下:
① 主要區別在于:Driver程序的運行節點
yarn-client:Driver程序運行在客戶端(本地),適用于交互、調試,希望立即看到app的輸出
yarn-cluster:Driver程序運行在由RM(ResourceManager)啟動的AP(APPMaster),適用于生產環境。
② Driver的位置不同導致的性能的差異
Yarn-client的Driver運行在本地,通常來說本地機器和Yarn集群不在同一個機房,性能不會很好;
yarn-cluster的Driver和Yarn集群運行在同一個機房內,性能上來說會好一點;
參考鏈接:https://www.jianshu.com/p/6f55b8412f03

2.1 未經過優化的HashShuffleManager
假設前提:每個Executor只有1個CPU core,也就是說,無論這個Executor上分配多少個task線程,同一時間都只能執行一個task線程。
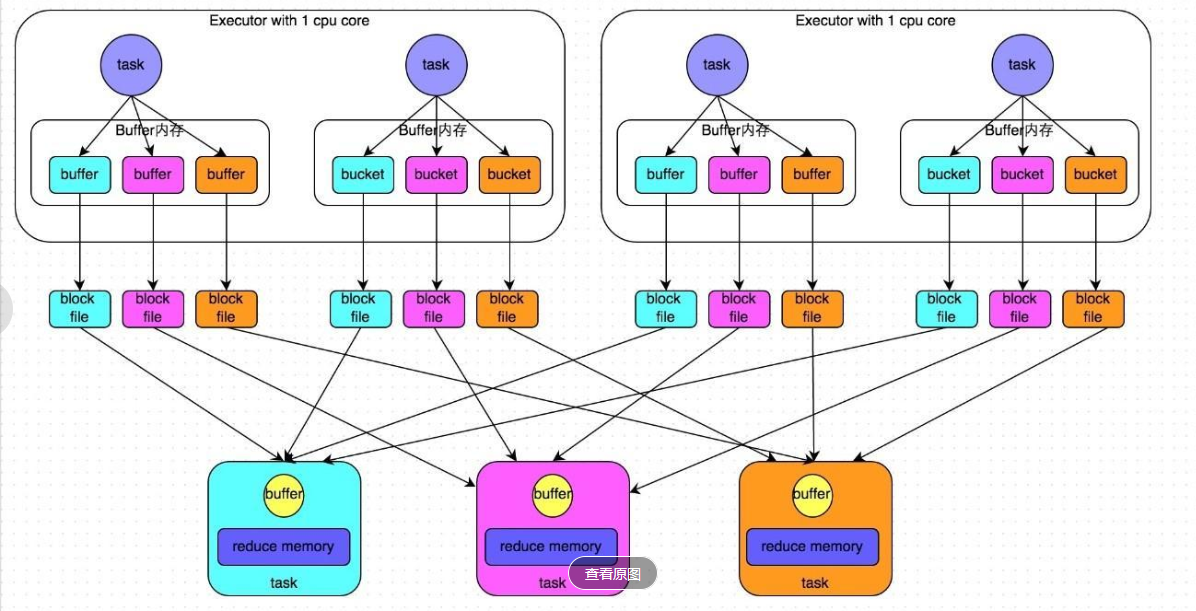
上游的stage的task對相同的key執行hash算法,從而將相同的key都寫入到一個磁盤文件中,而每一個磁盤文件都只屬于下游stage的一個task。在將數據寫入磁盤之前,會先將數據寫入到內存緩沖,當內存緩沖填滿之后,才會溢寫到磁盤文件中。但是這種策略的不足在于,下游有幾個task,上游的每一個task都就都需要創建幾個臨時文件,每個文件中只存儲key取hash之后相同的數據,導致了當下游的task任務過多的時候,上游會堆積大量的小文件 。
具體的過程分為“寫過程”和“讀過程”,參看上面的鏈接。
2.2 經過優化的HashShuffleManager
