溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“r語言和pyhthon數據塑型與長寬的轉換方法”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
數據長寬轉換是很常用的需求,特別是當是從Excel中導入的匯總表時,常常需要轉換成一維表(長數據)才能提供給圖表函數或者模型使用。
在R語言中,提供數據長寬轉換的包主要有兩個:
reshape2::melt/dcast
tidyr::gather/spread
library("reshape2")
library("tidyr")
mydata<-data.frame(
Name = c("蘋果","谷歌","臉書","亞馬遜","騰訊"),
Conpany = c("Apple","Google","Facebook","Amozon","Tencent"),
Sale2013 = c(5000,3500,2300,2100,3100),
Sale2014 = c(5050,3800,2900,2500,3300),
Sale2015 = c(5050,3800,2900,2500,3300),
Sale2016 = c(5050,3800,2900,2500,3300)
)
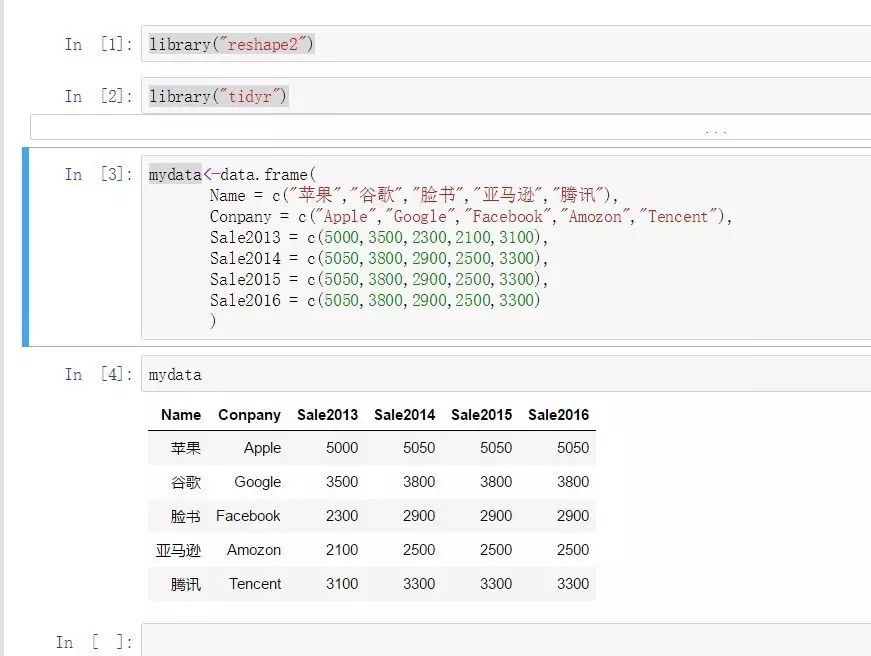
數據重塑(寬轉長):
melt函數是reshape2包中的數據寬轉長的函數
mydata<-melt(
mydata, #待轉換的數據集名稱
id.vars=c("Conpany","Name"), #要保留的主字段
variable.name="Year", #轉換后的分類字段名稱(維度)
value.name="Sale" #轉換后的度量值名稱
)
