溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Spark 框架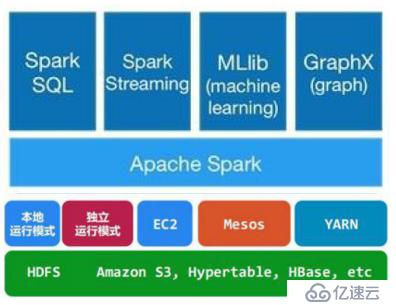
Spark與Storm的對比
對于Storm來說:
1、建議在那種需要純實時,不能忍受1秒以上延遲的場景下使用,比如實時金融系統,要求純實時進行金融交易和分析
2、此外,如果對于實時計算的功能中,要求可靠的事務機制和可靠性機制,即數據的處理完全精準,一條也不能多,一條也不能少,也可以考慮使用Storm
3、如果還需要針對高峰低峰時間段,動態調整實時計算程序的并行度,以最大限度利用集群資源(通常是在小型公司,集群資源緊張的情況),也可以考慮用Storm
4、如果一個大數據應用系統,它就是純粹的實時計算,不需要在中間執行SQL交互式查詢、復雜的transformation算子等,那么用Storm是比較好的選擇
對于Spark Streaming來說:
1、如果對上述適用于Storm的三點,一條都不滿足的實時場景,即,不要求純實時,不要求強大可靠的事務機制,不要求動態調整并行度,那么可以考慮使用Spark Streaming
2、考慮使用Spark Streaming最主要的一個因素,應該是針對整個項目進行宏觀的考慮,即,如果一個項目除了實時計算之外,還包括了離線批處理、交互式查詢等業務功能,而且實時計算中,可能還會牽扯到高延遲批處理、交互式查詢等功能,那么就應該首選Spark生態,用Spark Core開發離線批處理,用Spark SQL開發交互式查詢,用Spark Streaming開發實時計算,三者可以無縫整合,給系統提供非常高的可擴展性
Spark Streaming與Storm的優劣分析
事實上,Spark Streaming絕對談不上比Storm優秀。這兩個框架在實時計算領域中,都很優秀,只是擅長的細分場景并不相同。
Spark Streaming僅僅在吞吐量上比Storm要優秀,而吞吐量這一點,也是歷來挺Spark Streaming,貶Storm的人著重強調的。但是問題是,是不是在所有的實時計算場景下,都那么注重吞吐量?不盡然。因此,通過吞吐量說Spark Streaming強于Storm,不靠譜。
Storm在實時延遲度上,比Spark Streaming就好多了,前者是純實時,后者是準實時。而且,Storm的事務機制、健壯性 / 容錯性、動態調整并行度等特性,都要比Spark Streaming更加優秀。
Spark Streaming,有一點是Storm絕對比不上的,就是:它位于Spark生態技術棧中,因此Spark Streaming可以和Spark Core、Spark SQL無縫整合,也就意味著,我們可以對實時處理出來的中間數據,立即在程序中無縫進行延遲批處理、交互式查詢等操作。這個特點大大增強了Spark Streaming的優勢和功能
下載 spark、scala的包
如下操作:
[hadoop@oversea-stable ~]$ wget http://mirrors.hust.edu.cn/apache/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz
--2018-06-27 10:07:25-- http://mirrors.hust.edu.cn/apache/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz
Resolving mirrors.hust.edu.cn (mirrors.hust.edu.cn)... 202.114.18.160
Connecting to mirrors.hust.edu.cn (mirrors.hust.edu.cn)|202.114.18.160|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 226128401 (216M) [application/octet-stream]
Saving to: ‘spark-2.3.0-bin-hadoop2.7.tgz’
100%[================================================================================================================>] 226,128,401 45.4KB/s in 68m 12s
2018-06-27 11:15:38 (54.0 KB/s) - ‘spark-2.3.0-bin-hadoop2.7.tgz’ saved [226128401/226128401]
[hadoop@oversea-stable ~]$
[hadoop@oversea-stable ~]$ wget https://scala-lang.org/files/archive/nightly/2.12.x/scala-2.12.5-bin-3995c7e.tgz
--2018-06-27 11:50:02-- https://scala-lang.org/files/archive/nightly/2.12.x/scala-2.12.5-bin-3995c7e.tgz
Resolving scala-lang.org (scala-lang.org)... 128.178.154.159
Connecting to scala-lang.org (scala-lang.org)|128.178.154.159|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 20244926 (19M) [application/x-gzip]
Saving to: ‘scala-2.12.5-bin-3995c7e.tgz’
100%[================================================================================================================>] 20,244,926 516KB/s in 4m 39s
2018-06-27 11:54:43 (70.8 KB/s) - ‘scala-2.12.5-bin-3995c7e.tgz’ saved [20244926/20244926]配置環境變量
如下操作:
[hadoop@oversea-stable ~]$ tail -4 .bash_profile
export SCALA_HOME=/opt/scala
export SPARK_HOME=/opt/spark
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HBASE_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$PATH
export PATH
[hadoop@oversea-stable ~]$配置并同步scala
操作如下:
[hadoop@oversea-stable ~]$ tar xfz scala-2.12.5-bin-3995c7e.tgz -C /opt/
[hadoop@oversea-stable opt]$ ln -s scala-2.12.5-bin-3995c7e scala
[hadoop@oversea-stable opt]$ for((i=67;i>=64;i--));do rsync -avzoptlg scala-2.12.5-bin-3995c7e 192.168.20.$i:/opt/ ; done 配置并同步spark
