溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Apache Spark 是專為大規模數據處理而設計的快速通用的計算引擎。Spark是UC Berkeley AMP lab (加州大學伯克利分校的AMP實驗室)所開源的類Hadoop MapReduce的通用并行框架,Spark,擁有Hadoop MapReduce所具有的優點;但不同于MapReduce的是Job中間輸出結果可以保存在內存中,從而不再需要讀寫HDFS,因此Spark能更好地適用于數據挖掘與機器學習等需要迭代的MapReduce的算法。
Spark 是一種與 Hadoop 相似的開源集群計算環境,但是兩者之間還存在一些不同之處,這些有用的不同之處使 Spark 在某些工作負載方面表現得更加優越,換句話說,Spark 啟用了內存分布數據集,除了能夠提供交互式查詢外,它還可以優化迭代工作負載。
Spark 是在 Scala 語言中實現的,它將 Scala 用作其應用程序框架。與 Hadoop 不同,Spark 和 Scala 能夠緊密集成,其中的 Scala 可以像操作本地集合對象一樣輕松地操作分布式數據集。
盡管創建 Spark 是為了支持分布式數據集上的迭代作業,但是實際上它是對 Hadoop 的補充,可以在 Hadoop 文件系統中并行運行。通過名為 Mesos 的第三方集群框架可以支持此行為。Spark 由加州大學伯克利分校 AMP 實驗室 (Algorithms, Machines, and People Lab) 開發,可用來構建大型的、低延遲的數據分析應用程序。
192.168.174.141 hd1 master
192.168.174.142 hd2 slave1
192.168.174.143 hd3 slave2useradd hadoop
passwd hadoop
New password:
Retype new password:
授權 root 權限,在root下面加一條hadoop的hadoop ALL=(ALL) ALL
#修改權限
chmod 777 /etc/sudoers
vim /etc/sudoers
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
#恢復權限
chmod 440 /etc/sudoers
#進入到我的home目錄,
su - hadoop
ssh-keygen -t rsa (連續按四個回車)
#執行完這個命令后,會生成兩個文件id_rsa(私鑰)、id_rsa.pub(公鑰)
#將公鑰拷貝到要免密登錄的機器上
ssh-copy-id hd2
ssh-copy-id hd3
#在h2,h3,h4機器上新建apps目錄用于存放hadoop和spark安裝包
mkdir -p /home/hadoop/apps/hadoop
cd /home/hadoop/apps/hadoop
#在hd1機器上 下載hadoop2.7.7(hd2,hd3上等在hd1把hadoop的相關配置改完后scp發送過去)