轉換之后,長數據結構保留了原始寬數據中的Name、Conpany字段,同時將剩余的年度指標進行堆棧,轉換為一個代表年度的類別維度和對應年度的指標。(即轉換后,所有年度字段被降維化了)。
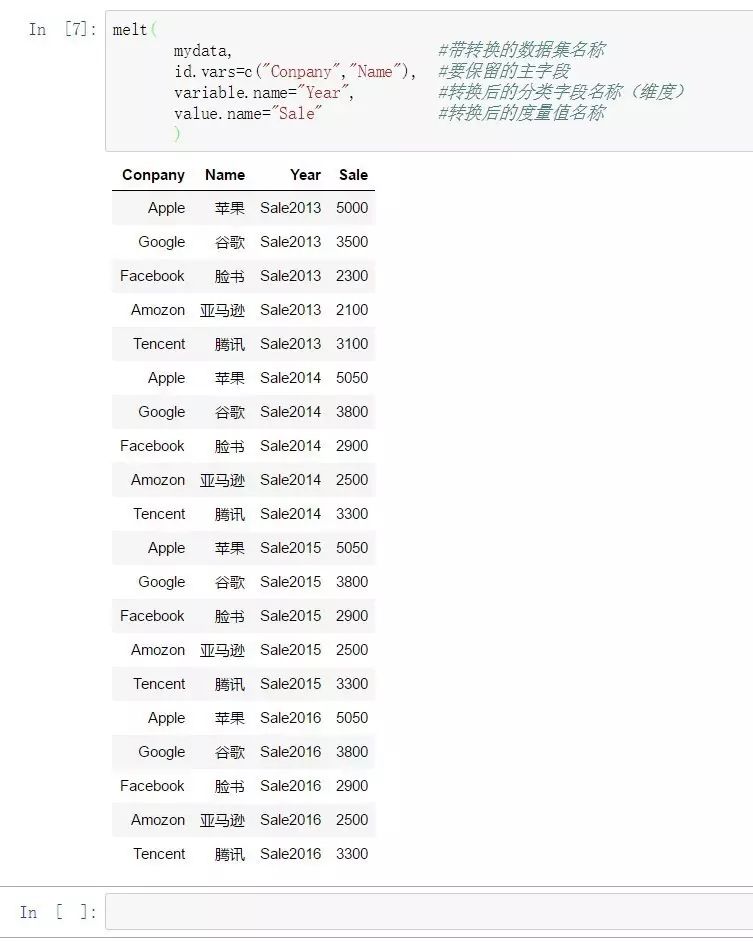
在tidyr包中的gather也可以非常快捷的完成寬轉長的任務:
data1<-gather(
data=mydata, #待轉換的數據集名稱
key="Year", #轉換后的分類字段名稱(維度)
value="Sale" , #轉換后的度量值名稱
Sale2013:Sale2016 #選擇將要被拉長的字段組合
) #(可以使用x:y的格式選擇連續列,也可以以-z的格式排除主字段)
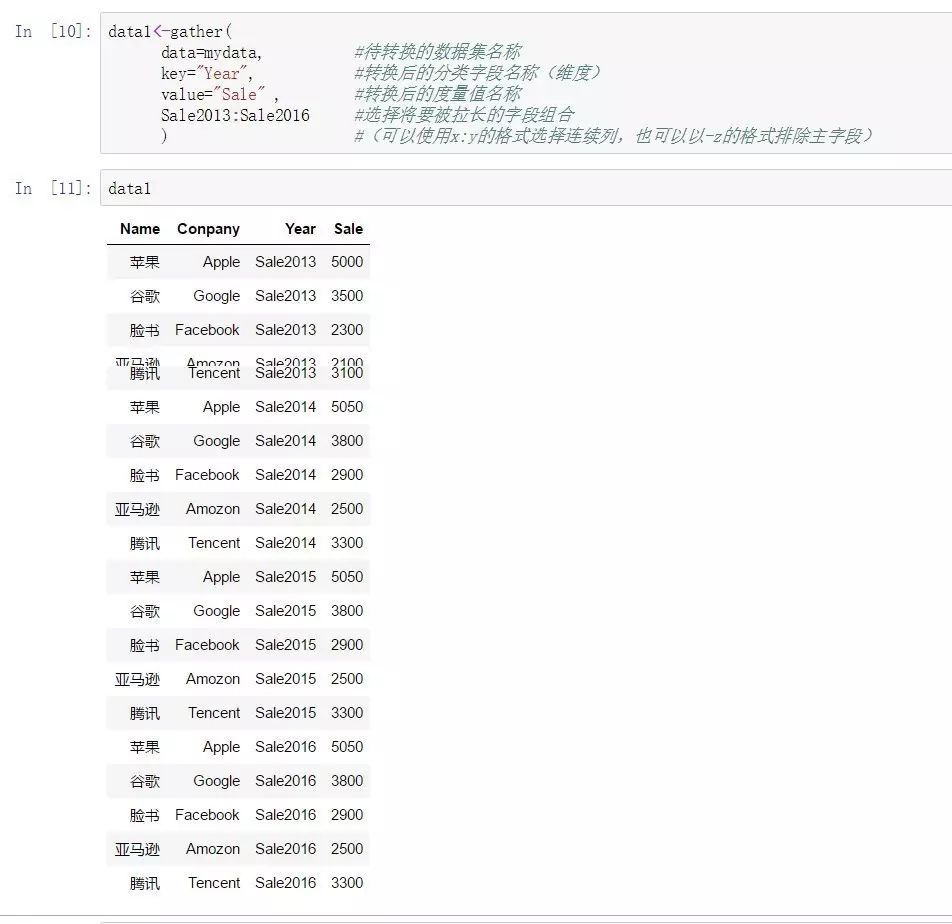
而相對于數據寬轉長而言,數據長轉寬就顯得不是很常用,因為長轉寬是數據透視,這種透視過程可以通過匯總函數或者類數據透視表函數來完成。
但是既然數據長寬轉換是成對的需求,自然有對應的長轉寬函數。
reshape2中的dcast函數可以完成數據長轉寬的需求:
dcast(
data=data1, #數據集名稱
Name+Conpany~Year #x1+x2+……~class
#這一項是一個轉換表達式,表達式左側列
#出要保留的主字段(即不會被擴寬的字段,右側則是要分割的分類變量,擴展之后的
#寬數據會增加若干列度量值,列數等于表達式右側分類變量的類別個數
)
除此之外,tidyr包中的spread函數在解決數據長轉寬方面也是很好的一個選擇。
spread:
spread(
data=data1, #帶轉換長數據框名稱
key=Year, #帶擴寬的類別變量(編程新增列名稱)
value=Sale) #帶擴寬的度量值 (編程新增列度量值)
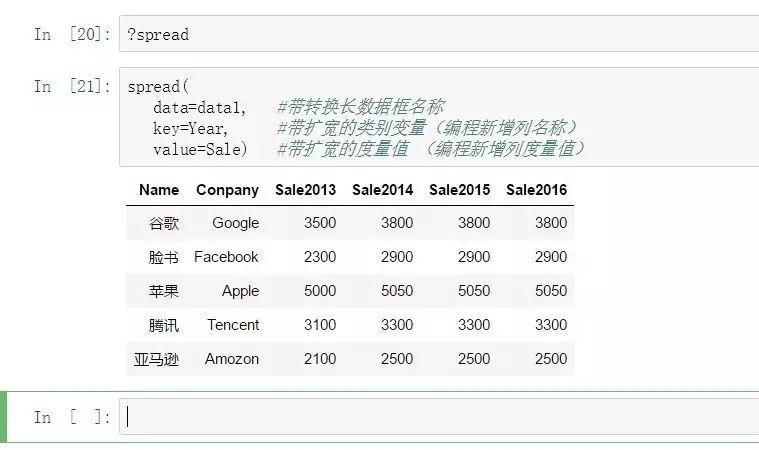
