溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python中怎么利用Torchmoji將文本轉換為表情符號,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
這些代碼并不完全是我的寫的,源代碼可以在這個鏈接上找到。
!pip3 install torch==1.0.1 -f https://download.pytorch.org/whl/cpu/stable
!git clone https://github.com/huggingface/torchMoji
import os
os.chdir('torchMoji')
!pip3 install -e .
#if you restart the package, the notebook risks to crash on a loop
#I did not restart and worked fine該代碼將下載約600 MB的數據用于訓練人工智能。我一直在用谷歌Colab。然而,我注意到,當程序要求您重新啟動筆記本進行所需的更改時,它開始在循環中崩潰并且無法補救。如果你使用的是jupyter notebook或者colab記事本不要重新,不管它的重啟要求就可以了。
!python3 scripts/download_weights.py
這個腳本應該下載需要微調神經網絡模型。詢問時,按“是”確認。
使用以下函數,可以輸入文進行轉換,該函數將輸出最可能的n個表情符號(n將被指定)。
import numpy as np
import emoji, json
from torchmoji.global_variables import PRETRAINED_PATH, VOCAB_PATH
from torchmoji.sentence_tokenizer import SentenceTokenizer
from torchmoji.model_def import torchmoji_emojis
EMOJIS = ":joy: :unamused: :weary: :sob: :heart_eyes: :pensive: :ok_hand: :blush: :heart: :smirk: :grin: :notes: :flushed: :100: :sleeping: :relieved: :relaxed: :raised_hands: :two_hearts: :expressionless: :sweat_smile: :pray: :confused: :kissing_heart: :heartbeat: :neutral_face: :information_desk_person: :disappointed: :see_no_evil: :tired_face: :v: :sunglasses: :rage: :thumbsup: :cry: :sleepy: :yum: :triumph: :hand: :mask: :clap: :eyes: :gun: :persevere: :smiling_imp: :sweat: :broken_heart: :yellow_heart: :musical_note: :speak_no_evil: :wink: :skull: :confounded: :smile: :stuck_out_tongue_winking_eye: :angry: :no_good: :muscle: :facepunch: :purple_heart: :sparkling_heart: :blue_heart: :grimacing: :sparkles:".split(' ')
model = torchmoji_emojis(PRETRAINED_PATH)
with open(VOCAB_PATH, 'r') as f:
vocabulary = json.load(f)
st = SentenceTokenizer(vocabulary, 30)def deepmojify(sentence,top_n =5):
def top_elements(array, k):
ind = np.argpartition(array, -k)[-k:]
return ind[np.argsort(array[ind])][::-1]tokenized, _, _ = st.tokenize_sentences([sentence])
prob = model(tokenized)[0]
emoji_ids = top_elements(prob, top_n)
emojis = map(lambda x: EMOJIS[x], emoji_ids)
return emoji.emojize(f"{sentence} {' '.join(emojis)}", use_aliases=True)text = ['I hate coding AI']for _ in text:
print(deepmojify(_, top_n = 3))輸出

如您所見,這里給出的是個列表,所以可以添加所需的字符串數。
如果你不知道如何編碼,你只想試一試,你可以使用DeepMoji的網站:https://deepmoji.mit.edu/

源代碼應該完全相同,事實上,如果我輸入5個表情符號而不是3個,這就是我代碼中的結果:

在進行情緒分析時,我通常會在Pandas上存儲tweets或評論的數據庫,我將使用以下代碼,將字符串列表轉換為Pandas數據幀,其中包含指定數量的emojis。
import pandas as pddef emoji_dataset(list1, n_emoji=3):
emoji_list = [[x] for x in list1]for _ in range(len(list1)):
for n_emo in range(1, n_emoji+1):
emoji_list[_].append(deepmojify(list1[_], top_n = n_emoji)[2*-n_emo+1])emoji_list = pd.DataFrame(emoji_list)
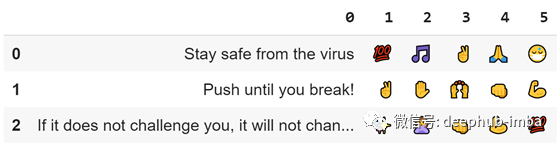
return emoji_listlist1 = ['Stay safe from the virus', 'Push until you break!', 'If it does not challenge you, it will not change you']我想估計一下這個字符串列表中最有可能出現的5種表情:
emoji_dataset(list1, 5)
關于Python中怎么利用Torchmoji將文本轉換為表情符號就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