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
tar -zxvf hadoop-2.7.7.tar.gz
#配置環境變量
sudo vim /etc/profile
#添加HADOOP_HOME
export HADOOP_HOME=/home/hadoop/apps/hadoop/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#刷新環境變量
source /etc/profile
#查看hadoop版本
hadoop version
#配置Hadoop的JAVA_HOME
cd /home/hadoop/apps/hadoop/hadoop-2.7.7/etc/hadoop
vim hadoop-env.sh
#大概在25行,添加
export JAVA_HOME=/opt/soft/java/jdk1.8.0_73
#修改配置文件
1、修改core-site.xml
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hd1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/apps/hadoop/hadoop-2.7.7/tmp</value>
</property>
</configuration>
2、修改hdfs-site.xml
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hd1:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/apps/hadoop/hadoop-2.7.7/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/apps/hadoop/hadoop-2.7.7/tmp/dfs/data</value>
</property>
</configuration>
3、修改mapred-site.xml
#目錄下沒有這個文件,復制一份出來
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hd1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hd1:19888</value>
</property>
</configuration>
4、修改yarn-site.xml
vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hd1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hd1:19888/jobhistory/logs</value>
</property>
<property>
??? <name>yarn.nodemanager.pmem-check-enabled</name>
??? <value>false</value>
</property>
<property>
??? <name>yarn.nodemanager.vmem-check-enabled</name>
??? <value>false</value>
</property>
</configuration>
5、修改slaves文件內容,該文件指定哪些服務器節點是datanode節點,刪除里面的localhost
cd /home/hadoop/apps/hadoop/hadoop-2.7.7/etc/hadoop
vim slaves
hd1
hd2
hd3
#以上所有配置文件已經配好的,在hd1上將配置好的hadoop-2.7.7目錄復制到hd2,hd3相同目錄
cd /home/hadoop/apps/hadoop
scp -r hadoop-2.7.7 hadoop@hd2:/home/hadoop/apps/hadoop/
scp -r hadoop-2.7.7 hadoop@hd3:/home/hadoop/apps/hadoop/
scp /etc/profile root@hd2:/etc/
并在hd2上執行:source /etc/profile
scp /etc/profile root@hd3:/etc/
并在hd3上執行:source /etc/profile
# 格式化集群操作
#格式化namenode和datanode并啟動,(在hd1(master)上執行就可以了 不需要在(hd2,hd3)slave上執行)
hdfs namenode -format
#關閉所有機器防火墻
service iptables stop
#啟動hadoop集群
#依次執行兩個命令
#啟動hdfs
start-dfs.sh
#再啟動
start-yarn.sh
#直接用一個命令也可以
start_all.sh
#驗證是否啟動成功,缺少以下任一進程都表示出錯
#在hd1,hd2,hd3分別使用jps命令,可以看到
#hd1中顯示
56310 NameNode
56423 DataNode
56809 ResourceManager
56921 NodeManager
56634 SecondaryNameNode
# hd2中顯示
16455 NodeManager
16348 DataNode
#hd3顯示
13716 DataNode
13823 NodeManager
#查看集群web頁面
hdfs頁面:http://hd1:50070/ 或者http://192.168.174.141:50070/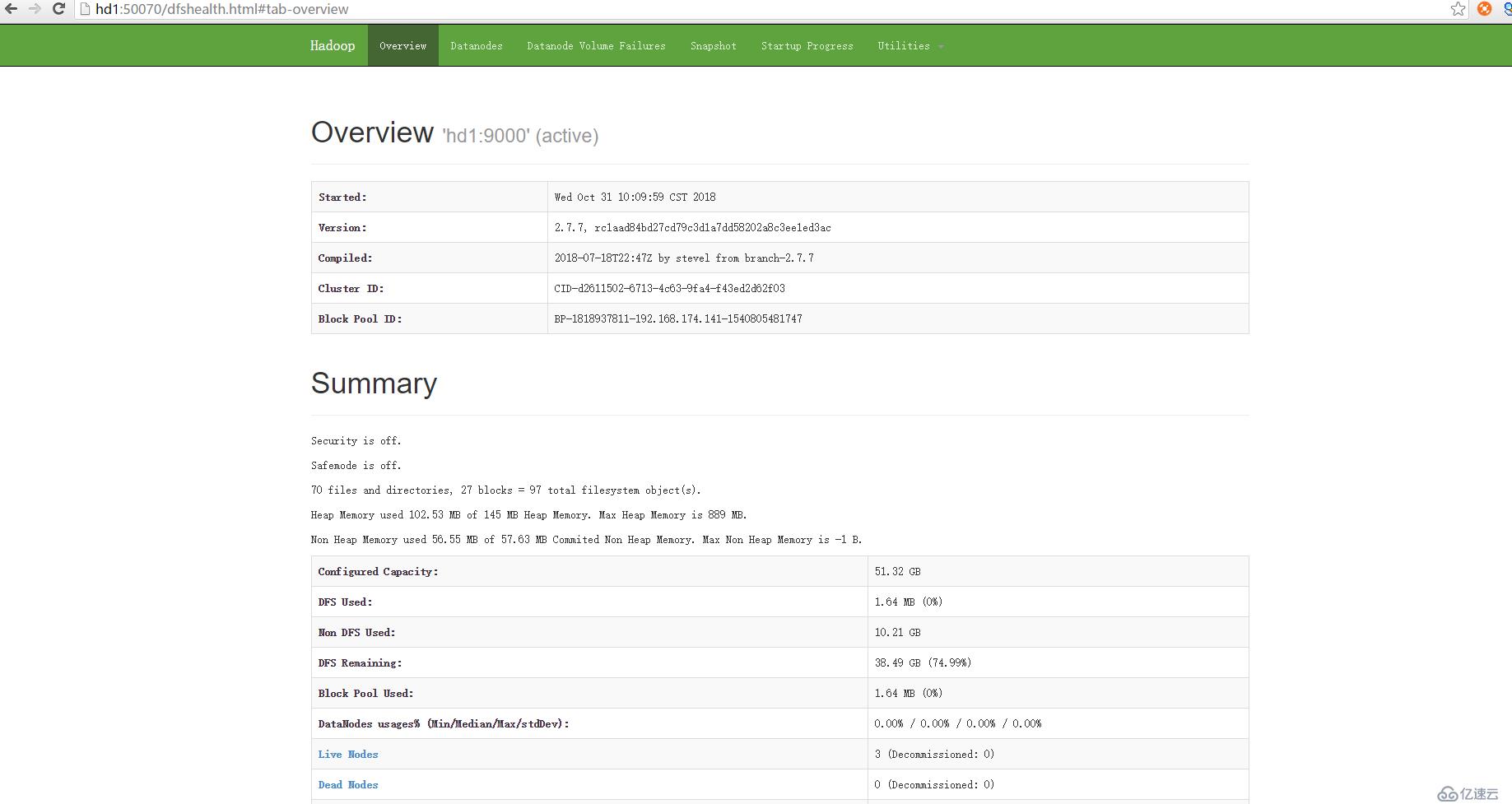
yarn頁面:http://hd1:8088/ 或者http://192.168.174.141:8088/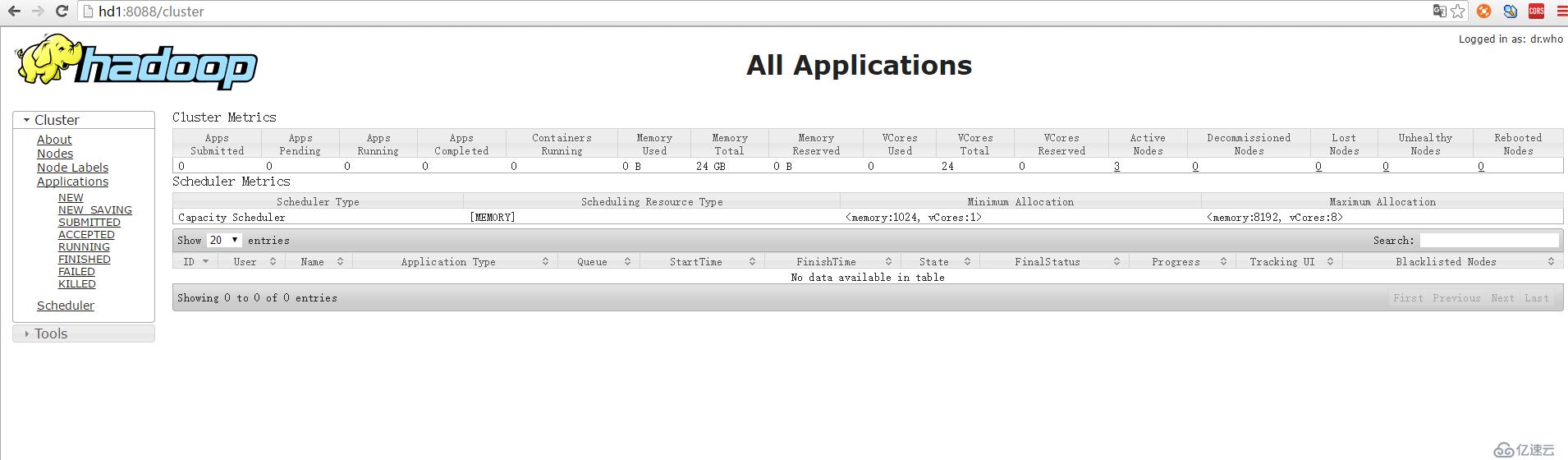
#停止集群命令:stop_dfs.sh和stop_yarn.sh或者stop_all.sh以上Hadoop的集群搭建過程已大功告成!
