溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Python中怎么利用DBSCAN實現一個密度聚類算法,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
基于密度這點有什么好處呢?
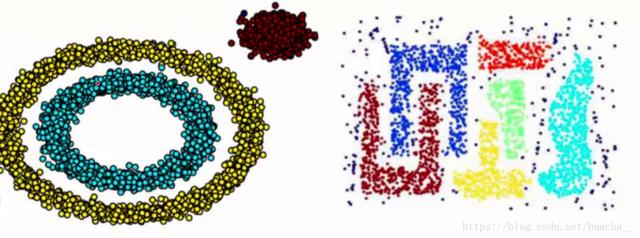
我們知道kmeans聚類算法只能處理球形的簇,也就是一個聚成實心的團(這是因為算法本身計算平均距離的局限)。但往往現實中還會有各種形狀,比如下面兩張圖,環形和不規則形,這個時候,那些傳統的聚類算法顯然就悲劇了。
于是就思考,樣本密度大的成一類唄,這就是DBSCAN聚類算法。
三、參數選擇
上面提到了紅色圓圈滾啊滾的過程,這個過程就包括了DBSCAN算法的兩個參數,這兩個參數比較難指定,公認的指定方法簡單說一下:
半徑:半徑是最難指定的 ,大了,圈住的就多了,簇的個數就少了;反之,簇的個數就多了,這對我們最后的結果是有影響的。我們這個時候K距離可以幫助我們來設定半徑r,也就是要找到突變點,比如: 以上雖然是一個可取的方式,但是有時候比較麻煩 ,大部分還是都試一試進行觀察,用k距離需要做大量實驗來觀察,很難一次性把這些值都選準。
MinPts:這個參數就是圈住的點的個數,也相當于是一個密度,一般這個值都是偏小一些,然后進行多次嘗試
四、DBSCAN算法迭代可視化展示
國外有一個特別有意思的網站,它可以把我們DBSCAN的迭代過程動態圖畫出來。
網址:naftaliharris[1]
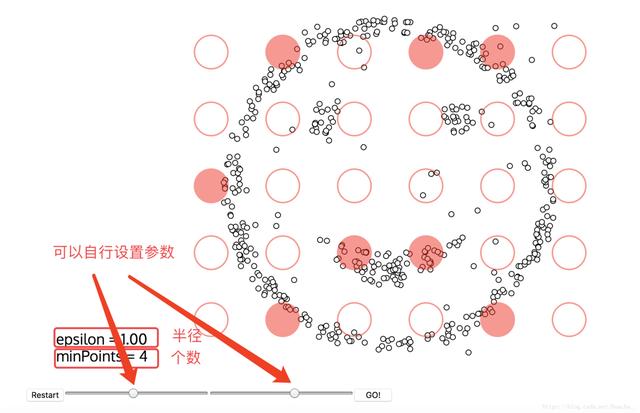
設置好參數,點擊GO! 就開始聚類了!
五、常用評估方法:輪廓系數
這里提一下聚類算法中最常用的評估方法——輪廓系數(Silhouette Coefficient):
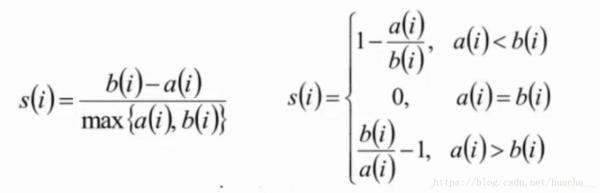
計算樣本i到同簇其它樣本到平均距離ai,ai越小,說明樣本i越應該被聚類到該簇(將ai稱為樣本i到簇內不相似度);
計算樣本i到其它某簇Cj的所有樣本的平均距離bij,稱為樣本i與簇Cj的不相似度。定義為樣本i的簇間不相似度:bi=min(bi1,bi2,...,bik2);
說明:
si接近1,則說明樣本i聚類合理;
si接近-1,則說明樣本i更應該分類到另外的簇;
若si近似為0,則說明樣本i在兩個簇的邊界上;
六、用Python實現DBSCAN聚類算法
導入數據:
import pandas as pd from sklearn.datasets import load_iris # 導入數據,sklearn自帶鳶尾花數據集 iris = load_iris().data print(iris)
輸出:

使用DBSCAN算法:
from sklearn.cluster import DBSCAN iris_db = DBSCAN(eps=0.6,min_samples=4).fit_predict(iris) # 設置半徑為0.6,最小樣本量為2,建模 db = DBSCAN(eps=10, min_samples=2).fit(iris) # 統計每一類的數量 counts = pd.value_counts(iris_db,sort=True) print(counts)

可視化:
import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = [u'Microsoft YaHei'] fig,ax = plt.subplots(1,2,figsize=(12,12)) # 畫聚類后的結果 ax1 = ax[0] ax1.scatter(x=iris[:,0],y=iris[:,1],s=250,c=iris_db) ax1.set_title('DBSCAN聚類結果',fontsize=20) # 畫真實數據結果 ax2 = ax[1] ax2.scatter(x=iris[:,0],y=iris[:,1],s=250,c=load_iris().target) ax2.set_title('真實分類',fontsize=20) plt.show()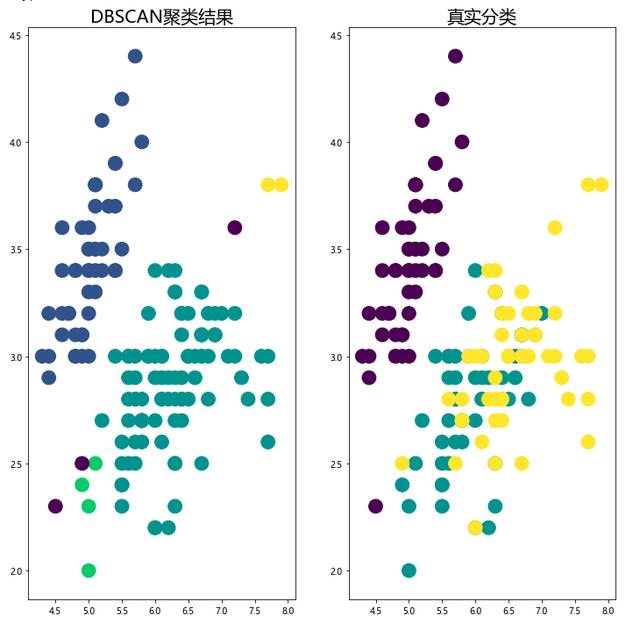
我們可以從上面這個圖里觀察聚類效果的好壞,但是當數據量很大,或者指標很多的時候,觀察起來就會非常麻煩。
這時候可以使用輪廓系數來判定結果好壞,聚類結果的輪廓系數,定義為S,是該聚類是否合理、有效的度量。
聚類結果的輪廓系數的取值在[-1,1]之間,值越大,說明同類樣本相距越近,不同樣本相距越遠,則聚類效果越好。
輪廓系數以及其他的評價函數都定義在sklearn.metrics模塊中,在sklearn中函數silhouette_score()計算所有點的平均輪廓系數。
from sklearn import metrics # 就是下面這個函數可以計算輪廓系數(sklearn真是一個強大的包) score = metrics.silhouette_score(iris,iris_db) score
結果: 0.364
看完上述內容,你們掌握Python中怎么利用DBSCAN實現一個密度聚類算法的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





