溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹R語言中的前向逐步回歸是怎樣的,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
“ 建模過程中,選擇合適的特征集合,可以幫助控制模型復雜度,防止過擬合等問題。為了選取最佳的特征集合,可以遍歷所有的列組合,找出效果最佳的集合,但這樣需要大量的計算。本文介紹的前向逐步回歸法是針對最小二乘法的修改。相對于要將所有組合情況遍歷一遍,前向逐步回歸可以大大節省計算量,選擇最優的特征集合,從而解決過擬合問題。”
前向逐步回歸
前向逐步回歸的過程是:遍歷屬性的一列子集,選擇使模型效果最好的那一列屬性。接著尋找與其組合效果最好的第二列屬性,而不是遍歷所有的兩列子集。以此類推,每次遍歷時,子集都包含上一次遍歷得到的最優子集。這樣,每次遍歷都會選擇一個新的屬性添加到特征集合中,直至特征集合中特征個數不能再增加。
實例代碼
1、數據導入并分組。導入數據,將數據集抽取70%作為訓練集,剩下30%作為測試集。特征與標簽分開存放。
target.url <- "http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv"
data <- read.csv(target.url,header = T,sep=";")
#divide data into training and test sets
index <- which((1:nrow(data))%%3==0)
train <- data[-index,]
test <- data[index,]
#arrange date into list and label sets
trainlist <- train[,1:11]
testlist <- test[,1:11]
trainlabel <- train[,12]
testlabel <- test[,12]
2、前向逐步回歸構建輸出特征集合。通過for循環,從屬性的一個子集開始進行遍歷。第一次遍歷時,該子集為空。每一個屬性被加入子集后,通過線性回歸來擬合模型,并計算在測試集上的誤差,每次遍歷選擇得到誤差最小的一列加入輸出特征集合中。最終得到輸出特征集合的關聯索引和屬性名稱。
#build list of attributes one-at-a-time, starting with empty
attributeList<-as.numeric()
index<-1:ncol(trainlist)
indexSet<-as.numeric()
oosError<-as.numeric()
for(i in index){
#attributes not in list already
attTry<-setdiff(index,attributeList)
#try each attribute not in set to see which one gives least oos error
errorList<-as.numeric()
attTemp<-as.numeric()
for(ii in attTry){
attTemp<-append(attTemp,attributeList)
attTemp<-append(attTemp,ii)
xTrainTemp<-as.data.frame(trainlist[,attTemp])
xTestTemp<-as.data.frame(testlist[,attTemp])
names(xTrainTemp)<-names(trainlist[attTemp])
names(xTestTemp)<-names(testlist[attTemp])
lm.mod <- lm(trainlabel~.,data=xTrainTemp)
rmsError<-rmse(testlabel,predict(lm.mod,(xTestTemp)))
errorList<-append(errorList,rmsError)
attTemp<-as.numeric()
}
iBest<-which.min(errorList)
attributeList<-append(attributeList,attTry[iBest])
oosError<-append(oosError,errorList[iBest])
}
cat("Best attribute indices: ", attributeList, "\n","Best attribute names: \n",names(trainlist[attributeList]))
索引與名稱如下:
屬性名列表的順序也是屬性的 重要性排序,了解屬性重要性,可以增加模型的解釋性。Best attribute indices: 11 2 10 7 6 9 1 8 4 3 5
Best attribute names:
alcohol volatile.acidity sulphates total.sulfur.dioxide free.sulfur.dioxide pH fixed.acidity density residual.sugar citric.acid chlorides
3、模型效果評估。分別畫出RMSE與屬性個數之間的關系,前向逐步預測算法對數據預測對錯誤直方圖,和真實標簽與預測標簽散點圖。
plot(oosError,type = "l",xlab = "Number of Attributes",ylab = "ERMS",main = "error versus number of attributes")
finaltrain<-trainlist[,attributeList[1:which.min(oosError)]]
finaltest<-testlist[,attributeList[1:which.min(oosError)]]
lm.finalmol<-lm(trainlabel~.,data = finaltrain)
finalpre<-predict(lm.finalmol,finaltest)
errorVector<-testlabel-finalpre
hist(errorVector)
plot(predict(lm.finalmol,finaltest),testlabel,xlab = "Predicted Taste Score",ylab = "Actual Taste Score")
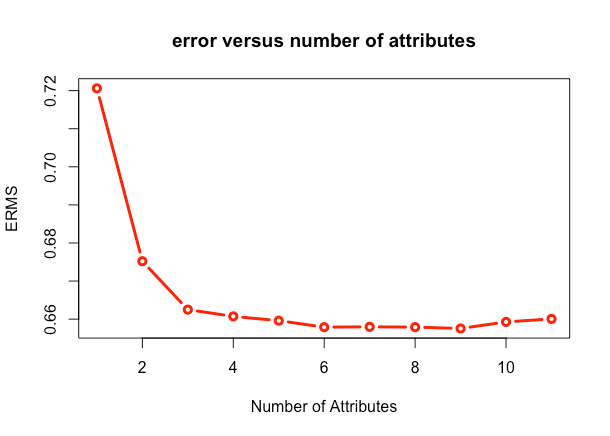
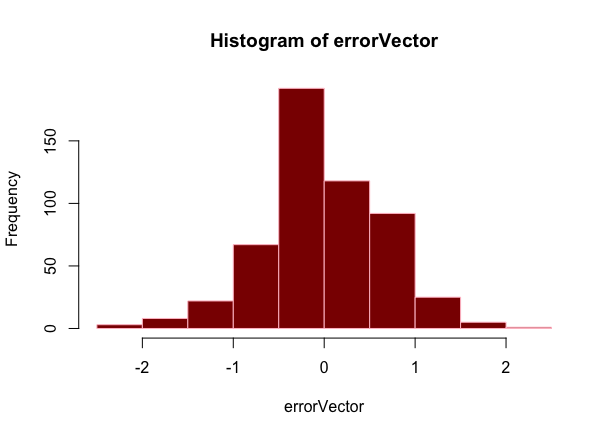
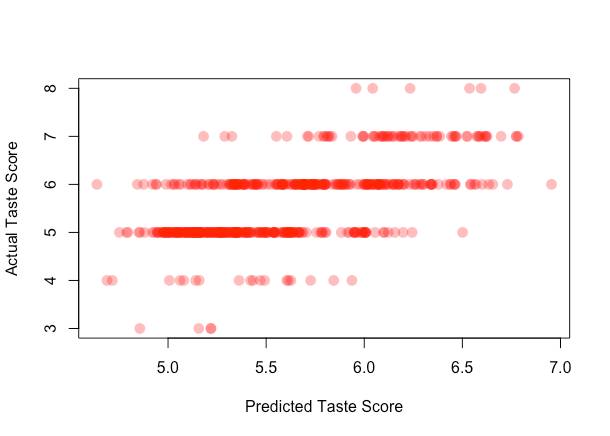
從圖上可以看出,使用前9個屬性,誤差值一直在降低,加入第十個屬性后,誤差值開始增加。因此,我們選取輸出特征集合的前9項,作為最終的最優特征集合。從散點圖上看,得分在5、6時,預測情況非常好,因為區域的顏色深度可以反映點的堆積程度,一般情況下,機器學習算法對邊緣數據預測效果不好。由于真正的標簽是整數,所以散點圖呈水平狀分布。后兩張圖,均可通過分析圖像形態,指出模型性能提升途徑。
關于R語言中的前向逐步回歸是怎樣的就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





