溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何分析POSTGRESQL FULL PAGE優化與CHECKPOINT的矛盾,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
在說完mysql 不要關DW 后,祭出 POSTGRESQL FULL PAGE 的確是有點不厚道,所以必然會引出 FULL PAGE 也存在性能問題的話題。到底是大公雞和大馬猴的問題,還是小綿羊的牧羊犬的故事。
首先FULL PAGE 和 MYSQL的 DW 一樣,都是為了解決數據庫CRASH 時數據的那一刻存在的缺失問題。我看來看看相關的解釋
PostgreSQL 在 checkpoint 之后在對數據頁面的第一次寫的時候會將整個數據頁面寫到 xlog 里面。當出現主機斷電或者OS崩潰時,redo操作時通過checksum發現“部分寫”的數據頁,并將xlog中保存的這個完整數據頁覆蓋當前損壞的數據頁,然后再繼續redo就可以恢復整個數據庫了。
看完以后會突然冒出一個想法
1 checkpoint 越密集,那FULL PAGE 也就越多咯
2 FULL PAGE 第一個頁面的大小會影響寫性能
那我關掉FULL PAGE 不就好了
當然不是,FULL PAGE 在某些時候,不是你要開就開,要關就關的,尤其你在操作 pg_basebackup(或者一連串利用這命令的偽裝者們)的操作時 FULL PAGE 是強制打開的,到底為什么這就不解釋了,和 備份的原理有關。
其實這個想法是比較巧妙的,他僅僅針對CHECK POINT 的第一個頁面進行檢測并寫入到 XLOG 中
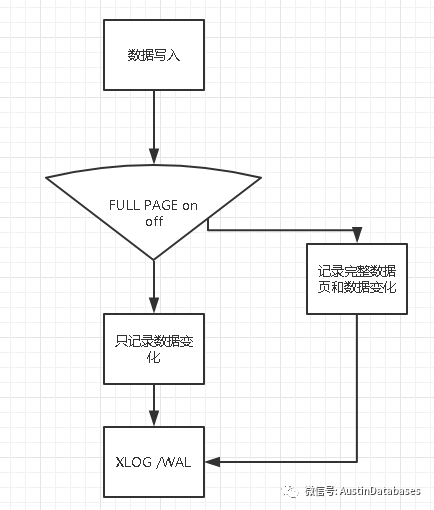
而提出異議或否定的意見是,full_page_write需要在xlog(wal)中記錄數據頁,會進行更多寫操作,不僅數據變,還有數據頁的信息,這會增加的IO和磁盤消耗,引起主備延遲變大。
另外具體相關的FULL PAGE 的解釋和講解,參見下邊的圖,如有需要(可以入群,免費下載相關書籍)

于此同時,很多的優化的方法就來了 ,有一種就很像 MYSQL的 DW 的方式來優化PG 的FULL PAGE 方式, 但需要在PG上打PATCH。(這里不詳細展開)
另外降低CHECKPOINT 的頻率也可以降低 FULL PAGE 所帶來的性能影響,也有提出將PG的數據頁面在編譯的時候變小(個人覺得有點過了), 當然這還不是終極的優化方法,還有的文章中提出了,使用序列,與 UUID 對FULL PAGE 的不同的性能影響,其中指出,如果使用序列的方式,則在插入同樣行數的數據時,對比 UUID ,產生的WAL 的大小相差20倍。

其中關鍵的一段話在上,提出如果使用序列的方式作為主鍵,則插入到btree索引中的相同葉頁面,只有對頁面的第一次修改才會觸發整個頁面的寫入。UUID是完全不同的情況,UUID值完全不是連續的,實際上每次插入都可能接觸到全新的葉索引葉頁面,造成寫入日志的量大影響I/O的性能。
上文中也提出可以調整 CHECK POINT 的間距,來降低FULL PAGE 造成的影響,具體怎么調整CHECK POINT 的間距。

上面是我們在每個PG 中都能看到的與CHECKPOINT 有關的東西,在一個負載很重的系統中,我們是否可以將MAX_WAL_SIZE 調大,(有人可能會問這個數字初期是怎么來的,那我覺得你可能對PG的安裝方面還可以在了解一下),調整到多大,8 - 10G 是沒有問題的。增加檢查點之間的距離可以減少WAL -但是為什么會發生這種情況呢?請記住:將事務日志放在首位的目的是確保系統在崩潰后仍然能夠正常運行。將WAL中的這些更改應用到數據文件將修復數據文件并在啟動時恢復系統。為了安全起見,PostgreSQL不能簡單地記錄對一個塊所做的更改—如果一個塊在通過檢查點后第一次被更改,那么整個頁面都必須被發送到WAL。
兩個檢查點之間的距離不僅由于檢查點的減少而提高了速度,更少的檢查點還會影響所寫事務日志的數量。所以在優化FULL PAGE 的時候是要考慮,降低檢查點,其實這和 MYSQL 里面調整innodb log file size 是一個意思。
在 Postgresql 11 Administratoration Cookbook, 這本書中的427頁也中對這兩個參數也有相關的講解,
兩個參數控制CHECKPOINT發生的頻率與預期,首先checkpoint_timout 這個參數會觸發在上一次CHECKPOINT 發生后多少秒后,進行HECKPOINT,這直接影響有多少量的 WAL data 將要寫入目標文件,實際上控制WAL寫入的數量的參數有兩個地方
MAX_WAL_SIZE
CHECKPOINT_TIMEOUT
然而當你調大參數,你應該考慮系統如果CRASH 后的恢復時間,與多長時間做一次CHECKPOINT 之間做一個衡量,并且也要考慮WAL 日志的空間在磁盤上是否有充足的空間。
同時除2個參數可以優化FULL PAGE 的性能的同時,是否還有其他的方法,我們知道 WAL 日志的也是有緩沖,默認是同步提交,只要是有COMMIT 日志信息就會刷入到磁盤, wal_buffers可以調整wal_buffer 的大小,并且調整 synchronous_commit 不在同步提交,減少磁盤交互,但這會打破系統CRASH 后的數據庫安全,有數據庫丟失的風險。
那怎么有的放矢的更大利用wal_buffers ,可以根據業務,在某些情況下,通過調整下面的參數在session 的級別,來對某些可以容忍 1秒內數據庫丟失的情況中,將syschronous_commit = off.

看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





