溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹Elasticsearch中增加分片數量聚合會不會變快,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
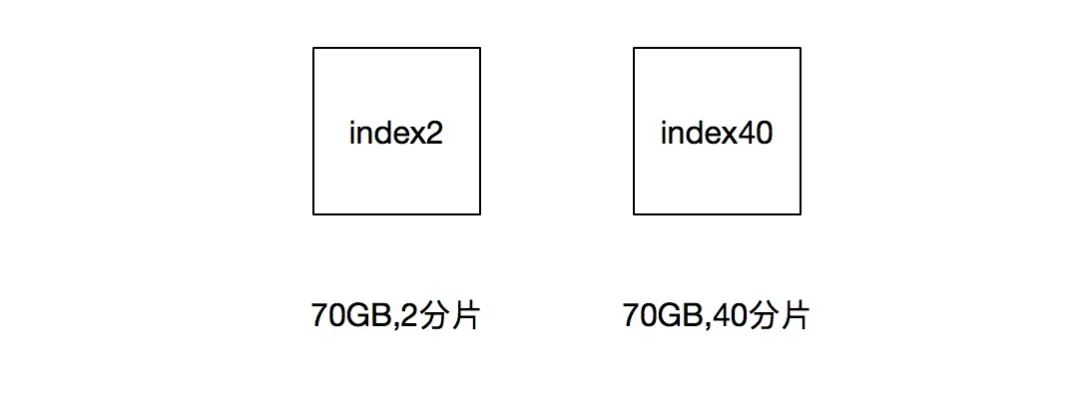
在一次聚合測過程中,我們希望通過增加分片數量的方式,讓聚合計算過程更快完成。因此準備了一個索引,該索引有2.6億 條 doc,大小為70GB,有2個分片。命名為 index2,然后將其 split 為40個分片,生成一個新索引,命名為 index40:
集群有2個節點,JVM 配置30GB,每個索引都經過了 forcemerge。讓集群處于空閑狀態,然后執行聚合測試。這次聚合測試是為了驗證在高基數的數據樣本中,bucket 聚合的速度,并了解一下執行原理,看看可以優化的點。為了模擬產生大量 bucket,測試使用深度嵌套聚合:
{
"aggs": {
"sip": {
"terms": {
"field": "sip",
"size": 10000
},
"aggs": {
"dip": {
"terms": {
"field": "dip",
"size": 10000
},
"aggs": {
"proto": {
"terms": {
"field": "proto",
"size": 10000
}
}
}
}
}
}
}
}
由于 ES 在單個節點的查詢并發限制為5,為了提升并行度,加參數 max_concurrent_shard_requests 進行并發控制,本來預期的是讓所有分片同時執行聚合,會大幅加快聚合速度,結果卻很意外,增加聚合并行度后查詢延遲并沒有很大區別,而 CPU 利用率卻上升了很多!如下表:
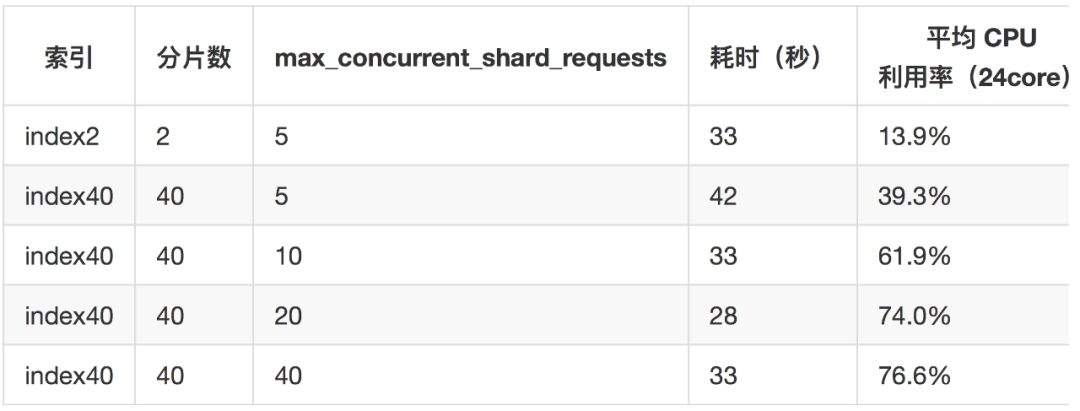
index2的聚合延遲與index40的40并發聚合延遲基本相同,而 CPU 利用率卻大幅增加,多出來的 CPU 干什么去了?打 hot_threads,jstack 等只看到在執行聚合,沒什么特別的,profile 也沒有看到問題。聚合過程中磁盤基本沒有 io。
感覺聚合的速度與分片大小沒有關系,為了驗證這個想法,聚合請求加參數 preference=_shards:0讓他只使用0分片的數據聚合,結果3秒就返回結果,參與聚合的分片越多,聚合返回越慢。因此推翻了這個想法。但同時也觀察到CPU 利用率奇怪變化,如圖,使用4個分片聚合時,起初如左圖,4個 core 占滿,符合預期,接下來很多其他 core 的利用率就會上升,系統在干什么?
