溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了python數據分析如何實現長寬格式的轉換,內容清晰明了,對此有興趣的小伙伴可以學習一下,相信大家閱讀完之后會有幫助。
我就廢話不多說了,大家還是直接看代碼吧!
# encoding=utf-8
import numpy as np
import pandas as pd
# 長寬格式的轉換
# 1
data = pd.read_csv('d:data/macrodata.csv')
print 'data:=\n', data
print 'data.to_records():=\n', data.to_records()
print 'data.year:=\n', data.year
print 'data.quarter:=\n', data.quarter
periods = pd.PeriodIndex(year=data.year, quarter=data.quarter, name='date')
print 'periods:=\n', periods
data = pd.DataFrame(data.to_records(),
columns=pd.Index(['realgdp', 'infl', 'unemp'], name='item'),
index=periods.to_timestamp('D', 'end'))
print 'data:=\n', data
ldata = data.stack().reset_index().rename(columns={0: 'value'})
# print 'ldata:=\n', ldata
print 'ldata.get(\'realgdp\'):=\n', ldata.get('realgdp')
print 'ldata.get(\'unemp\'):=\n', ldata.get('unemp')
wdata = ldata.pivot('date', 'item', 'value')
print 'ldata:=\n', ldata
print 'wdata:=\n', wdata
# 2
print 'ldata[:10]:=\n', ldata[:10]
pivoted = ldata.pivot('date', 'item', 'value')
print 'pivoted:=\n', pivoted
print 'pivoted.head():=\n', pivoted.head()
print 'ldata:=\n', ldata
ldata['value2'] = np.random.randn(len(ldata))
print 'ldata[\'value2\']:=\n', ldata['value2']
print 'ldata[:10]:=\n', ldata[:10]
pivoted = ldata.pivot('date', 'item')
print 'pivoted:=\n', pivoted
print pivoted[:5]
print 'pivoted[\'value\'][:5]:=\n', pivoted['value'][:5]
print 'ldata:=\n', ldata
unstacked = ldata.set_index(['date', 'item']).unstack('item')
print 'unstacked:=\n', unstacked
print 'test'補充知識:python使用_pandas_用stack和unstack進行行列重塑(key-value變寬表)
數據結構的重塑(reshape)
與數據庫交互時常遇到堆疊格式(key-value)和寬表形式(dataframe)的轉換,如:
堆疊格式:
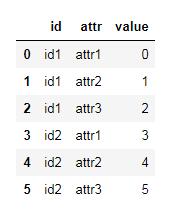
寬表形式dataframe:
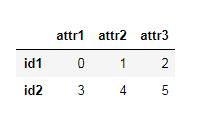
下面是相互轉換的示例代碼:
import pandas as pd
import numpy as np
# 常用的表格形式的數據結構
df = pd.DataFrame(np.arange(6).reshape((2,3)), index=['id1','id2'], columns=['attr1','attr2','attr3'])
print(df)
out:
attr1 attr2 attr3
id1 0 1 2
id2 3 4 5
# 寬表形式(dataframe)轉變為堆疊形式(key-value)形式
# 數據庫中常以該形式存儲
df_key_value = df.stack().reset_index()
df_key_value.columns = ['id', 'attr', 'value']
print(df_key_value)
out:
id attr value
0 id1 attr1 0
1 id1 attr2 1
2 id1 attr3 2
3 id2 attr1 3
4 id2 attr2 4
5 id2 attr3 5
# 堆疊轉換為寬表形式
# 用set_index創建層次化索引,在用unstack重塑
# unstack中作為旋轉軸的變量(如attr),其值會作為列變量展開
df_key_value.set_index(['id','attr']).unstack('attr')
out:
value
attr attr1 attr2 attr3
id
id1 0 1 2
id2 3 4 5
# 多層索引轉化為寬表
df_long = df_key_value.set_index(['id','attr']).unstack('attr')['value'].reset_index()
df_long
out:
attr id attr1 attr2 attr3
0 id1 0 1 2
1 id2 3 4 5
# 堆疊轉換為寬表的快捷鍵---pivot
df_key_value.pivot('id','attr','value')
out:
attr attr1 attr2 attr3
id
id1 0 1 2
id2 3 4 5看完上述內容,是不是對python數據分析如何實現長寬格式的轉換有進一步的了解,如果還想學習更多內容,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





