溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“MySQL基礎面試題有哪些”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“MySQL基礎面試題有哪些”吧!
什么是關系型數據庫?
關系型數據庫,是指采用了關系模型來組織數據的數據庫,其以行和列的形式存儲數據,以便于用戶理解,關系型數據庫這一系列的行和列被稱為表,一組表組成了數據庫。用戶通過查詢來檢索數據庫中的數據,而查詢是一個用于限定數據庫中某些區域的執行代碼。
簡單來說,關系模式就是二維表格模型。

二維表數據庫
關系型數據庫有什么優勢?
關系型數據庫的優勢:
易于理解
關系型二維表的結構非常貼近現實世界,二維表格,容易理解。
支持復雜查詢可以用 SQL 語句方便的在一個表以及多個表之間做非常復雜的數據查詢。
支持事務可靠的處理事務并且保持事務的完整性,使得對于安全性能很高的數據訪問要求得以實現。
MySQL數據庫
什么是SQL
結構化查詢語言 (Structured Query Language) 簡稱SQL,是一種特殊目的的編程語言,是一種數據庫查詢和程序設計語言程序設計語言,用于存取數據以及查詢、更新和管理關系數據庫系統。
什么是MySQL?
MySQL 是一個關系型數據庫管理系統,MySQL 是最流行的關系型數據庫管理系統之一,常見的關系型數據庫還有 Oracle 、SQL Server、Access 等等。
MySQL在過去由于性能高、成本低、可靠性好,已經成為最流行的開源數據庫,廣泛地應用在 Internet 上的中小型網站中。

mysql圖標
MySQL 和 MariaDB 傻傻分不清楚?
MySQL 最初由瑞典 MySQL AB 公司開發,MySQL 的創始人是烏爾夫·米卡埃爾·維德紐斯,常用昵稱蒙提(Monty)。
在被甲骨文公司收購后,現在屬于甲骨文公司(Oracle) 旗下產品。Oracle 大幅調漲MySQL商業版的售價,因此導致自由軟件社區們對于Oracle是否還會持續支持MySQL社區版有所隱憂。
MySQL 的創始人就是之前那個叫 Monty 的大佬以 MySQL為基礎成立分支計劃 MariaDB。
MariaDB打算保持與MySQL的高度兼容性,確保具有庫二進制奇偶校驗的直接替換功能,以及與MySQL API 應用程序接口)和命令的精確匹配。而原先一些使用 MySQL 的開源軟件逐漸轉向 MariaDB 或其它的數據庫。
所以如果看到你公司用的是 MariaDB 不用懷疑,其實它骨子里還是 MySQL,學會了MySQL 也就會了 MariaDB。
一個彩蛋
MariaDB 是以 Monty 的小女兒Maria命名的,就像MySQL是以他另一個女兒 My 命名的一樣,兩款鼎鼎大名的數據庫分別用兩個女兒的名字命名,你大爺還是你大爺,老爺子牛批!

MySQL之父
如何查看MySQL當前版本號?
在系統命令行下:mysql -V
連接上MySQL命令行輸入:
> status;
Server: MySQL Server version: 5.5.45 Protocol version: 10
或 select version();
+------------------------+ | version() | +------------------------+ | 5.5.45-xxxxx | +------------------------+
基礎數據類型
MySQL 有哪些數據類型?
MySQL 數據類型非常豐富,常用類型簡單介紹如下:
整數類型:BIT、BOOL、TINY INT、SMALL INT、MEDIUM INT、 INT、 BIG INT
浮點數類型:FLOAT、DOUBLE、DECIMAL
字符串類型:CHAR、VARCHAR、TINY TEXT、TEXT、MEDIUM TEXT、LONGTEXT、TINY BLOB、BLOB、MEDIUM BLOB、LONG BLOB
日期類型:Date、DateTime、TimeStamp、Time、Year
其他數據類型:BINARY、VARBINARY、ENUM、SET...
CHAR 和 VARCHAR的區別?
CHAR 是固定長度的字符類型,VARCHAR 則是可變長度的字符類型,下面討論基于在 MySQL5.0 以上版本中。
共同點
CHAR(M) 和 VARCHAR(M) 都表示該列能存儲 M 個字符,注意不是字節!!
CHAR類型特點
CHAR 最多可以存儲 255 個字符 (注意不是字節),字符有不同的編碼集,比如 UTF8 編碼 (3字節)、GBK 編碼 (2字節) 等。
對于 CHAR(M) 如果實際存儲的數據長度小于M,則 MySQL 會自動會在它的右邊用空格字符補足,但是在檢索操作中那些填補出來的空格字符會被去掉。
VARCHAR類型特點
VARCHAR 的最大長度為 65535 個字節。
VARCHAR 存儲的是實際的字符串加1或2個字節用來記錄字符串實際長度,字符串長度小于255字節用1字節記錄,超過255就需要2字節記錄。[^12 ]
VARCHAR(50) 能存放幾個 UTF8 編碼的漢字?
