溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關如何理解r語言中的缺失值處理,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
對缺失值的處理是數據預處理中的重要環節,造成數據缺失的原因有:數據丟失、存儲故障和調查中拒絕透露相關信息。這里我們使用VIM包中的sleep數據集為樣本,介紹缺失值處理的方法。sleep數據集紀錄了62個哺乳動物的睡眠信息,包括體重,睡眠時長,做夢時長等。
缺失值分類
1,完全隨機缺失(MCAR):缺失數據與其他變量無關。如果每個缺失變量都為MCAR,則完整樣本可看為更大數據集的簡單抽樣。
2,隨機缺失(CAR):缺失數據與其他觀測變量相關,與本身變量不相關。比如體重小的動物Dream數據更容易缺失(較小動物難以觀察),此時選定體重,則Dream缺失為隨機。
3,非隨機缺失(MNAR):缺失數據不僅依賴于其他變量還依賴于本身變量。比如做夢時間短,Dream容易缺失(可能由于時間短難測量),此時數據缺失為MNAR。
數據缺失一般為前兩種情況,最后一種情況的處理較復雜,要對感興趣的關系進行建模,還要對缺失值的生成機制進行建模,并不斷收集新數據。
判斷缺失值
1,is.na()函數。作用于向量、數據框,對應數值為缺失值則返回TRUE,否則返回FALSE。將sum()函數作用于is.na()的結果,可返回缺失值數量。

2,complete.cases()函數,返回邏輯值向量。與is.na()函數相反,缺失值返回FALSE,正常數據返回TRUE,常用來選擇無缺失的數據。

判斷缺失模式
1,列表顯示缺失情況。這里使用mice包中的md.pattern()函數。

2,圖形顯示缺失情況。
(1)aggr()函數

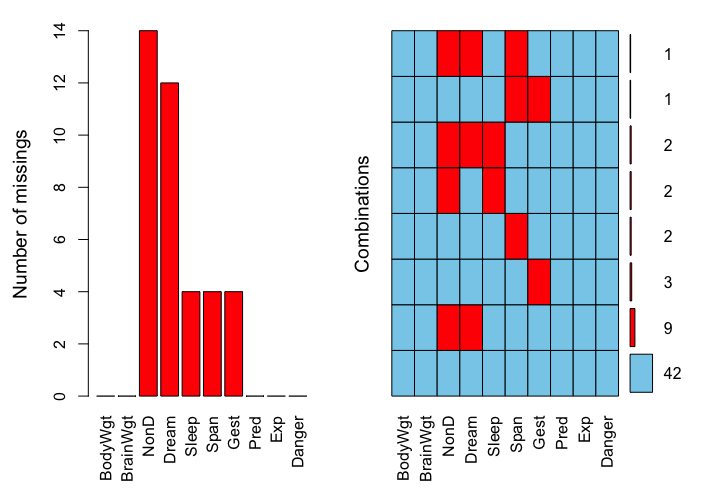
左側圖顯示了每個字段中缺失樣本數量,右側每一行代表了一種缺失模式,紅色代表缺失,藍色代表未缺失,右側表示此模式數量,可與md.pattern()結果對應觀察。
(2)matrixplot()函數

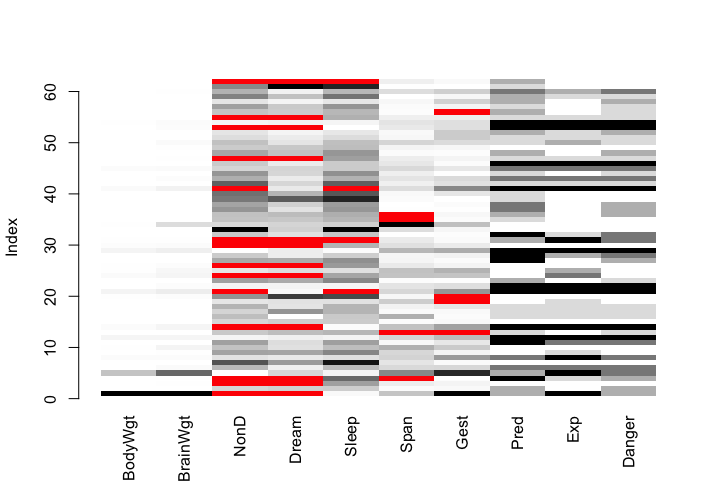
淺色代表值小,深色代表值大,紅色代表缺失。matrixplot()展示了每條樣本的缺失情況。
(3)marginplot()函數,每次只能繪制兩個變量的缺失情況。

