溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章跟大家分析一下“大數據為什么需要數據湖”。內容詳細易懂,對“大數據為什么需要數據湖”感興趣的朋友可以跟著小編的思路慢慢深入來閱讀一下,希望閱讀后能夠對大家有所幫助。下面跟著小編一起深入學習“大數據為什么需要數據湖”的知識吧。
自2011年“數據湖”概念被提出,業界便對數據湖一直有著廣泛而不同的理解和定義。
“數據湖是一個集中化存儲海量的、多個來源,多種類型數據,并可以對數據進行快速加工,分析的平臺,本質上是一套先進的企業數據架構。”——這是對數據湖比較清晰且完整的定義。然而,從定義上看不出數據湖對企業的重要性,下面從數據湖架構的發展,數據平臺對企業的重要性,華為數據湖方案等角度闡明數據湖的對企業的價值。
數據湖架構一直在不斷變革和發展,很多場景下,大家很容易將數據湖與數據倉庫進行混淆,數據湖方案最初確實是為解決數據倉庫笨重,高成本,冗長的分析周期等問題而生,但是二者又有著明顯的不同,同時伴隨著云計算、大數據、人工智能技術的發展,數據湖與之不斷融合,數據湖的架構也在不斷完善。

數據湖與數據倉庫之間的異同點有很多,很容易混淆,但是最重要的區別有兩個:
存儲數據類型:數據倉庫是存儲數據,進行建模,存儲的是結構化數據;數據湖以其本源格式保存大量原始數據,包括結構化的、半結構化的和非結構化的數據。在需要數據之前,沒有定義數據結構和需求。
數據處理模式:在我們可以加載到數據倉庫中的數據,我們首先需要定義好它,這叫做寫時模式(Schema-On-Write)。而對于數據湖,您只需加載原始數據,然后,當您準備使用數據時,就給它一個定義,這叫做讀時模式(Schema-On-Read)。這是兩種截然不同的數據處理方法。因為數據湖是在數據到使用時再定義模型結構,因此提高了數據模型定義的靈活性,可滿足更多不同上層業務的高效率分析訴求。

1、數據湖與大數據技術的融合
Hadoop技術已經經歷了十幾年的發展,而數據湖作為第二數據平面最重要的數據平臺,與Hadoop技術的融合越來越緊密,相輔相成,相得益彰。例如:HBase可以讓數據湖保存海量數據;Spark 使得數據湖可以更快的批量分析海量數據;Storm,Flink,NiFi等使數據湖能夠實時接入和處理IOT數據。Hadoop本身更多的聚焦于數據的處理與應用,但是對于底層的數據存儲工作則并未過多的關注。例如:傳統的Hadoop使用三副本技術保存數據,數據利用率只有33%,數據保存成本較高;同時客戶對于Hadoop承載的數據可靠性要求也越來越高,數據保護(備份、容災等)需求越來越明顯,Hadoop3.x 開啟了存儲和計算分離的趨勢,但這些還不能完全滿足用戶需求,數據湖需要從數據存儲、數據治理等方面繼續發展。
2、數據湖與云計算技術的融合
云計算采用虛擬化、多租戶等技術滿足業務對服務器、網絡、存儲等基礎資源的最大化利用,降低企業對IT基礎設施的成本,為企業帶來了巨大的經濟性;同時云計算技術實現了主機、存儲等資源快速申請、使用,則同樣為企業帶來了更多的管理便捷性。在傳統建設模式下,大數據采用的都是物理機部署模式,在應對多業務類型彈性計算資源需求以及計算性能和存儲容量增幅差異化較大的情況下,計算和存儲一體化的部署模式,既不夠靈活,同時也不能提供最優性價比。