溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如今,隨著業務“互聯網化”和“智能化”的發展以及架構 “微服務”和“云化”的發展,應用系統對數據的存儲管理提出了新的標準和要求,數據的多樣性成為了數據庫平臺面臨的一大挑戰,數據庫領域也催生了一種新的主流方向。
數據庫多模Multi-Model是指同一個數據庫支持多個存儲引擎,可以同時滿足應用程序對于結構化、半結構化、非結構化數據的統一管理需求。
1.數據庫云化需求催生Multi-Model多模
企業使用云數據庫對接的應用越來越多,需求多種多樣,傳統的做法是在dbPaaS里面提供十幾個不同的數據庫產品分別應對各種需求,這樣的方法在系統增加后,整體維護性和數據一致性管理成本很高,會影響到整個系統的使用。
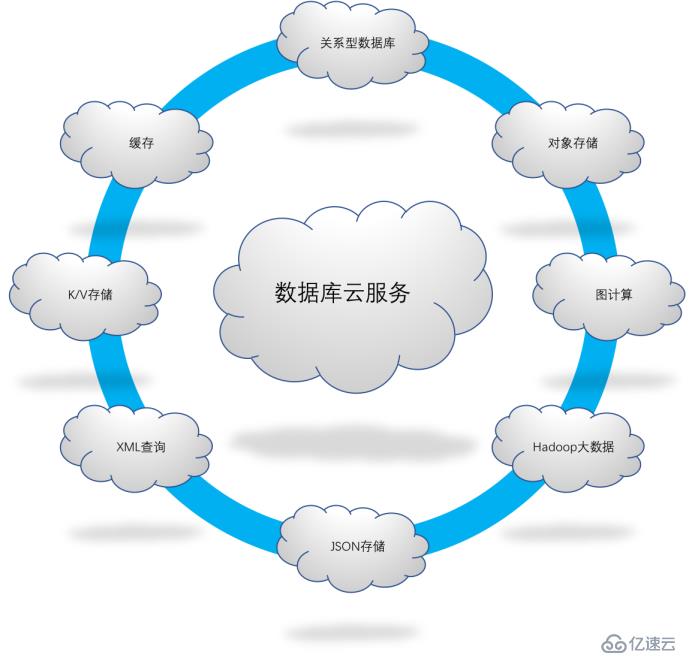
云數據庫的“多模”示意圖
為了實現業務數據的統一管理和數據融合,新型數據庫需要具備多模式(Multi-Model)數據管理和存儲的能力。通常來說,結構化數據特指表單類型的數據存儲結構,典型應用包括銀行核心交易等傳統業務; 而半結構化數據則在用戶畫像、物聯網設備日志采集、應用點擊流分析等場景中得到大規模使用;非結構化數據則對應著海量的的圖片、視頻、和文檔處理等業務,在金融科技的發展下增長迅速。
多模式數據管理能力,使得數據庫能夠進行跨部門、跨業務的數據統一存儲與管理,實現多業務數據融合,支撐多樣化的應用服務。在架構上,多模Multi-model也是針對云數據庫需求的,則使得數據庫使用一套數據管理體系可以支撐多種數據類型,因此支持多種業務模式,大大降低使用和運維的成本。
2.Multi-Model存儲引擎架構
數據庫是現有許多業務系統的核心。隨著數據生成與采集技術的飛速發展,數據量不斷爆炸式增長,數據的結構也越來越靈活多樣。傳統基于關系型理論構建起來的數據庫管理系統,面對大數據、人工智能的真正到來,在成本、性能、擴展性、容錯能力等方面遭遇到了不小的挑戰。
面對多類型的的結構化數據、半結構化數據、非結構化數據,現代應用程序對不同的數據提出了不同的存儲要求,數據庫因此也需要適應這種多類型數據管理的需求。
比較流行的兩種解決思路分別是:混合持久化(Polyglot Persistence)與多模數據庫(Multi-Model Database)。
1)混合持久化 Polyglot Persistence
混合持久化的思路是指,用戶根據工作的不同需求分別選擇使用合適的數據庫,這樣在一個完整的系統中,可能同時運行著多種不同的數據庫。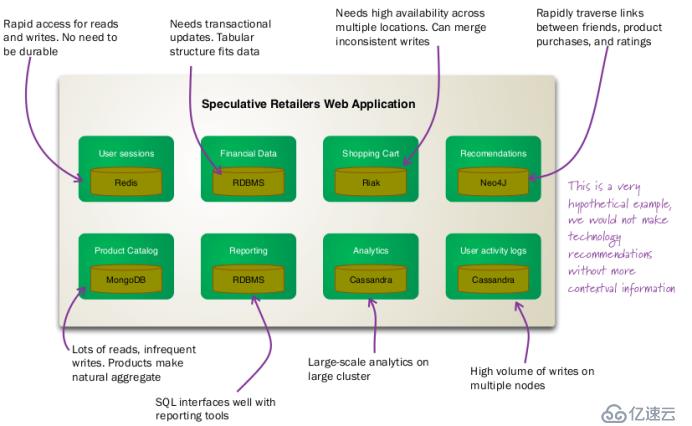
圖1 Polyglot Persistence示意圖
混合持久化一個顯著的優點就是單一流程的性能提升,但缺點也同樣的顯而易見:以增加復雜性和學習成本為代價,在部署、使用及維護上帶來了挑戰。
2)多模Multi-Model
