溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“怎么用GPU編寫Hello World”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“怎么用GPU編寫Hello World”文章能幫助大家解決問題。
??在GPU編程中,有三種函數的聲明:
| Executed on | Only callable from | |
|---|---|---|
| __global__ void KernelFunc() | device | host |
| __device__ float DeviceFunc() | device | device |
| __host__ float HostFunt() | host | host |
這里的host端就是指CPU,device端就是指GPU;使用__global__聲明的核函數是在CPU端調用,在GPU里執行;__device__聲明的函數調用和執行都在GPU中;__host__聲明的函數調用和執行都在CPU端。
??在講GPU并行計算之前,我們先講一下使用GPU后能提高性能的理論值,即Amdahld定理,也就是相對串行程序而言,并行程序的加速率。
??假設程序中可并行代碼的比例為p,并行處理器數目是n,程序并行化后的加速率為: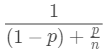
??Hello World程序是我們學習任何編程語言時,第一個要完成的,雖然cuda c并不是一門新的語言,但我們還是從Hello World開始Cuda編程。
#include <stdio.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
__global__ void hello_world(void)
{
printf("GPU: Hello world! Thread id : %d\n", threadIdx.x);
}
int main(){
printf("CPU: Hello world!\n");
hello_world <<<1, 10>>>();
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaDeviceReset();
return 0;
}??程序中的具體語法我們后面會講到,這里只要記住<<<1, 10>>>是調用了10個線程即可,執行上面的程序,會打印出10個GPU的Hello World,這個就是SIMD,即單指令多線程,多個線程執行相同的指令,就像程序中的這個10個線程同時執行打印Hello Wolrd的這個指令一樣。
關于“怎么用GPU編寫Hello World”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