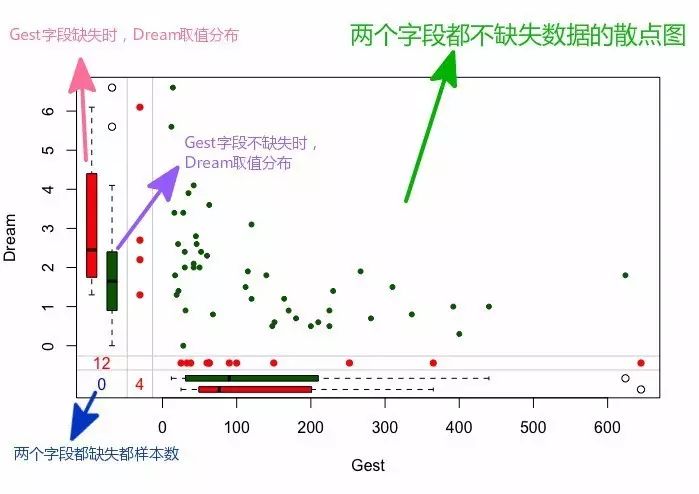
如果為MCAR,紅綠箱線圖應該很類似。
3,相關性探索缺失情況。通過生成影子矩陣,用1表示缺失數據,選取有缺失的樣本,計算缺失相關系數矩陣。有助于觀察哪些變量常一起缺失,以及分析變量“缺失”與其他變量間的關系。

處理缺失值
1,如果缺失樣本數少且為隨機出現,可考慮直接刪除缺失樣本。用na.omit(sleep)或者complete.cases(sleep)。如果某一字段的缺失比例達到5%以上,可與考慮刪除此字段。
2,替換缺失值。可以通過均值、中位數、隨機數來替換缺失值,但是會引入偏差。
3,多重插補法。mice包中的mice()函數可以通過插補返回多個完整數據集并存入imp,用with函數對imp進行線性回歸,最后用pool()函數對回歸結果進行匯總。

mice()函數默認生成5個完整數據集。查看插補數據,可用temp$imp,結果為每個數據集(第一行)每個觀測值(第一列)對插補數據。
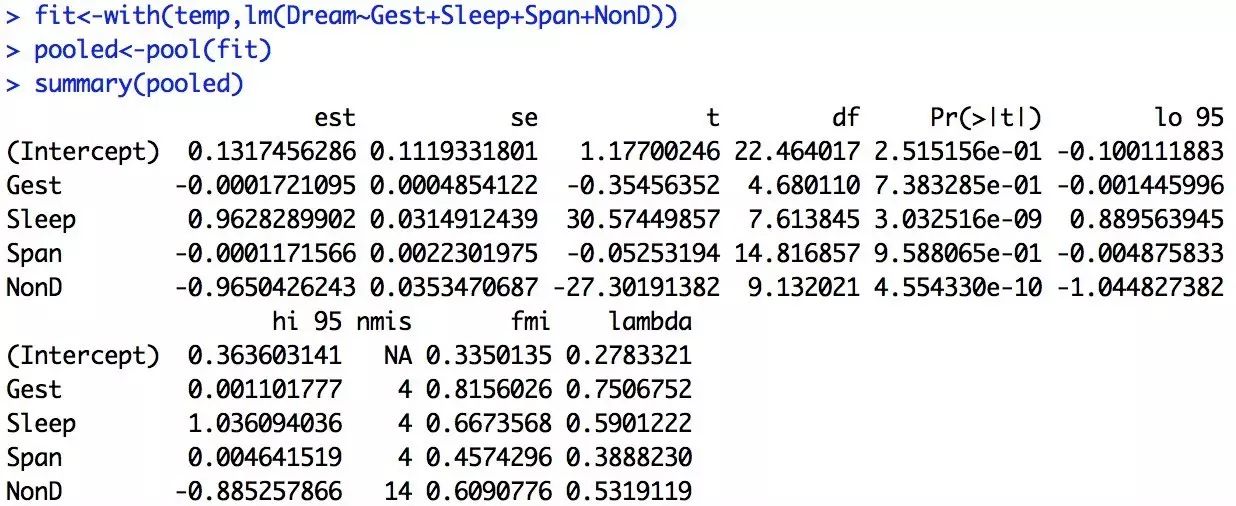
nmis表示變量中缺失數據個數,fmi表示由缺失數據貢獻對變異。with用來檢驗某數據集是否合格,pool用來檢驗整個方法是否合格,以此判斷選擇哪個數據集。
最后用complete()函數生成完整數據集,這里選擇生成對第一個數據集來對缺失值進行替換。

上述就是小編為大家分享的如何理解r語言中的缺失值處理了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