Multi-model多模數據庫則是另一種解決思路,在同一個數據庫內有多個數據引擎,將各種類型的數據進行集中存儲和使用。多個不同類型的應用,同時接入一個數據庫,并在同一個分布式數據庫內進行管理,大大簡化應用程序的開發及后期維護成本。
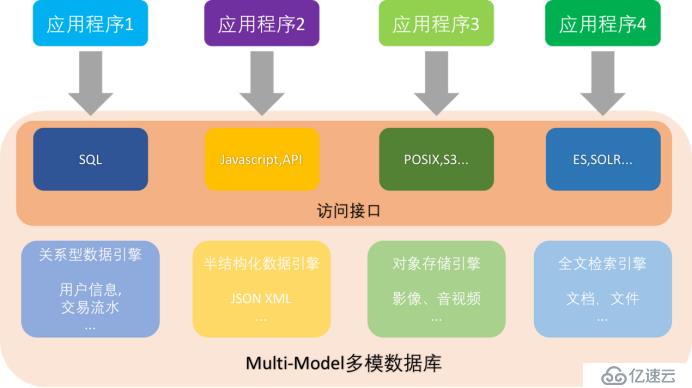
圖2:多模數據庫引擎架構示意圖
圖為多模Multi-Model數據庫的示意圖,我們可以看到在同一個存儲引擎里面同時具備 關系型數據、JSON半結構化數據、對象數據以及全文檢索引擎等等多個數據引擎,統一提供給應。這一架構大大降低開發和運維的難度,應用統一連接到數據庫,數據庫內部進行數據的劃分、隔離和管理,對應用來說只需要連接到數據庫即可,無需為了每個應用搭建對應的數據后臺。
3.存儲數據結構
針對多模數據庫的需求,分布式數據庫的存儲數據結構也會有新的創新。以下就是SequoiaDB在Multi-model方面,進行的數據存儲結構和訪問的設計和實現,可以作為Multimodel數據庫的一個很好的參考。
3.1 結構化、半結構化數據存儲
結構化數據的特點是結構固定,每一行的屬性是相同的,如傳統關系型數據庫表中的數據。半結構化數據是一種自描述結構,它包含相關標記用來分隔語義元素及對記錄和字段進行分層,如 XML,JSON 等。
存儲結構
如何在數據引擎中同時管理結構化和半結構化數據呢?SequoiaDB 使用JSON 數據模型,在數據庫內部使用BSON 格式來將結構化及非結構化數據以文檔的形式存儲在集合中。
BSON(Binary JSON)是對 JSON 的一種二進制編碼數據格式,和 JSON 一樣,BSON支持嵌入式的文檔和數組。BSON 由若干個鍵值對存儲為單個實體,這種實體稱為文檔。BSON 包含了 JSON 中的數據類型,并擴展了一些 JSON 中沒有的數據類型,如Date,BinData 等。BSON 結構的一個簡單示例如下圖所示。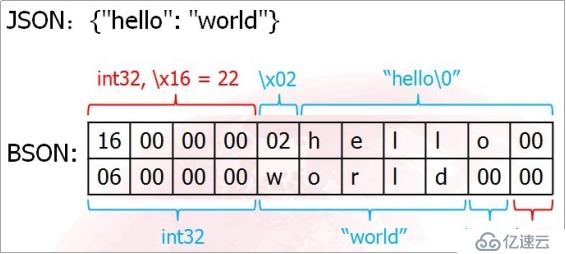
圖3: BSON 結構示例
BSON 具有以下幾個特性:輕量級(Lightweight),可遍歷性(Traversable),高效性(Efficient)。由于BSON結構包含足夠的自描述信息,因此它是一種 schema-less 的存儲形式。
SequoiaDB將 BSON作為記錄的存儲結構,由于其良好的靈活性,不需要事先對集合的結構進行定義,每一個記錄中包含的字段信息可以相同,也可以不同,并可隨時進行修改,這樣對結構及半結構化的數據都能以一致的方式統一存儲和訪問。
SequoiaDB中的數據管理模型如圖4所示。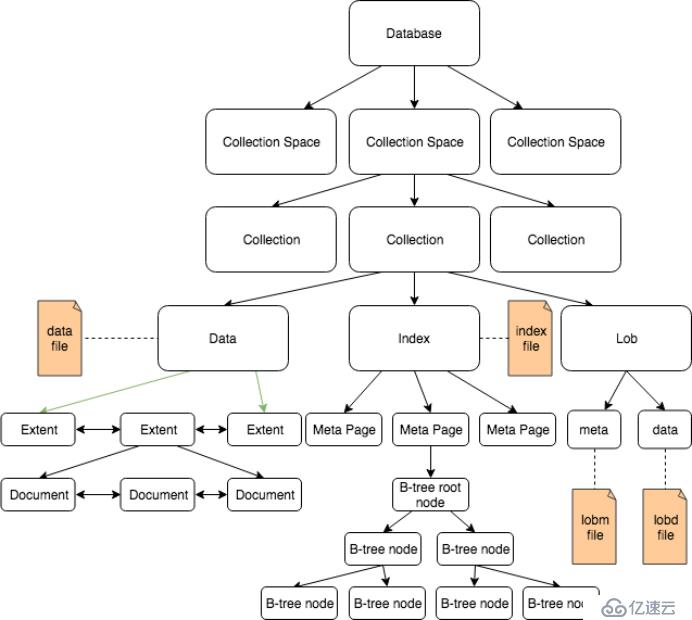
圖4: SequoiaDB 數據管理模型架構圖
數據最終都是要在磁盤文件中進行持久存儲,與之相關的三個概念如下:
?文件(File):磁盤上的物理文件,用于持久存儲集合數據、索引及 LOB 數據。
?頁(Page):頁是數據庫文件中用于組織數據的一種基本結構,SequoiaDB中使用頁來對文件中的空間進行管理與分配。
?數據塊(Extent):由若干個頁組成,用于存放記錄。