這時利用云化技術,將大數據計算部署在云上,把存儲資源與計算資源獨立開來,實現計算和數據各自獨立擴展,彈性伸縮。當前數據湖架構已經在公有云上得到了教完美的實現和應用,例如:Microsoft Azure 在2016年就推出了Data Lake云服務,Amazon AWS 可以基于S3、Glue等多個基本云服務快速構建出一套數據湖服務,Google內部對海量數據集的管理和搜索系統也為數據湖的數據管理指明了道路(詳情參見《Managing Google’s data lake: an overview of the GOODS system》,一篇關于Google內部的海量數據集搜索與管理的論文)。
3、數據湖與人工智能技術的融合
近些年,人工智能技術再一次飛速發展,訓練和推理等需要同時處理超大的,甚至是多個數據集,這些數據集通常是視頻、圖片、文本等非結構化數據,來源于多個行業、組織、項目,對這些數據的采集、存儲、清洗、轉換、特征提取等工作是一個系列復雜、漫長的工程。數據湖需要為人工智能程序提供數據快速收集、治理、分析的平臺,同時提供極高的帶寬、海量小文件存取、多協議互通、數據共享的能力,可以極大加速數據挖掘、深度學習等過程。
很多人都說:“數據湖是新瓶裝舊酒”,只不過是一個概念的拼湊罷了,本質上并沒有什么技術創新。其實“數據湖”這一名詞并不重要,重要的是它能不能在數字化浪潮下,真正幫助企業實現技術轉型,應對快速發展的商業環境下層出不窮的新問題。
數據湖的核心價值是為企業帶來了數據平臺化運營機制。當前很多企業尚未意識到數據平臺化為企業帶來的好處。當今的商業環境,在日新月異的技術變革驅動下,正發生著劇烈的變化,傳統行業不停的被互聯網公司顛覆,給很多公司造成了極大的生存壓力。互聯網公司之所以能不斷顛覆傳統行業,本身除了商業模式的變革,同時也是因為這些公司很多都是采用平臺化戰略,將最新的技術與競爭力整合在平臺中,去賦能公司的運營,使公司的業務發生跳躍式發展,跨界擠壓其他企業的發展空間。傳統企業急需變革,需要像互聯網公司一樣,利用信息化、數字化、新技術的利器形成平臺化系統,賦能公司的人員和業務,快速應對挑戰。
華為數據湖解決方案緊扣時代脈搏,幫助企業利用數據平臺化利器——數據湖,助力業務飛速發展。華為數據湖解決方案基于先進的云上系統架構,著力解決線下企業數字化轉型中,數據無法驅動業務發展、成本高昂、計算存儲等基礎設施資源浪費等復雜問題。
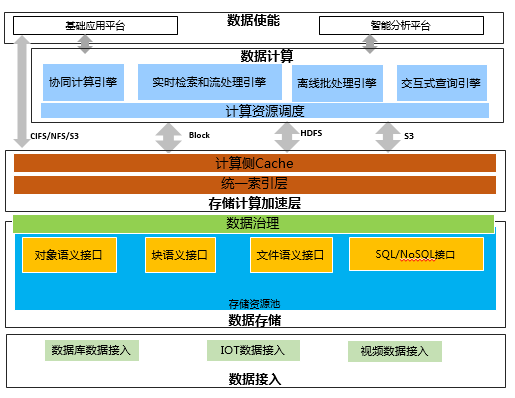
華為數據湖解決方案基本架構
下文從數據集中存儲與共享、數據治理、計算側Cache,快速數據分析這四個維度詳細介紹華為數據湖解決方案。
數據集中存儲與共享
許多企業通常忽略數據積累的價值,數據需要從企業的各個方面持續的收集、存儲,才有可能基于這些數據挖掘出價值信息,指導業務決策,驅動公司發展。華為數據湖解決方案實現數據集中存儲與共享是基于華為大數據解決方案FunsionInsight和華為海量對象存儲架構,實現萬億級數據可靠存儲與高效分析。
使用一套數據存儲資源池,可有效解決企業中的數據煙囪問題,提供統一的命名空間,多協議互通訪問,實現數據資源的高效共享,減少數據移動。例如:很多的汽車制造企業都在進行無人駕駛/自動駕駛研究,車輛上的傳感器、雷達等IOT設備產生的文件,通過離線批量導入或者高速訪問網絡進入到存儲集群后通過Hadoop (HDFS)進行分析處理,再進入HPC集群(NFS)進行仿真計算,也可以讀取到GPU集群進行訓練(S3)。整個過程中,數據無需拷貝和移動,實現高效數據共享。