從以上代碼的復雜度來看,reshape2內的兩個函數melt\dcast和tidyr內的兩個函數gather\spread相比,gather\spread這一對函數完勝,不愧是哈神的最新力作,tidyr內的兩個函數所需參數少,邏輯上更好理解,自始至終都圍繞著data,key、value三個參數來進行設定,而相對老舊的包reshape2內的melt\dcast函數在參數配置上就顯得不是很友好,他是圍繞著一直不變的主字段來進行設定的,tidyr包則圍繞著轉換過程中會變形的維度和度量來設定的。
接下來是Python中的數據塑性與長寬轉換。
Python中我只講兩個函數:
melt #數據寬轉長
pivot_table #數據長轉寬
Python中的Pandas包提供了與R語言中reshape2包內幾乎同名的melt函數來對數據進行塑型(寬轉長)操作,甚至連內部參數都保持了一致的風格。
import pandas as pd
import numpy as np
mydata=pd.DataFrame({
"Name":["蘋果","谷歌","臉書","亞馬遜","騰訊"],
"Conpany":["Apple","Google","Facebook","Amozon","Tencent"],
"Sale2013":[5000,3500,2300,2100,3100],
"Sale2014":[5050,3800,2900,2500,3300],
"Sale2015":[5050,3800,2900,2500,3300],
"Sale2016":[5050,3800,2900,2500,3300]
})
mydata1=mydata.melt(
id_vars=["Name","Conpany"], #要保留的主字段
var_name="Year", #拉長的分類變量
value_name="Sale" #拉長的度量值名稱
)
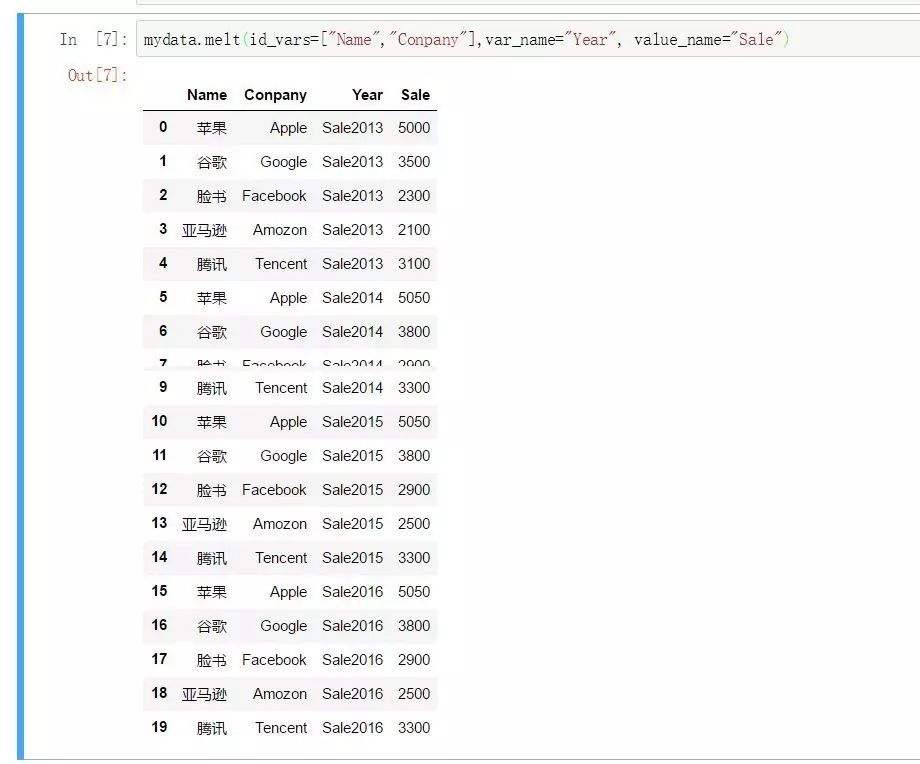