在該模型中,與結構/半結構化數據存儲相關的三個核心邏輯概念包括:
?集合空間(Collection Space):用于存儲集合的對象,物理上對應于一組磁盤上的文件。
?集合(Collection):存放文檔的邏輯對象。
?文檔(Document):存儲在集合中的記錄,以 BSON 結構存儲。
一個集合會包含若干個 extent,所有這些 extent使用鏈表串聯起來。當向集合中插入文檔時,需要從 extent 中分配空間。如果當前 extent 沒有足夠空間,則分配新的 extent(必要時對文件進行擴展),掛到該集合的 extent 鏈表上,然后向其中插入文檔。每個 extent 內的記錄也通過鏈表的形式組織起來,這樣在進行表掃描時,可順序讀取塊內的所有記錄。
數據訪問
1)SQL
當前大量基于數據庫的應用使用 SQL 來進行數據庫訪問,因此對的 SQL 支持是數據庫必不可少的能力。SequoiaDB支持標準 SQL 接口,完全兼容 PostgreSQL 及 MySQL語法和協議,現有的應用可平滑地將存儲系統切換為 SequoiaDB,以獲得分布式存儲系統所帶來的擴展性、性能及可靠性等立面的巨大提升。
2)API
SequoiaDB 在結構化數據提供了豐富的 API 接口用于管理整個集群及操作數據,提供了各種主流編譯語言的驅動。
數據壓縮
對于JSON/BSON數據結構,因為其嵌套結構,在擁有靈活的存儲結構同時,也會造成數據的膨脹。JSON數據存儲的膨脹問題,也是早期如MongoDB等JSON數據庫性能瓶頸的一個重要原因。
SequoiaDB在使用JSON/BSON作為數據存儲結構時,為了避免過度的膨脹問題,在數據引擎中加入了數據壓縮的機制。目前SequoiaDB引擎提供了兩類壓縮方式:行壓縮與表壓縮。行壓縮使用Snappy算法,是一種不需要字典的快速壓縮機制。表壓縮則使用LZW算法,是一種基于字典的壓縮機制。
數據壓縮機制,一方面從存儲上節省空間和成本,另一方面提升單位I/O的效率。在IO吞吐量非常高的查詢場景下,基于數據字典的深度壓縮機制能夠大幅降低IO開銷,有效提高查詢效率。
3.2非結構化數據存儲
存儲結構
非結構化數據即沒有固定結構的數據,如文檔、圖片、音頻/視頻等,這種類型的數據在現在的很多業務中所占的比重越來越大。在SequoiaDB中,使用大對象(LOB,Large Object)來對這種類型的數據進行管理。
大對象依附于普通集合存在,當用戶上傳一個大對象時,系統為它分配一個唯一的 OID 值,后續對該大對象的操作可通過該值來進行指定。
大對象在存儲時會進行分片,并使用hash算法將分片分散存儲在相應的分區組中,其哈希空間與所屬集合的哈希空間一致。分片大小為 LOB 頁大小,在創建集合空間時指定,默認為 512KB。
為了對 LOB 數據進行有效的存儲和管理,SequoiaDB內部將 LOB 數據抽象為元數據和數據本身,并使用兩種文件來存儲這些數據: LOBM 文件用于存儲 LOB 分片的元數據,LOBD 文件用于存儲真正的 LOB 數據分片。它們的邏輯結構如下圖所示。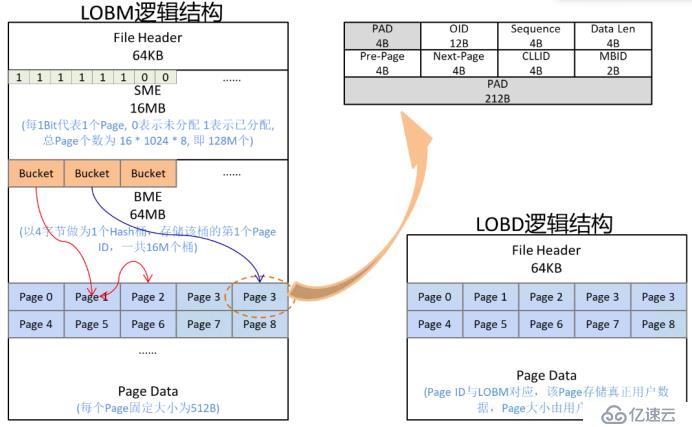
