溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行spark術語的解釋及Client分析,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
就像在一家公司里面總有明確的分工,每一哥部分負責自己的那一部分的任務,大家一起來維持公司的正常運轉,同樣的,spark就像是一個公司,他的里面也有許許多多的角色組成
Spark術語解釋:
Master:資源管理的主節點,通過管理各個worker來管理集群中的資源
Worker,master的從節點,與master一起管理集群的資源
Application:用戶所寫的應用程序,就像spark中的HelloWorld的wordcount一樣,他就是一個application
Driver:任務調度的進程,application先交給的就是Driver,因為一個應用程序中有多個task組成,而task是被送到某個Executor上進行執行的工作單元,所以Driver在得到application之后,會將application的task進行規劃,然后分發到executor上進行執行
Executor:worker進程所管理的節點上為某application啟動的一個進程,該進程負責運行任務,說白了就是公司里面的工廠,負責處理Driver發送過來的原材料task,
Job:包含了很多組并行的task,與action算子一一對應,,就像是大貨車在運送材料的時候將貨物進行打包一起運送一樣,將多個task原材料一起打包分發到Executor中進行執行
關系之間的執行關系:
任務層面
Application------由多個job組成(與action的個數相關)------stage------task,是一個個的線程
資源層面
Master--------worker---------executor-------threadpool(task最后的運行地點)
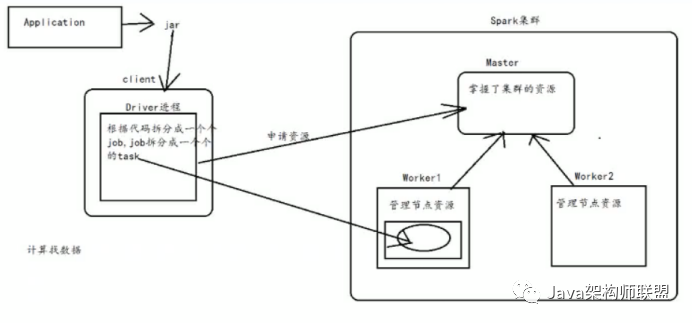
在spark集群中,每個worker管理節點上的資源,而master通過掌握worker來管理整個集群的資源
將application封裝成一個個的jar包然后上傳到client,在client提交應用程序到spark集群中,
在client上就會啟動一個Driver進程,而Driver會根據代碼將application拆分成一個個的job,然后將job拆分成一個個的task,接著向master申請資源,在資源充足的節點上啟動一個executor和一個相應的線程池
Client。在上面的基本流程的時候說到客戶端的一個概念,,那為什么非要使用客戶端而不是直接將任務提交到集群呢,
1、盡量減少集群中各臺服務器之間的性能差異,防止出現木桶效
如果直接提交到集群,會在其中一個worker上啟動一個一個Driver進行任務的拉取和分發,當worker數量過多的時候會造成嚴重的磁盤IO,而且因為長時間使用同一個節點進行分發,頻繁的通信會造成這個節點與其他節點的性能差異,這樣就會出現木桶效應
2、便于維護集群,以防止出現危害集群的行為
當創建客戶端之后,不同的用戶可以使用不同的權限進行程序的提交,在客戶端上可以設置權限的不同,而且,雖然客戶端節點在使用的過程中也會出現木桶效應,但是因為在集群之外,不會對集群產生什么影響
在設置了客戶端避免了一些不必要的影響之后,為了更好地使用集群的性能,就產生了兩種不同的application提交方式
Client
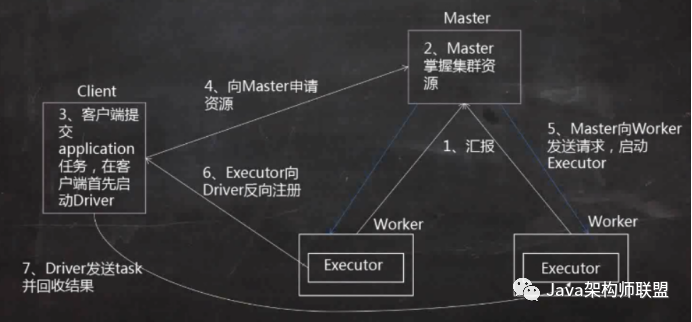
1、worker會向master進行匯報資源情況,
2、master就掌握了集群的資源情況,知道spark中有多少core和memory以及每一個worker管理多少core和memory
3、使用spark-submit在客戶端上提交一個application,在client上會啟動一個Driver進程
4、driver進程啟動之后會去master申請資源,
5、Master會發送請求在資源充足的worker節點上啟動executor
6、Executor啟動之后會向Driver反向注冊,也就知道了一共有多少個executor進行計算
7、Driver發送task并回收計算結果,監控executor的計算進程,包括出現錯誤進行重試以及task的運行日志
Cluster
Client提交方式存在一定的風險,當task數量過多之后,計算結果都會被回收到Driver端,可能會造成Driver的異常退出,無法進行任務的調度,也就是無法提交程序到集群中
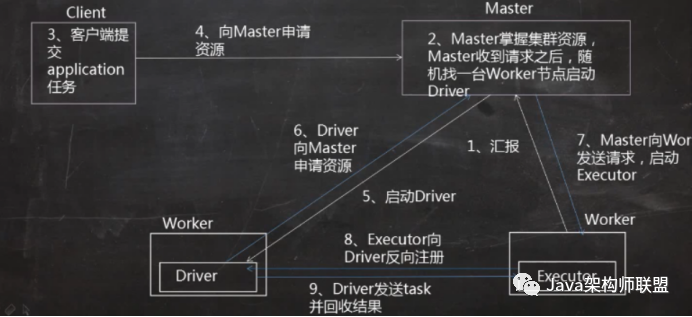
運行程序和client基本相同,不同的地方是Driver會在其中一個資源比較充足的worker節點上進行啟動,同樣的,Driver啟動起來之后會去申請資源,在worker節點上啟動Executor上,然后反向注冊給Driver,但是,cluster提交方式的不同的地方是他不會將計算結果拉回到客戶端進行查看,也就是說在client上不能實施的監控集群的運行情況,只能去web層面進行查看
那這兩種提交方式的不同,下面的表格進行了相應的講解

看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