依賴環境:Scala
Spark是使用Scala編寫的,用Scala編寫Spark任務可以像操作本地集合對象一樣操作分布式數據集RDD
安裝Scalla和安裝jdk如出一轍的操作,我這里給出scala的下載地址:https://downloads.lightbend.com/scala/2.11.7/scala-2.11.7.tgz
#安裝完scala可以查看版本
scala -version
#這里重點介紹Spark的安裝,相比于hadoop的安裝要簡單一些,而且步驟類似,話不多說,開始!
#在hd1機器用hadoop用戶先創建spark的目錄
cd /home/hadoop/apps
mkdir spark
cd spark
#下載spark安裝包
wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.2.2/spark-2.2.2-bin-hadoop2.7.tgz
#解壓
tar -zxvf /spark-2.2.2-bin-hadoop2.7.tgz
#重命名
mv spark-2.2.2-bin-hadoop2.7 spark-2.2.2
#修改環境變量
vim /etc/profile
export SPARK_HOME=/home/hadoop/apps/spark/spark-2.2.2
export PATH=$PATH:$SPARK_HOME/bin
#重新加載環境
source /etc/profile
#修改配置文件
cd /home/hadoop/apps/spark/spark-2.2.2/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
#這里介紹兩個spark的部署模式,一種是standalone模式,一種是spark on yarn模式,任選一種配置即可
#1、standalone模式
export JAVA_HOME=/opt/soft/java/jdk1.8.0_73
#Spark主節點的IP
export SPARK_MASTER_IP=hd1
#Spark主節點的端口號
export SPARK_MASTER_PORT=7077
#2、spark on yarn配置
export JAVA_HOME=/opt/soft/java/jdk1.8.0_73
export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop/hadoop-2.7.7/etc/hadoop/
#修改slaves文件