圖5: LOB 文件邏輯結構
其中LOBM 文件主要包括:
?文件頭:包含該文件的一些元數據信息。
?空間管理段(SME):用來標記頁的使用情況。
?桶管理段(BME):hash 值相同的分片所占用的頁以雙向鏈表的形式掛在一個桶上。
?頁:與 LOBD 中的頁一一對應,記錄該頁所屬的集合信息,OID及sequence 值等。
LOBD 文件主要包括:
?文件頭:包含該文件的一些元數據信息。
?真正的數據頁:用于存儲 LOB 分片。LOB 還有一些自身的元數據,保存在 sequence 為0的分片中,包括該 LOB 數據的大小、創建時間、版本號等。
數據訪問
1)寫入LOB
當需要寫入 LOB 數據時,LOB 數據會在協調節點上進行分片,每一個分片分配了一個 sequence 值,它表示這些分片在原始 LOB 數據中的順序。因此,LOB 的OID與分片的 sequence 值唯一地標識了這個分片。
在存儲一個 LOB 分片時,使用其 OID + sequence 計算 hash 值。先使用集合的分區 hash函數來計算出該分片要存儲到哪個分區組上,然后使用 LOB 分片的 hash 函數來計算出其掛接到哪個桶上,之后在 LOBD 及 LOBM 文件中分配數據頁,完成數據寫入,LOBM 中的頁掛到對應的桶上。
2)讀取LOB
在獲取 LOB 數據時,需要指定其 OID值。引擎根據OID值獲取 sequence 值為0的分片,從中讀出 LOB 的元數據信息,然后進行分片計算,確定所有分片信息,向所有包含分片的分區組發送請求。
當協調節點接收到各級返回的分片數據后,按 sequence 的順序對 LOB 數據進行合并還原,以獲取完整的 LOB 數據。
3)標準 Posix文件系統接口
除了LOB的API之外,目前提供SequoiaFS文件系統,它是基于FUSE在Linux系統下實現的一套文件系統,支持通用的文件操作API。SequoiaFS利用SequoiaDB的集合存儲文件和目錄的屬性信息,LOB對象存儲文件的數據內容,從而實現了類似NFS分布式網絡文件系統。用戶可以將遠程SequoiaDB的某個集合通過映射的方式掛載到本地節點,從而在掛載節點的目標目錄下可以通過通用文件系統API對文件和目錄進行操作。
4.小結
根據Gartner的報告,Multi-Model多模是數據庫領域近年興起的一個主要的技術方向之一,其代表了在云化架構下,多類型數據管理的一種新理念,也是簡化運維、節省開發成本的一個新選擇。
SequoiaDB的Multi-Model數據庫產品,目前已經在許多行業的到了應用,這也證明市場正在慢慢接受這一新的數據庫架構。我們也看到MySQL,PostgreSQL等數據庫也在開始支持JSON等多類型格式,也在朝著Multi-model的方向發展。未來相信各產品也會持續保持創新,出現更多Multi-model的數據庫產品。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