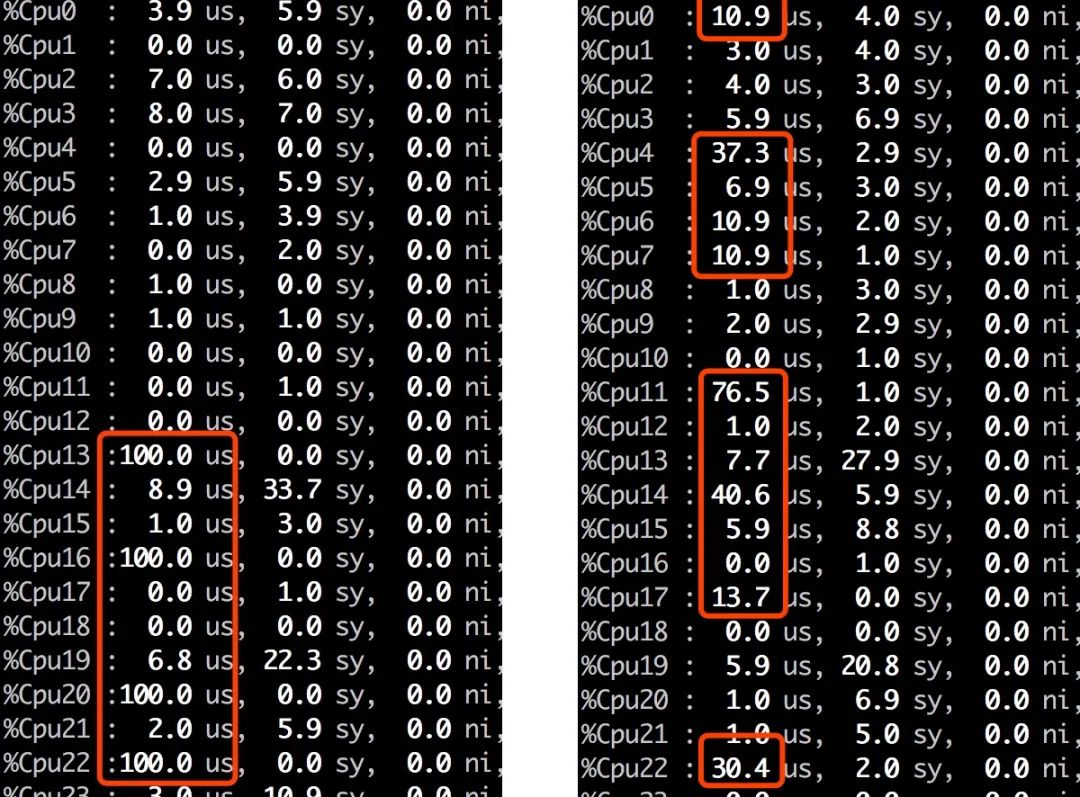
聚合只會在 search 線程池執行,單個分片執行聚合時也不會并發執行,多出來的其他 core 在忙些什么?多次打 jsatck 對比熱點線程,定位到了最可疑的調用鏈:
at org.apache.lucene.store.ByteBufferIndexInput.buildSlice(ByteBufferIndexInput.java:277)
....
org.elasticsearch.search.aggregations.LeafBucketCollector#collect(int, long)
翻一下 buildSlice 的代碼,發現每次都要new 一個ByteBuffer出來:
final ByteBuffer slices[] = new ByteBuffer[endIndex - startIndex + 1];
collect 每收集只收集一條數據,整個聚合過程中僅在此處就要動態申請大量 ByteBuffer,內存一定有問題,jstat 查看對 index40,max_concurrent_shard_requests=40聚合過程中的 gc 情況,果然非常頻繁,部分截圖如下:
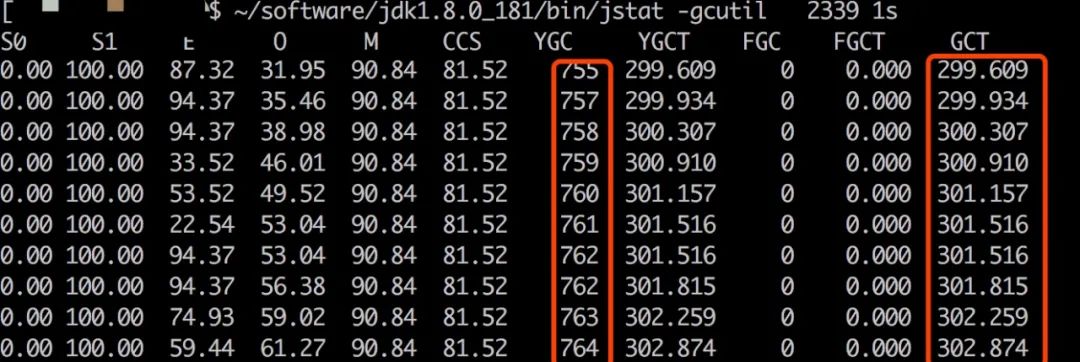
在整個聚合過程中,有大約9秒的時間在執行 GC,而 hot_thread 和 jstack 都無法直接定位到 GC 線程熱點,也因此繞了彎路。結合 GC 日志,確認多余的 core 是在忙于并發 GC。
對比 index2d 的聚合過程,YGC 只執行了2次,GCT 消耗時間低于1秒。
問題至此定位完畢。
由此產生一些思考:
聚合計算一條條collect,效率太低,目前很多計算引擎都使用向量化執行,每次處理一批數據。
聚合過程中動態申請內存過于頻繁,生成了大量臨時對象,給YGC造成較大壓力。
增加分片,提升聚合并行度不一定能加快聚合速度,要考慮業務的聚合語句對內存的壓力有多大,像今天的例子中,40個分片如果散布在更多的節點中,GC 就不是問題,整體聚合速度就應該快很多。類似的,如果聚合產生的 bucket 少一些的時候,增加聚合并行度可以明顯提升整體聚合速度。
聚合要考慮對節點內存的壓力,但是這不太好量化出來。建議上線之前提前做好壓測。高基數的數據上執行 bucket 聚合有比較大的壓力。
關于Elasticsearch中增加分片數量聚合會不會變快就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