cd /home/hadoop/apps/spark/spark-2.2.2/conf
vim slaves
hd2
hd3
#復制hd1中的spark到hd2和hd3機器中
cd /home/hadoop/apps/spark
scp -r spark-2.2.2/ hadoop@hd2:/home/hadoop/apps/spark
scp -r spark-2.2.2/ hadoop@hd3:/home/hadoop/apps/spark
#配置環境變量:分別修改hd2,hd3環境變量或者直接將hd1上的/etc/profile文件復制到hd2和hd3上。
vim /etc/profile
export SPARK_HOME=/home/hadoop/apps/spark/spark-2.2.2
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile
#至此,Spark集群配置完畢,啟動Spark集群。
#啟動spark集群前要先啟動hadoop集群。
#Spark集群啟動
cd /home/hadoop/apps/spark/spark-2.2.2/sbin
./start-all.sh
#測試Spark集群是否正常啟動
#在hd1,hd2,hd3分別執行jps,
在hd1中顯示:Master
63124 Jps
56310 NameNode
56423 DataNode
63064 Master
56809 ResourceManager
56921 NodeManager
56634 SecondaryNameNode
在hd2、hd3中顯示:Worker
18148 Jps
16455 NodeManager
16348 DataNode
18079 Worker
#測試spark-shell和頁面
cd /home/hadoop/apps/spark/spark-2.2.2/bin
./spark-shell
#訪問頁面地址:
http://hd1:8080/ 或者:http://192.168.174.141:8080/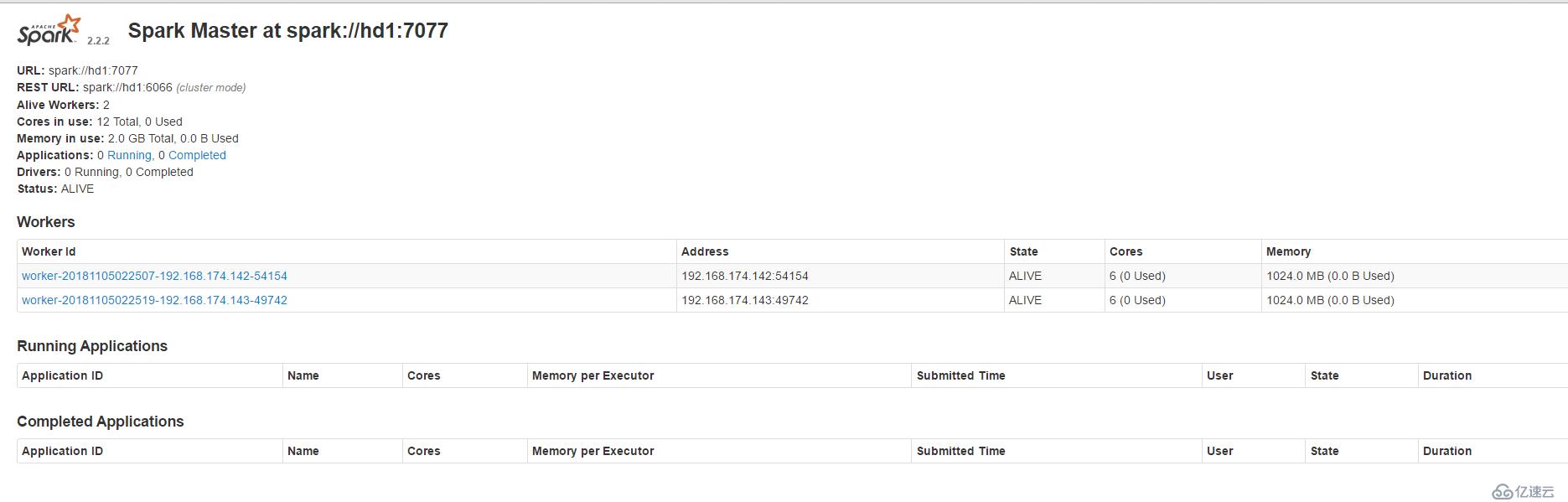
http://hd1:4040/jobs/ 或者 http://192.168.174.141:4040/jobs/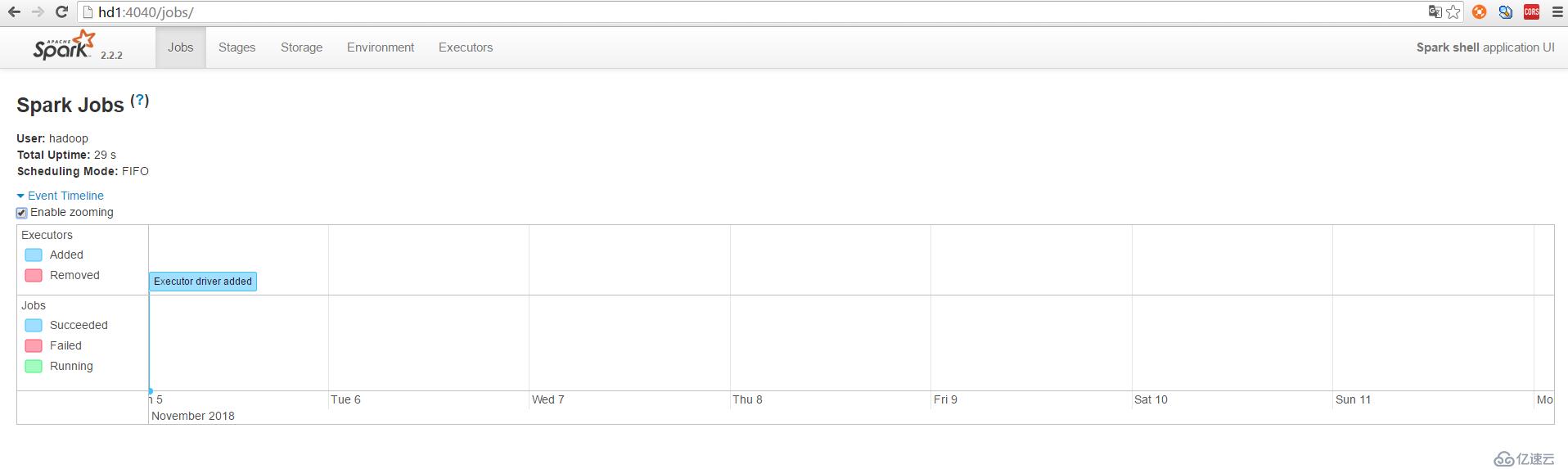
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