假設前提:每個Executor只有1個CPU core,也就是說,無論這個Executor上分配多少個task線程,同一時間都只能執行一個task線程。
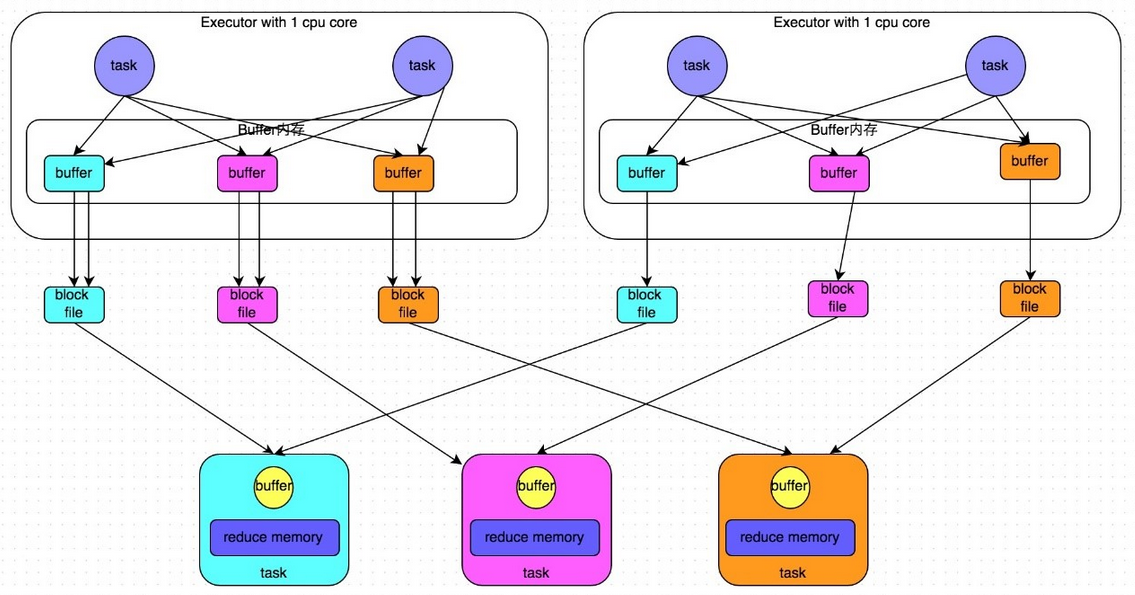
Shuffle Write過程:
開啟consolidate機制之后,在shuffle write過程中,task就不是為下游stage的每個task創建一個磁盤文件了。此時會出現shuffleFileGroup的概念,每個shuffleFileGroup會對應一批磁盤文件,磁盤文件的數量與下游stage的task數量是相同的。一個Executor上有多少個CPU core,就可以并行執行多少個task。而第一批并行執行的每個task都會創建一個shuffleFileGroup,并將數據寫入對應的磁盤文件內。
當Executor的CPU core執行完一批task,接著執行下一批task時,下一批task就會復用之前已有的shuffleFileGroup,包括其中的磁盤文件。也就是說,此時task會將數據寫入已有的磁盤文件中,而不會寫入新的磁盤文件中。因此,consolidate機制允許不同的task復用同一批磁盤文件,這樣就可以有效將多個task的磁盤文件進行一定程度上的合并,從而大幅度減少磁盤文件的數量,進而提升shuffle write的性能。
Shuffle Read過程:
和未優化之前的Shuffle Read過程相同。
SortShuffleManager的運行機制主要分成兩種,一種是普通運行機制,另一種是bypass運行機制。當shuffle read task的數量小于等于spark.shuffle.sort.bypassMergeThreshold參數的值時(默認為200),就會啟用bypass機制。
