溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
怎么學會DBSCAN聚類算法,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
DBSCAN是一種非常著名的基于密度的聚類算法。其英文全稱是 Density-Based Spatial Clustering of Applications with Noise,意即:一種基于密度,對噪聲魯棒的空間聚類算法。直觀效果上看,DBSCAN算法可以找到樣本點的全部密集區域,并把這些密集區域當做一個一個的聚類簇。
DBSCAN算法具有以下特點:
基于密度,對遠離密度核心的噪聲點魯棒
無需知道聚類簇的數量
可以發現任意形狀的聚類簇
DBSCAN通常適合于對較低維度數據進行聚類分析。
DBSCAN的基本概念可以用1,2,3,4來總結。
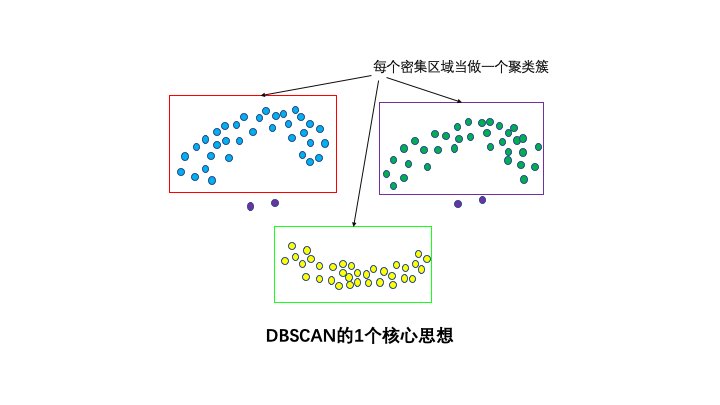
1個核心思想:基于密度。
直觀效果上看,DBSCAN算法可以找到樣本點的全部密集區域,并把這些密集區域當做一個一個的聚類簇。
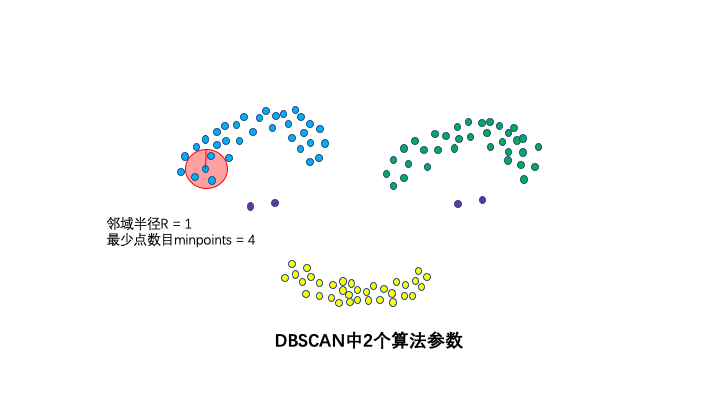
 2個算法參數:鄰域半徑R和最少點數目minpoints。
2個算法參數:鄰域半徑R和最少點數目minpoints。
這兩個算法參數實際可以刻畫什么叫密集——當鄰域半徑R內的點的個數大于最少點數目minpoints時,就是密集。
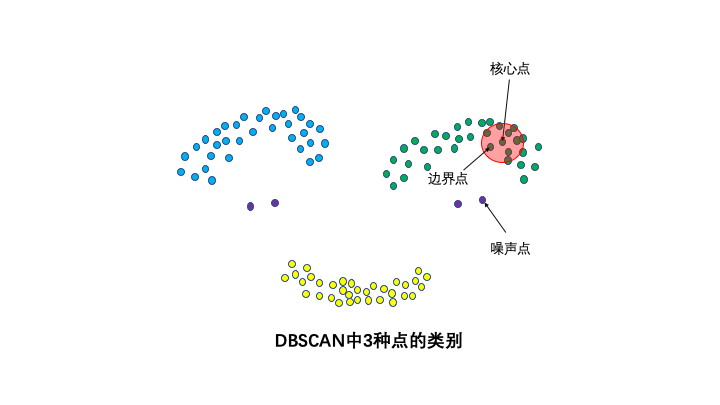
3種點的類別:核心點,邊界點和噪聲點。
鄰域半徑R內樣本點的數量大于等于minpoints的點叫做核心點。不屬于核心點但在某個核心點的鄰域內的點叫做邊界點。既不是核心點也不是邊界點的是噪聲點。