存放的漢字個數與版本相關。
mysql 4.0以下版本,varchar(50) 指的是 50 字節,如果存放 UTF8 格式編碼的漢字時(每個漢字3字節),只能存放16 個。
mysql 5.0以上版本,varchar(50) 指的是 50 字符,無論存放的是數字、字母還是 UTF8 編碼的漢字,都可以存放 50 個。
int(10) 和 bigint(10)能存儲的數據大小一樣嗎?
不一樣,具體原因如下:
int 能存儲四字節有符號整數。
bigint 能存儲八字節有符號整數。
所以能存儲的數據大小不一樣,其中的數字 10 代表的只是數據的顯示寬度。[^13]
顯示寬度指明Mysql最大可能顯示的數字個數,數值的位數小于指定的寬度時數字左邊會用空格填充,空格不容易看出。
如果插入了大于顯示寬度的值,只要該值不超過該類型的取值范圍,數值依然可以插入且能夠顯示出來。
建表的時候指定 zerofill 選項,則不足顯示寬度的部分用 0 填充,如果是 1 會顯示成 0000000001。
如果沒指定顯示寬度, bigint 默認寬度是 20 ,int默認寬度 11。
存儲引擎相關
MySQL存儲引擎類型有哪些?
常用的存儲引擎有 InnoDB 存儲引擎和 MyISAM 存儲引擎,InnoDB 是 MySQL 的默認事務引擎。
查看數據庫表當前支持的引擎,可以用下面查詢語句查看 :
# 查詢結果表中的 Engine 字段指示存儲引擎類型。 show table status from 'your_db_name' where name='your_table_name';
InnoDB存儲引擎應用場景是什么?
InnoDB 是 MySQL的默認「事務引擎」,被設置用來處理大量短期(short-lived)事務,短期事務大部分情況是正常提交的,很少會回滾。
InnoDB存儲引擎特性有哪些?
采用多版本并發控制(MVCC,MultiVersion Concurrency Control)來支持高并發。并且實現了四個標準的隔離級別,通過間隙鎖next-key locking策略防止幻讀的出現。
引擎的表基于聚簇索引建立,聚簇索引對主鍵查詢有很高的性能。不過它的二級索引secondary index非主鍵索引中必須包含主鍵列,所以如果主鍵列很大的話,其他的所有索引都會很大。因此,若表上的索引較多的話,主鍵應當盡可能的小。另外InnoDB的存儲格式是平臺獨立。
InnoDB做了很多優化,比如:磁盤讀取數據方式采用的可預測性預讀、自動在內存中創建hash索引以加速讀操作的自適應哈希索引(adaptive hash index),以及能夠加速插入操作的插入緩沖區(insert buffer)等。
InnoDB通過一些機制和工具支持真正的熱備份,MySQL 的其他存儲引擎不支持熱備份,要獲取一致性視圖需要停止對所有表的寫入,而在讀寫混合場景中,停止寫入可能也意味著停止讀取。
InnoDB 引擎的四大特性是什么?
插入緩沖(Insert buffer)
Insert Buffer 用于非聚集索引的插入和更新操作。先判斷插入的非聚集索引是否在緩存池中,如果在則直接插入,否則插入到 Insert Buffer 對象里。再以一定的頻率進行 Insert Buffer 和輔助索引葉子節點的 merge 操作,將多次插入合并到一個操作中,提高對非聚集索引的插入性能。
二次寫 (Double write)
Double Write由兩部分組成,一部分是內存中的double write buffer,大小為2MB,另一部分是物理磁盤上共享表空間連續的128個頁,大小也為 2MB。在對緩沖池的臟頁進行刷新時,并不直接寫磁盤,而是通過 memcpy 函數將臟頁先復制到內存中的該區域,之后通過doublewrite buffer再分兩次,每次1MB順序地寫入共享表空間的物理磁盤上,然后馬上調用fsync函數,同步磁盤,避免操作系統緩沖寫帶來的問題。
自適應哈希索引 (Adaptive Hash Index)
InnoDB會根據訪問的頻率和模式,為熱點頁建立哈希索引,來提高查詢效率。索引通過緩存池的 B+ 樹頁構造而來,因此建立速度很快,InnoDB存儲引擎會監控對表上各個索引頁的查詢,如果觀察到建立哈希索引可以帶來速度上的提升,則建立哈希索引,所以叫做自適應哈希索引。
緩存池
為了提高數據庫的性能,引入緩存池的概念,通過參數 innodb_buffer_pool_size 可以設置緩存池的大小,參數 innodb_buffer_pool_instances 可以設置緩存池的實例個數。緩存池主要用于存儲以下內容:
緩沖池中緩存的數據頁類型有:索引頁、數據頁、undo頁、插入緩沖 (insert buffer)、自適應哈希索引(adaptive hash index)、InnoDB存儲的鎖信息 (lock info)和數據字典信息 (data dictionary)。
MyISAM存儲引擎應用場景有哪些?