數據集中存儲與共享實際上是將存儲資源池化,將計算和數據進行分離。當前仍然有不少人不能接受大數據的計算和數據分離架構,認為一旦采用分離架構,必然會導致性能的降低。但實際上,分離后可極大降低存儲成本,有效提高計算資源利用率,增強計算和存儲集群的靈活性。但不是所有情況下都要分離,根據我們在政府、運營商、金融、企業等多個行業多個項目的經驗,如下情況適合分離:
1.隨著數據量的增長,存儲和計算資源的使用率嚴重不均衡,比如:用戶行為分析中的用戶留存分析,存儲數據量不斷增長,但計算資源基本不變;
2.業務部門向平臺部門單獨申請計算或存儲資源,分離架構可以更靈活的分配資源。
另外從數據生命周期的維度也可以找到適合的階段,綠色部分表示的數據的清洗、加工整合和歸檔備份場景適合存儲和計算的分離。
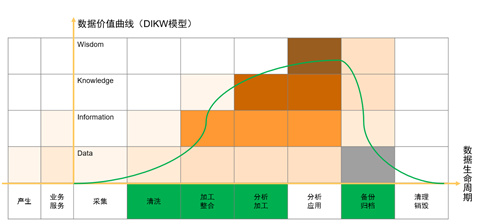
注意:存儲和計算分離往往伴隨大數據的服務化,需要從云化、資源彈性調度的角度管理資源。
數據治理
數據不僅要存下來,更要治理好,否則數據湖將變成數據沼澤,浪費大量的IT資源。平臺化的數據湖架構能否驅動企業業務發展,數據治理至關重要。企業中收集的數據或從其他行業中采集數據種類多樣,格式不一,多數以原始格式存儲,企業需要不斷對這些原始數據進行整合加工,根據各業務組織、場景、需求形成容易分析的干凈數據,盡可能多的讓更多的人訪問分析數據。數據治理是個一系列復雜的工作,這里重點介紹下元數據的管理。
華為數據湖解決方案為企業中海量的數據集提供了一套集中的元數據管理系統,提供全局的數據資源目錄、完整的數據元數據描述、數據血緣關系,方便員工快速查找了解數據,更好的支撐數據分析,元數據管理異步的從數據服務中抽取元數據,盡量不影響原系統的運行。
計算側Cache
計算和數據分離后必然會帶來一定的網絡I/O開銷,計算側Cache可有效減少頻繁的網絡I/O次數。同時萬兆網絡已經得以普及,甚至更高,網絡對計算影響已經非常有限。計算側Cache采用多種算法,將數據緩存在計算側,可以使得很多場景下計算與數據分離方案的性能甚至高于一體化方式。
數據快速分析
前述的大量工作實際上都是為了加速數據分析的過程。數據快速分析需要提供多種數據分析引擎,基于華為FusionInsight 大數據方案提供Spark、HBase、ES、LibrA(一種融合數據的基于SQL的分布式數據關系型數據庫)等多種分析方式,快速分析不僅是能在已經被整合后變干凈的保存在LibrA中的數據,還能直接訪問海量對象存儲中的數據,無需數據抽取,減少數據的轉換,支持高并發讀取,提升實時分析效率。同時可支持自助式的數據探索式分析。
華為數據湖解決方案提供了完整的數據架構支持,為企業構建一站式數據處理體驗,目前已在多個行業和客戶中使用。例如:華為數據湖解決方案支撐平安城市“一云一湖一平臺”系統架構,為公安客戶構建了物理分散(分散在各地市、區縣的數據)、邏輯統一的數據治理架構。
關于大數據為什么需要數據湖就分享到這里啦,希望上述內容能夠讓大家有所提升。如果想要學習更多知識,請大家多多留意小編的更新。謝謝大家關注一下億速云網站!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