操作如下:
[hadoop@oversea-stable ~]$ tar xfz spark-2.3.0-bin-hadoop2.7.tgz -C /opt/
[hadoop@oversea-stable ~]$ cd /opt/
[hadoop@oversea-stable opt]$ ln -s spark-2.3.0-bin-hadoop2.7 spark
[hadoop@oversea-stable opt]$ cd spark/conf
[hadoop@oversea-stable conf]$ pwd
/opt/spark/conf
[hadoop@oversea-stable conf]$ cp spark-env.sh{.template,}
[hadoop@oversea-stable conf]$ vim spark-env.sh
[hadoop@oversea-stable conf]$ tail -8 spark-env.sh
export SCALA_HOME=/opt/spark
export JAVA_HOME=/usr/java/latest
export SPARK_MASTER_IP=192.168.20.68
export SPARK_WORKER_MEMORY=1024m
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/opt/hadoop/bin/hadoop classpath)
export SPARK_LOCAL_IP=192.168.20.68 #修改為每個node本身的IP
export SPARK_MASTER_HOST=192.168.20.68
[hadoop@oversea-stable conf]$
[hadoop@oversea-stable conf]$ cp slaves{.template,}
[hadoop@oversea-stable conf]$ vim slaves
[hadoop@oversea-stable conf]$ tail -3 slaves
open-stable
permission-stable
sp-stable
[hadoop@oversea-stable conf]$
[hadoop@oversea-stable conf]$ cd /opt
[hadoop@oversea-stable opt]$ for((i=67;i>=64;i--));do rsync -avzoptlg spark-2.3.0-bin-hadoop2.7 192.168.20.$i:/opt/ ; done啟動spark
操作如下所示:
[hadoop@oversea-stable opt]$ cd spark
[hadoop@oversea-stable spark]$ sbin/start-slaves.sh
open-stable: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-open-stable.out
permission-stable: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-permission-stable.out
sp-stable: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-sp1-stable.out
[hadoop@oversea-stable spark]$ vim conf/slaves
[hadoop@oversea-stable spark]$ sbin/start-slaves.sh
open-stable: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-open-stable.out
permission-stable: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-permission-stable.out
[hadoop@oversea-stable spark]$驗證
(1) 檢查log,確認無Error
[hadoop@oversea-stable spark]$ cd logs
[hadoop@oversea-stable logs]$ ls
spark-hadoop-org.apache.spark.deploy.master.Master-1-oversea-stable.out
[hadoop@oversea-stable logs]$ (2) 查看各server 進程狀態
[hadoop@oversea-stable logs]$ jps
12480 DFSZKFailoverController
27522 HMaster
6738 Master
7301 Jps
12123 NameNode
12588 ResourceManager
[hadoop@oversea-stable logs]$
[hadoop@open-stable logs]$ jps
15248 JournalNode
15366 NodeManager
16248 Jps
16169 Worker
15131 DataNode
18125 QuorumPeerMain
22781 HRegionServer
[hadoop@open-stable logs]$
[hadoop@permission-stable logs]$ jps
12800 QuorumPeerMain
24391 NodeManager
4647 Jps
24152 DataNode
4568 Worker
2236 HRegionServer
24269 JournalNode
[hadoop@permission-stable logs]$
[hadoop@sp1-stable logs]$ jps
7617 QuorumPeerMain
9233 Jps
21683 NodeManager
21540 JournalNode
28966 HRegionServer
21451 DataNode
8813 Worker
[hadoop@sp1-stable logs]$(3) 運行spark-shell
[hadoop@oversea-stable logs]$ spark-shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/spark-2.3.0-bin-hadoop2.7/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop-2.9.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2018-06-27 15:15:49 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://oversea-stable:4040
Spark context available as 'sc' (master = local[*], app id = local-1530083761130).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.3.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_172)
Type in expressions to have them evaluated.