除此之外,我了解到還可以通過stack、wide_to_long函數來進行寬轉長,但是個人覺得melt函數比較直觀一些,也與R語言中的數據寬轉長用法一致,推薦使用。
奇怪的是我好像沒有在pandas中找到對應melt的數據長轉寬函數(R語言中都是成對出現的)。還在Python中提供了非常便捷的數據透視表操作函數,剛開始就已經說過是,長數據轉寬數據就是數據透視的過程(自然寬轉長就可以被稱為逆透視咯,PowerBI也是這么稱呼的)。
pandas中的數據透視表函數提供如同Excel原生透視表一樣的使用體驗,即行標簽、列標簽、度量值等操作,根據使用規則,行列主要操作維度指標,值主要操作度量指標。
那么以上長數據mydata1就可以通過這種方式實現透視。
mydata1.pivot_table(
index=["Name","Conpany"], #行索引(可以使多個類別變量)
columns=["Year"], #列索引(可以使多個類別變量)
values=["Sale"] #值(一般是度量指標)
)
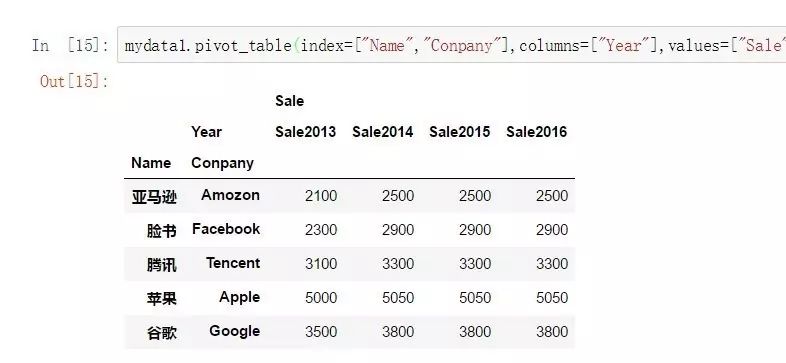
通常這種操作也可以借助堆棧函數來達到同樣的目的。(但是使用stack\unstack需要額外設置多索引,灰常麻煩,所以不是很推薦,有興趣可以查看pandas中的stack/unstack方法,這里不再贅述)。
綜上所述,本文主要提供了R語言與Python中用于處理數據重塑(長寬轉換的常用解決方案)。
R語言:
reshape2::melt
reshape2::dcast
tidyr::gather
tidyr::spread
Python:
pandas-melt
pandas-pivot_table
(備選方案——stack/unstack、wide_to_long)
“r語言和pyhthon數據塑型與長寬的轉換方法”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





