溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了GPU內存實例分析的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇GPU內存實例分析文章都會有所收獲,下面我們一起來看看吧。
??首先來回顧一下GPU中的內存:
每個線程都有自己的私有本地內存(Local Memory)和Resigter
每個線程都包含共享內存(Shared Memory),可以被線程中所有的線程共享,其生命周期與線程快一致
所有的線程都可以訪問全局內存(Global Memory)
只讀內存塊:常量內存(Constant Memory)和紋理內存(Texture Memory)
每個SM有自己的L1 cache,SM通過L2 cache連接到Global Memory
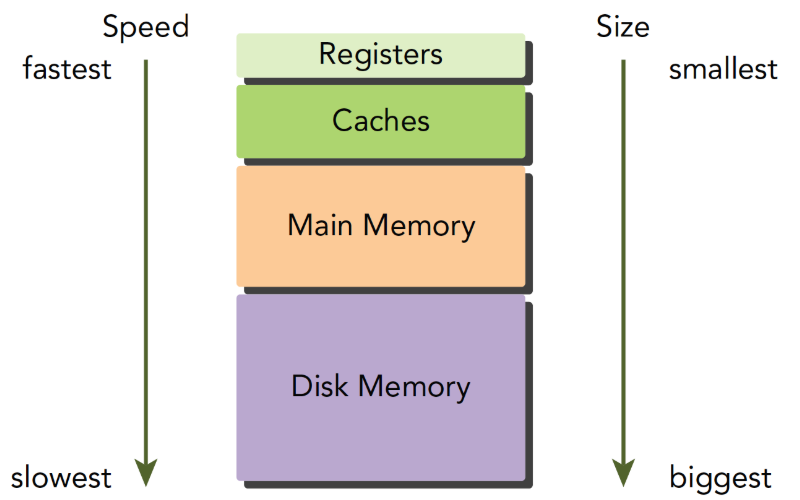
內存訪問速度
??這一點跟CPU比較像,就是存儲空間越大,訪問速度越慢,GPU內存的訪問速度從快到慢依次為:Registers->Caches->Shared Memory->Gloabl Memory。
??寄存器是訪問速度最快的空間,寄存器變量在程序中宏如何使用?
??當我們在核函數中不加修飾的聲明一個變量,那該變量就是寄存器變量,如果在核函數中定義了常數長度的數組,那也會被分配到Registers中;寄存器變量是每個線程私有的,當這個線程的核函數執行完成后,寄存器變量也就不能訪問了。
??寄存器是比較稀缺的資源,空間很小,Fermi架構中每個線程最多63個寄存器,Kepler架構每個線程最多255個寄存器;一個線程中如果使用了比較少的寄存器,那么SM中就會有更多的線程塊,GPU并行計算速度也就越快。
??如果一個線程中變量太多,超出了Registers的空間,這時寄存器就會發生溢出,就需要其他內存(Local Memory)來存儲,當然程序的運行速度也會降低。
??因此,在程序中,對于那種循環操作的變量,我們可以放到寄存器中;同時要盡量減少寄存器的使用數量,這樣線程塊的數量才能增多,整個程序的運行速度才能更快。
??Local Memory也是每個線程私有的,在核函數中符合存儲在寄存器中但不能進入核函數分配的寄存器空間中的變量將被存儲在Local Memory中,Local Memory中可能存放的變量有以下幾種:
使用未知索引的本地數組
較大的本地數組或結構體
任何不滿足核函數寄存器限定條件的變量
??每個SM中都有共享內存,使用__shared__關鍵字(CUDA關鍵字的下劃線一般都是兩個)定義,共享內存在核函數中聲明,生命周期和線程塊一致。