Type :help for more information.
scala> (4) 在web 瀏覽器中查看spark master 的狀態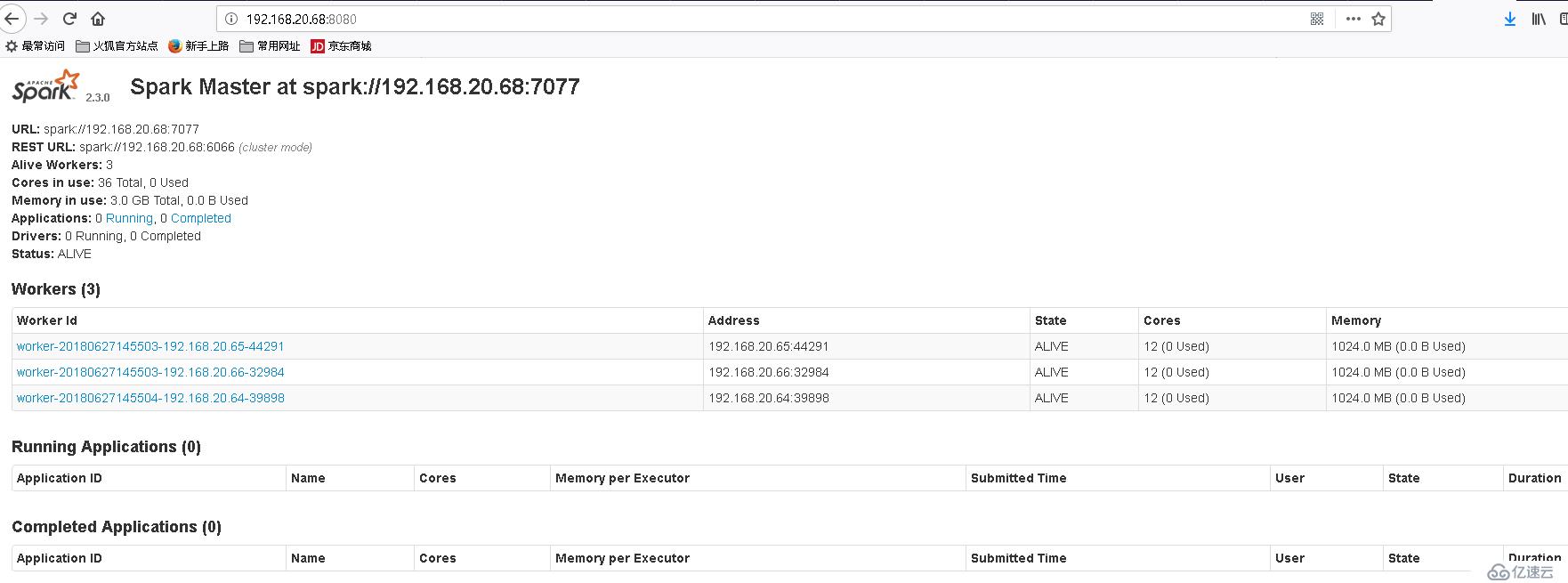
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





