溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Spark啟動時的master參數以及Spark的部署方法”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Spark啟動時的master參數以及Spark的部署方法”吧!
我們在初始化SparkConf時,或者提交Spark任務時,都會有master參數需要設置,如下:
conf = SparkConf().setAppName(appName).setMaster(master)
sc = SparkContext(conf=conf)
/bin/spark-submit \
--cluster cluster_name \
--master yarn-cluster \
...
但是這個master到底是何含義呢?文檔說是設定master url,但是啥是master url呢?說到這就必須先要了解下Spark的部署方式了。
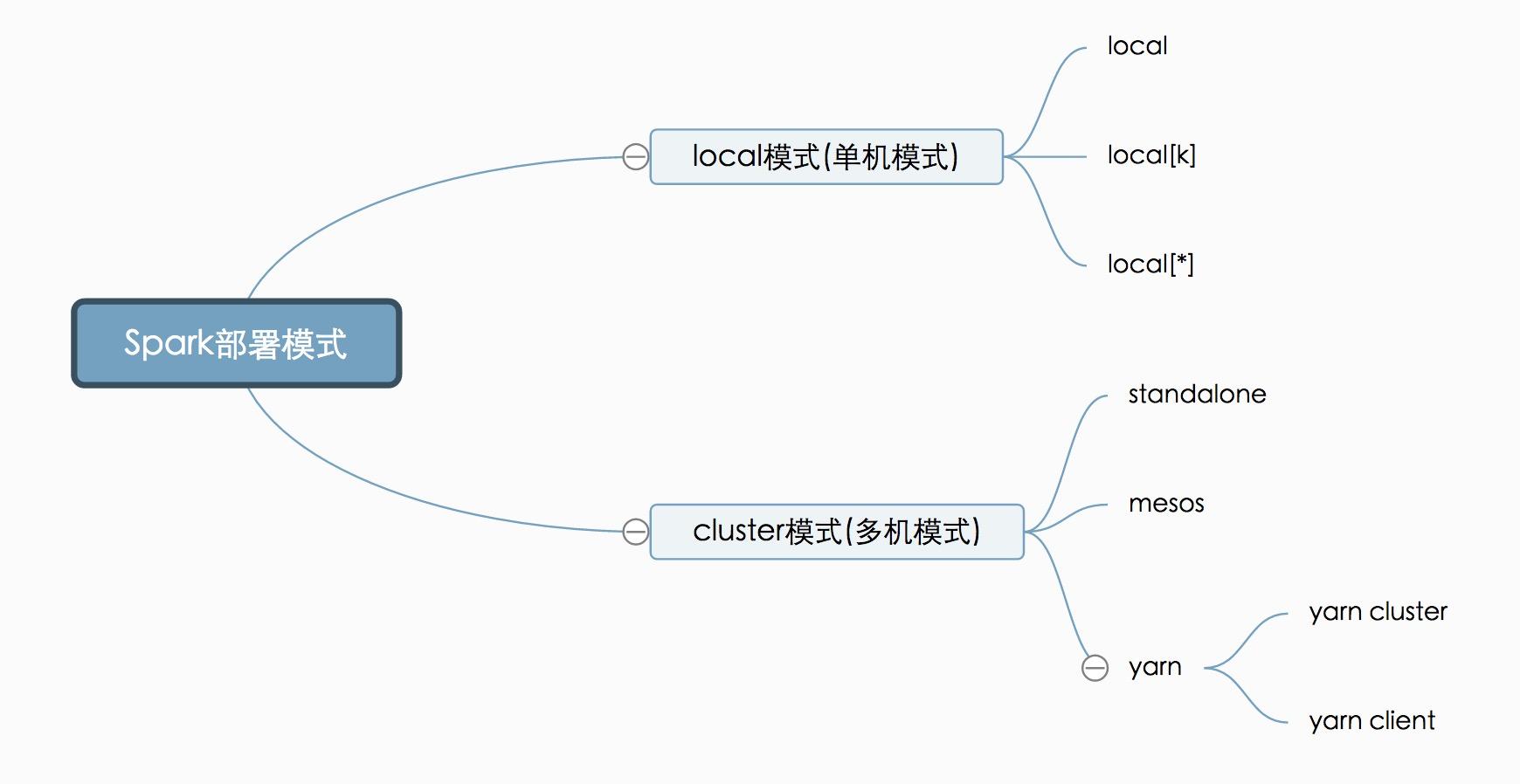
我們要部署Spark這套計算框架,有多種方式,可以部署到一臺計算機,也可以是多臺(cluster)。我們要去計算數據,就必須要有計算機幫我們計算,當然計算機越多(集群規模越大),我們的計算力就越強。但有時候我們只想在本機做個試驗或者小型的計算,因此直接部署在單機上也是可以的。Spark部署方式可以用如下圖形展示:
下面我們就來分別介紹下。
Local模式就是運行在一臺計算機上的模式,通常就是用于在本機上練手和測試。它可以通過以下集中方式設置master。
local: 所有計算都運行在一個線程當中,沒有任何并行計算,通常我們在本機執行一些測試代碼,或者練手,就用這種模式。
local[K]: 指定使用幾個線程來運行計算,比如local[4]就是運行4個worker線程。通常我們的cpu有幾個core,就指定幾個線程,最大化利用cpu的計算能力
local[*]: 這種模式直接幫你按照cpu最多cores來設置線程數了。
使用示例:
/bin/spark-submit \
--cluster cluster_name \
--master local[*] \
...
總而言之這幾種local模式都是運行在本地的單機版模式,通常用于練手和測試,而實際的大規模計算就需要下面要介紹的cluster模式。
cluster模式肯定就是運行很多機器上了,但是它又分為以下三種模式,區別在于誰去管理資源調度。(說白了,就好像后勤管家,哪里需要資源,后勤管家要負責調度這些資源)
這種模式下,Spark會自己負責資源的管理調度。它將cluster中的機器分為master機器和worker機器,master通常就一個,可以簡單的理解為那個后勤管家,worker就是負責干計算任務活的苦勞力。具體怎么配置可以參考Spark Standalone Mode
使用standalone模式示例:
/bin/spark-submit \
--cluster cluster_name \
--master spark://host:port \
...
--master就是指定master那臺機器的地址和端口,我想這也正是--master參數名稱的由來吧。
這里就很好理解了,如果使用mesos來管理資源調度,自然就應該用mesos模式了,示例如下:
/bin/spark-submit \
--cluster cluster_name \
--master mesos://host:port \
...
同樣,如果采用yarn來管理資源調度,就應該用yarn模式,由于很多時候我們需要和mapreduce使用同一個集群,所以都采用Yarn來管理資源調度,這也是生產環境大多采用yarn模式的原因。yarn模式又分為yarn cluster模式和yarn client模式:
yarn cluster: 這個就是生產環境常用的模式,所有的資源調度和計算都在集群環境上運行。
yarn client: 這個是說Spark Driver和ApplicationMaster進程均在本機運行,而計算任務在cluster上。
使用示例:
/bin/spark-submit \
--cluster cluster_name \
--master yarn-cluster \
...
感謝各位的閱讀,以上就是“Spark啟動時的master參數以及Spark的部署方法”的內容了,經過本文的學習后,相信大家對Spark啟動時的master參數以及Spark的部署方法這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。