MyISAM 是 MySQL 5.1 及之前的版本的默認的存儲引擎。MyISAM 提供了大量的特性,包括全文索引、壓縮、空間函數(GIS)等,但MyISAM 不「支持事務和行級鎖」,對于只讀數據,或者表比較小、可以容忍修復操作,依然可以使用它。
MyISAM存儲引擎特性有哪些?
MyISAM「不支持行級鎖而是對整張表加鎖」。讀取時會對需要讀到的所有表加共享鎖,寫入時則對表加排它鎖。但在表有讀取操作的同時,也可以往表中插入新的記錄,這被稱為并發插入。
MyISAM 表可以手工或者自動執行檢查和修復操作。但是和事務恢復以及崩潰恢復不同,可能導致一些「數據丟失」,而且修復操作是非常慢的。
對于 MyISAM 表,即使是BLOB和TEXT等長字段,也可以基于其前 500 個字符創建索引,MyISAM 也支持「全文索引」,這是一種基于分詞創建的索引,可以支持復雜的查詢。
如果指定了DELAY_KEY_WRITE選項,在每次修改執行完成時,不會立即將修改的索引數據寫入磁盤,而是會寫到內存中的鍵緩沖區,只有在清理鍵緩沖區或者關閉表的時候才會將對應的索引塊寫入磁盤。這種方式可以極大的提升寫入性能,但是在數據庫或者主機崩潰時會造成「索引損壞」,需要執行修復操作。
MyISAM 與 InnoDB 存儲引擎 5 大區別
InnoDB支持事物,而MyISAM不支持事物
InnoDB支持行級鎖,而MyISAM支持表級鎖
InnoDB支持MVCC, 而MyISAM不支持
InnoDB支持外鍵,而MyISAM不支持
InnoDB不支持全文索引,而MyISAM支持
一張表簡單羅列兩種引擎的主要區別,如下圖:
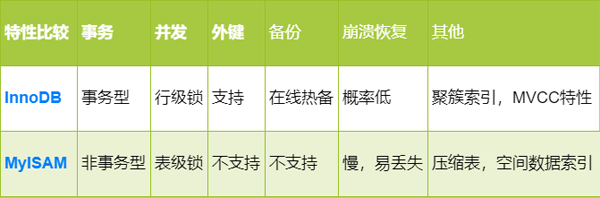
mysql引擎對比
SELECT COUNT(*) 在哪個引擎執行更快?
SELECT COUNT(*) 常用于統計表的總行數,在 MyISAM 存儲引擎中執行更快,前提是不能加有任何WHERE條件。
這是因為 MyISAM 對于表的行數做了優化,內部用一個變量存儲了表的行數,如果查詢條件沒有 WHERE 條件則是查詢表中一共有多少條數據,MyISAM 可以迅速返回結果,如果加 WHERE 條件就不行。
InnoDB 的表也有一個存儲了表行數的變量,但這個值是一個估計值,所以并沒有太大實際意義。
MySQL 基礎知識
說一下數據庫設計三范式是什么?
1范式:1NF是對屬性的原子性約束,要求屬性具有原子性,不可再分解;(只要是關系型數據庫都滿足1NF)
2范式:2NF是對記錄的惟一性約束,要求記錄有惟一標識,即實體的惟一性;
3范式:3NF是對字段冗余性的約束,即任何字段不能由其他字段派生出來,它要求字段沒有冗余。沒有冗余的數據庫設計可以做到
但是,沒有冗余的數據庫未必是最好的數據庫,有時為了提高運行效率,就必須降低范式標準,適當保留冗余數據,具體做法是:在概念數據模型設計時遵守第三范式,降低范式標準的工作放到物理數據模型設計時考慮,降低范式就是增加字段,允許冗余。
SQL 語句有哪些分類?
鴻蒙官方戰略合作共建——HarmonyOS技術社區
DDL:數據定義語言(create alter drop)
DML:數據操作語句(insert update delete)
DTL:數據事務語句(commit collback savapoint)
DCL:數據控制語句(grant revoke)
數據庫刪除操作中的 delete、drop、 truncate 區別在哪?
當不再需要該表時可以用 drop 來刪除表;
當仍要保留該表,但要刪除所有記錄時, 用 truncate來刪除表中記錄。
當要刪除部分記錄時(一般來說有 WHERE 子句約束) 用 delete來刪除表中部分記錄。
什么是MySql視圖?