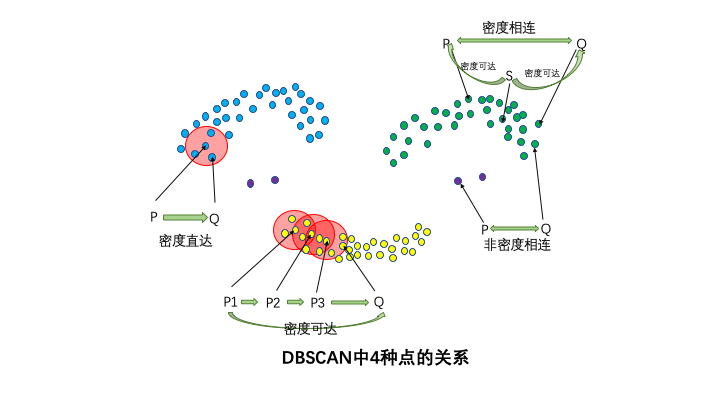
4種點的關系:密度直達,密度可達,密度相連,非密度相連。
如果P為核心點,Q在P的R鄰域內,那么稱P到Q密度直達。任何核心點到其自身密度直達,密度直達不具有對稱性,如果P到Q密度直達,那么Q到P不一定密度直達。
如果存在核心點P2,P3,……,Pn,且P1到P2密度直達,P2到P3密度直達,……,P(n-1)到Pn密度直達,Pn到Q密度直達,則P1到Q密度可達。密度可達也不具有對稱性。
如果存在核心點S,使得S到P和Q都密度可達,則P和Q密度相連。密度相連具有對稱性,如果P和Q密度相連,那么Q和P也一定密度相連。密度相連的兩個點屬于同一個聚類簇。
如果兩個點不屬于密度相連關系,則兩個點非密度相連。非密度相連的兩個點屬于不同的聚類簇,或者其中存在噪聲點。
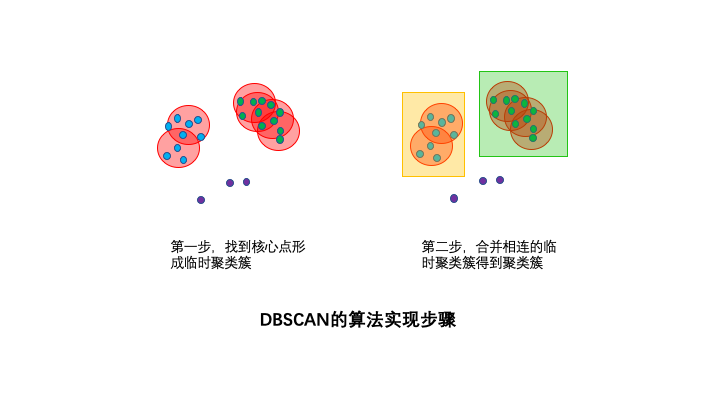
DBSCAN的算法步驟分成兩步。
1,尋找核心點形成臨時聚類簇。
掃描全部樣本點,如果某個樣本點R半徑范圍內點數目>=MinPoints,則將其納入核心點列表,并將其密度直達的點形成對應的臨時聚類簇。
2,合并臨時聚類簇得到聚類簇。
對于每一個臨時聚類簇,檢查其中的點是否為核心點,如果是,將該點對應的臨時聚類簇和當前臨時聚類簇合并,得到新的臨時聚類簇。
重復此操作,直到當前臨時聚類簇中的每一個點要么不在核心點列表,要么其密度直達的點都已經在該臨時聚類簇,該臨時聚類簇升級成為聚類簇。
繼續對剩余的臨時聚類簇進行相同的合并操作,直到全部臨時聚類簇被處理。
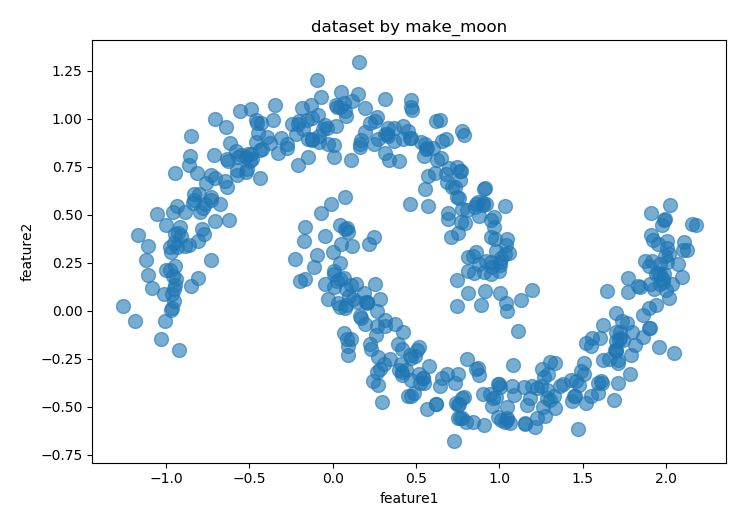
1,生成樣本點
