溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何分析Spark名詞解釋及關系,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
名詞
driver
driver物理層面是指輸入提交spark命令的啟動程序,邏輯層面是負責調度spark運行流程包括向master申請資源,拆解任務,代碼層面就是sparkcontext。
worker
worker指可以運行的物理節點。
executor
executor指執行spark任務的處理程序,對java而言就是擁有一個jvm的進程。一個worker節點可以運行多個executor,只要有足夠的資源。
job
job是指一次action,rdd(rdd在這里就不解釋了)操作分成兩大類型,一類是transform,一類是action,當涉及到action的時候,spark就會把上次action之后到本次action的所有rdd操作用一個job完成。
stage
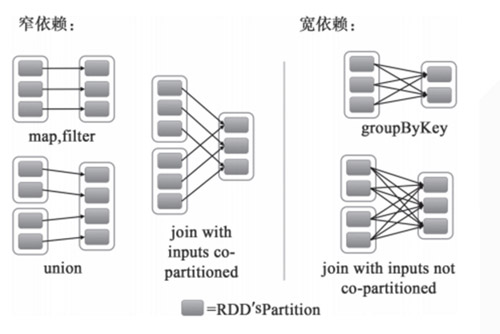
stage是指一次shuffle,rdd在操作的時候分為寬依賴(shuffle dependency)和窄依賴(narraw dependency),如下圖所示。而寬依賴就是指shuffle。
應某人要求再解釋一下什么是窄依賴,就是父rdd的每個分區都只作用在一個子rdd的分區中,原話是這么說的 each partition of the parent RDD is used by at most one partition of the child RDD。
task
task是spark的最小執行單位,一般而言執行一個partition的操作就是一個task,關于partition的概念,這里稍微解釋一下。
spark的默認分區數是2,并且最小分區也是2,改變分區數的方式有很多,大概有三個階段
1.啟動階段,通過 spark.default.parallelism 來初始化默認分區數
2.生成rdd階段,可通過參數配置
3.rdd操作階段,默認繼承父rdd的partition數,最終結果受shuffle操作和非shuffle操作的影響,不同操作的結果partition數不同
名詞關系
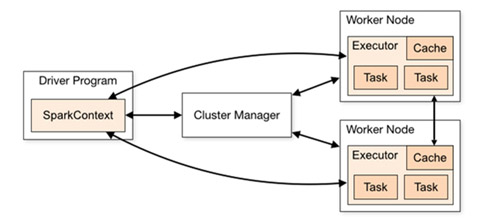
物理關系
官網給出的spark運行架構圖
邏輯關系
下圖是總結的邏輯關系圖,如果有不對之處,還望提醒。

關于如何分析Spark名詞解釋及關系問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