視圖是虛擬表,并不儲存數據,只包含定義時的語句的動態數據。
創建視圖語法:
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] [DEFINER = user] [SQL SECURITY { DEFINER | INVOKER }] VIEW view_name [(column_list)] AS select_statement [WITH [CASCADED | LOCAL] CHECK OPTION]參數說明:
OR REPLACE:如果視圖存在,則替換已有視圖。
ALGORITHM:視圖選擇算法,默認算法是 UNDEFINED(未定義的)由 MySQL自動選擇要使用的算法。
DEFINER:指定視圖創建者或定義者,如果不指定該選項,則創建視圖的用戶就是定義者。
SQL SECURITY:SQL安全性,默認為DEFINER。
select_statement:創建視圖的 SELECT語句,可以從基表或其他視圖中選擇數據。
WITH CHECK OPTION:表示視圖在更新時保證約束,默認是 CASCADED。
使用 MySQL 視圖有何優點?
鴻蒙官方戰略合作共建——HarmonyOS技術社區
操作簡單方便。視圖用戶完全不需要關心視圖對應的表的結構、關聯條件和篩選條件,對用戶來說已經是過濾好的復合條件的結果集。
數據更加安全。視圖用戶只能訪問視圖中的結果集,通過視圖可以把對表的訪問權限限制在某些行和列上面。
數據隔離。屏蔽了源表結構變化對用戶帶來的影響,源表結構變化視圖結構不變。^1
MySql服務默認端口號是多少 ?
默認端口是 3306
查看端口命令:> show variables like 'port';
用 DISTINCT 過濾 多列的規則?
DISTINCT 用于對選擇的數據去重,單列用法容易理解。比如有如下數據表 tamb:
name number Tencent 1 Alibaba 2 Bytedance 3 Meituan 3
查詢語句:SELECT DISTINCT name FROM table tamb 結果如下:
name Tencent Alibaba Bytedance Meituan
如果要求按 number 列去重同時顯示 name ,你可能會寫出查詢語句:
SELECT DISTINCT number, name FROM table tamb
多參數 DISTINCT 去重規則是:把 DISTINCT 之后的所有參數當做一個過濾條件,也就是說會對 (number, name)整體去重處理,只有當這個組合不同才會去重,結果如下:
number name 1 Tencent 2 Alibaba 3 Bytedance 3 Meituan
從結果來看好像并沒有達到我們想要的去重的效果,那要怎么實現「按 number 列去重同時顯示 name」呢?可以用 Group By 語句:
SELECT number, name FROM table tamb GROUP BY number 輸出如下,正是我們想要的效果:
number name 1 Tencent 2 Alibaba 3 Bytedance
什么是存儲過程?
一條或多條sql語句集合,有以下一些特點:
存儲過程能實現較快的執行速度。
存儲過程可以用流程控制語句編寫,有很強的靈活性,可以完成復雜的判斷和較復雜的運算。
存儲過程可被作為一種安全機制來充分利用。
存儲過程能夠減少網絡流量
delimiter 分隔符 create procedure|proc proc_name() begin sql語句 end 分隔符 delimiter ; --還原分隔符,為了不影響后面的語句的使用 --默認的分隔符是;但是為了能在整個存儲過程中重用,因此一般需要自定義分隔符(除\外) show procedure status like ""; --查詢存儲過程,可以不適用like進行過濾 drop procedure if exists;--刪除存儲過程
存儲過程和函數好像差不多,你說說他們有什么區別?
存儲過程和函數是事先經過編譯并存儲在數據庫中的一段 SQL 語句的集合,調用存儲過程和函數可以簡化應用開發人員的很多工作,減少數據在數據庫和應用服務器之間的傳輸,對于提高數據處理的效率是有好處的。
相同點
存儲過程和函數都是為了可重復的執行操作數據庫的 SQL 語句的集合。
存儲過程和函數都是一次編譯后緩存起來,下次使用就直接命中已經編譯好的 sql 語句,減少網絡交互提高了效率。
不同點
標識符不同,函數的標識符是 function,存儲過程是 procedure。
函數返回單個值或者表對象,而存儲過程沒有返回值,但是可以通過OUT參數返回多個值。
函數限制比較多,比如不能用臨時表,只能用表變量,一些函數都不可用等,而存儲過程的限制相對就比較少。
一般來說,存儲過程實現的功能要復雜一點,而函數的實現的功能針對性比較強
函數的參數只能是 IN 類型,存儲過程的參數可以是IN OUT INOUT三種類型。
存儲函數使用 select 調用,存儲過程需要使用 call 調用。
到此,相信大家對“MySQL基礎面試題有哪些”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