import numpy as npimport pandas as pdfrom sklearn import datasets%matplotlib inlineX,_ = datasets.make_moons(500,noise = 0.1,random_state=1)df = pd.DataFrame(X,columns = ['feature1','feature2'])df.plot.scatter('feature1','feature2', s = 100,alpha = 0.6, title = 'dataset by make_moon')
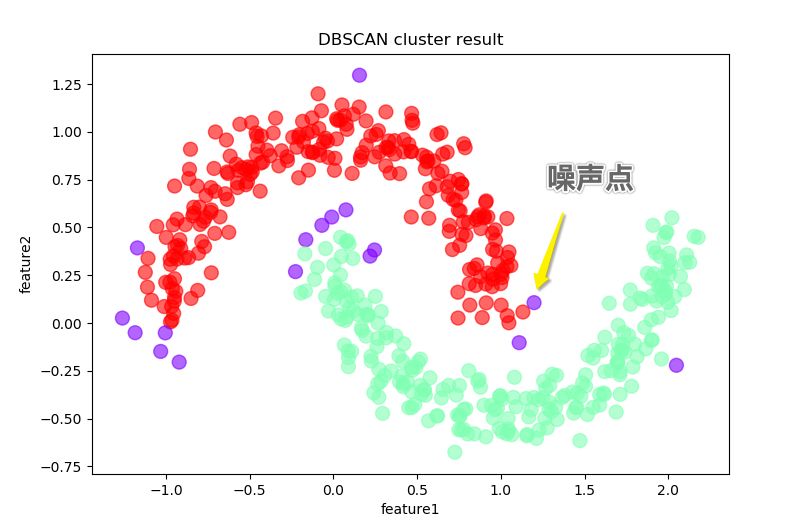
2,調用dbscan接口完成聚類
from sklearn.cluster import dbscan# eps為鄰域半徑,min_samples為最少點數目core_samples,cluster_ids = dbscan(X, eps = 0.2, min_samples=20)# cluster_ids中-1表示對應的點為噪聲點df = pd.DataFrame(np.c_[X,cluster_ids],columns = ['feature1','feature2','cluster_id'])df['cluster_id'] = df['cluster_id'].astype('i2')df.plot.scatter('feature1','feature2', s = 100,c = list(df['cluster_id']),cmap = 'rainbow',colorbar = False,alpha = 0.6,title = 'DBSCAN cluster result')
關于怎么學會DBSCAN聚類算法問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