2.3 SortShuffleManager普通運行機制
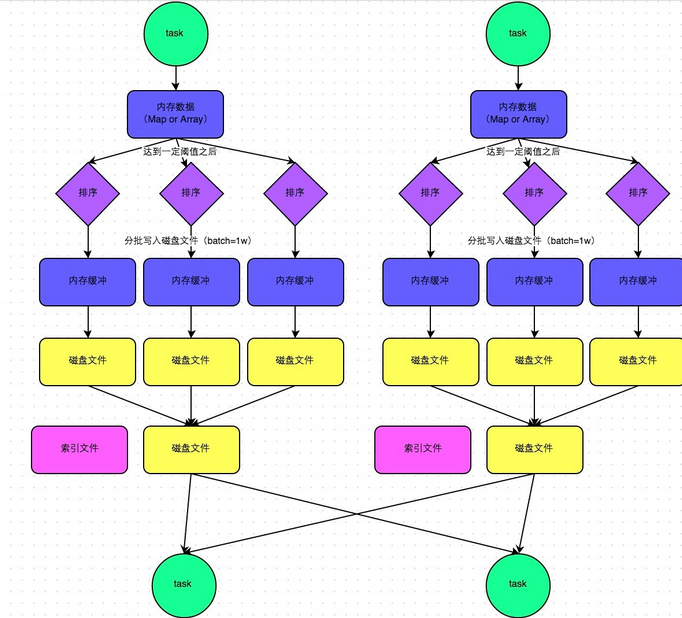
Shuffle Write過程:
在該模式下,數據會先寫入一個內存數據結構中,此時根據不同的shuffle算子,可能選用不同的數據結構。如果是reduceByKey這種聚合類的shuffle算子,那么會選用Map數據結構,一邊通過Map進行聚合,一邊寫入內存;如果是join這種普通的shuffle算子,那么會選用Array數據結構,直接寫入內存。接著,每寫一條數據進入內存數據結構之后,就會判斷一下,是否達到了某個臨界閾值。如果達到臨界閾值的話,那么就會嘗試將內存數據結構中的數據溢寫到磁盤,然后清空內存數據結構。
在溢寫到磁盤文件之前,會先根據key對內存數據結構中已有的數據進行排序。排序過后,會分批將數據寫入磁盤文件。默認的batch數量是10000條,也就是說,排序好的數據,會以每批1萬條數據的形式分批寫入磁盤文件。寫入磁盤文件是通過Java的BufferedOutputStream實現的。BufferedOutputStream是Java的緩沖輸出流,首先會將數據緩沖在內存中,當內存緩沖滿溢之后再一次寫入磁盤文件中,這樣可以減少磁盤IO次數,提升性能。
一個task將所有數據寫入內存數據結構的過程中,會發生多次磁盤溢寫操作,也就會產生多個臨時文件。最后會將之前所有的臨時磁盤文件都進行合并,這就是merge過程,此時會將之前所有臨時磁盤文件中的數據讀取出來,然后依次寫入最終的磁盤文件之中。此外,由于一個task就只對應一個磁盤文件,也就意味著該task為下游stage的task準備的數據都在這一個文件中,因此還會單獨寫一份索引文件,其中標識了下游各個task的數據在文件中的start offset與end offset。