??同樣需要注意的是,SM中共享內存使用太多,會導致SM上活躍的線程數量減少,也會影響程序的運行效率。
??數據的共享肯定會導致線程間的競爭,可以通過同步語句來避免內存競爭,同步語句為:
void __syncthreads();
當所有線程都執行到這一步時,才能繼續向下執行;頻繁調用__syncthreads()也會影響核函數的執行效率。
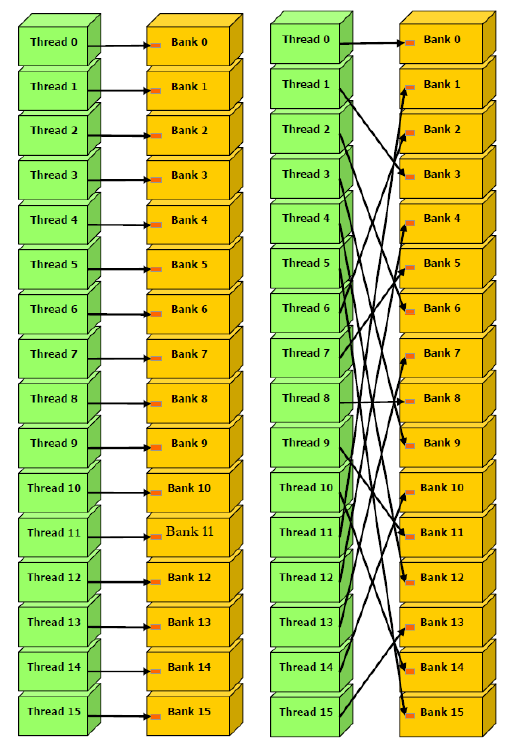
??共享內存被分成了不同個Bank,我們知道一個Warp中有32個SM,在比較老的GPU中,16個Bank可以同時訪問,即一條指令就可以讓半個Warp同時訪問16個Bank,這種并行訪問的效率可以極大的提高GPU的效率。比較新的GPU中,一個Warp即32個SM可以同時訪問32個Bank,效率又提升了一倍。
??下面這個圖中,左邊的圖每個線程訪問一個Bank,不存在內存沖突,通過一個指令即可完成訪問所有的訪問操作;右邊的圖雖然看起來有些亂,但還是一個線程對應一個Bank,也不存在沖突,一個指令即可完成。
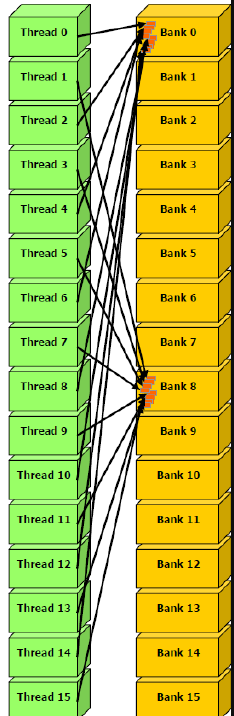
??下面這個圖中,存在多個Thread訪問一個Bank的情況,如果是讀操作,那么GPU底層可以通過廣播的方式將數據傳給各個Thread,延遲不會很大,但如果是寫操作,就必須要等上一個線程寫完成后才能進行下一個線程的寫操作,延時會比較大。
??常量內存駐留在設備內存中,每個SM都有專用的常量內存空間,使用__constant__關鍵字來聲明。
??常量內存存在于核函數之外,在全局范圍內聲明,常量內容的訪問速度也是很快的,對所有的核函數都可見,在Host端進行初始化后,核函數不能再修改。
??紋理內存的使用并不多,它是為了GPU的顯示而設計的,這里不多講了。
??全局內存,就是我們常說的顯存,就是GDDR的空間,全局內存中的變量,只要不銷毀,生命周期和應用程序是一樣的。
??在訪問全局內存時,要求是對齊的,也就是一次要讀取指定大小(32、64、128)整數倍字節的內存,數據對齊就意味著傳輸效率降低,比如我們想讀33個字節,但實際操作中,需要讀取64字節的空間。
??每個SM都有一個一級緩存,所有SM公用一個二級緩存,GPU讀操作是可以使用緩存的,但寫操作不能被緩存。
??每個SM有一個只讀常量緩存,只讀紋理緩存,它們用于設備內存中提高來自于各個內存空間內的讀取性能。
關于“GPU內存實例分析”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“GPU內存實例分析”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