產生中間文件數量:SortShuffleManager由于有一個磁盤文件merge的過程,因此大大減少了文件數量。比如第一個stage有50個task,總共有10個Executor,每個Executor執行5個task,而第二個stage有100個task。由于每個task最終只有一個磁盤文件,因此此時每個Executor上只有5個磁盤文件,所有Executor只有50個磁盤文件。
2.4 SortShuffleManager的bypass機制
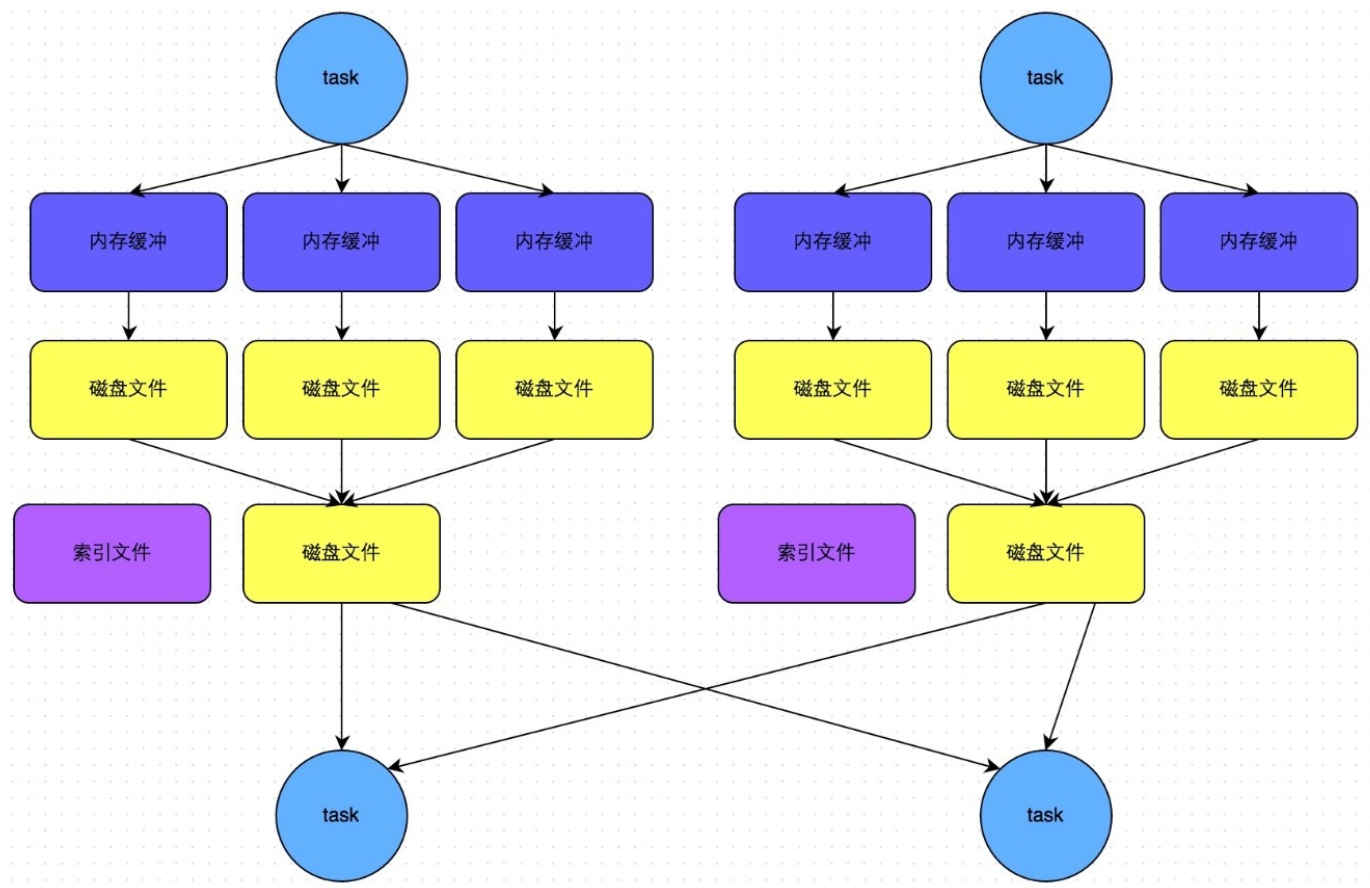
Shuffle Write過程:
此時task會為每個下游task都創建一個臨時磁盤文件,并將數據按key進行hash然后根據key的hash值,將key寫入對應的磁盤文件之中。當然,寫入磁盤文件時也是先寫入內存緩沖,緩沖寫滿之后再溢寫到磁盤文件的。最后,同樣會將所有臨時磁盤文件都合并成一個磁盤文件,并創建一個單獨的索引文件。
該過程的磁盤寫機制其實跟未經優化的HashShuffleManager是一模一樣的,因為都要創建數量驚人的磁盤文件,只是在最后會做一個磁盤文件的合并而已。因此少量的最終磁盤文件,也讓該機制相對未經優化的HashShuffleManager來說,shuffle read的性能會更好。
而該機制與普通SortShuffleManager運行機制的不同在于:第一,磁盤寫機制不同;第二,不會進行排序。也就是說,啟用該機制的最大好處在于,shuffle write過程中,不需要進行數據的排序操作,也就節省掉了這部分的性能開銷。
“Spark基礎面試題有哪些”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





