溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“direct Dstream是什么”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“direct Dstream是什么”這篇文章吧。
前言
前面,有分享過基于receiver的,實際上,看到receiver based Dstream大家就對閱讀提不起興趣了,實際上這是錯誤的,基于receiver的才是spark streaming根本,雖然direct stream才更合適。但是,我們從基于receiver可以學到很多內容,最重要的spark streaming實現原理,數據本地性等。
direct dstream運行架構圖
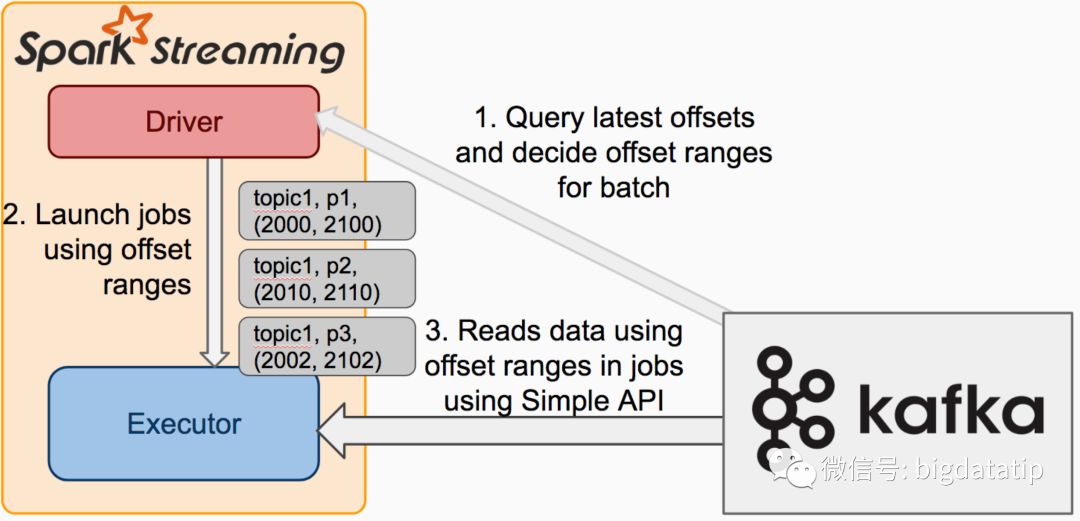
對比
對比receiver based的Dstream和direct Dstream
a 無需啟動receiver,減少不必要的cpu占用
b 減少了receiver接收數據,寫入blockmanager,然后運行時再通過blockid,網絡傳輸,磁盤讀區,來獲取數據這個過程。提升了效率。
c 無需wal,進一步減少磁盤讀寫。
d 可以通過手動維護offset來實現精確的一次消費。
e Dstream中生成的RDD,并不是blockrdd,而是kafkardd,kafkardd是和kafka分區一一對應的,更便于我們把控并行度。
f 數據本地性的問題,導致receiver存在的機器會運行過多的任務,會導致有些executor空閑。
而kafkardd,在compute函數里,會使用simpleconsumer,根據指定的topic,分區,offset范圍,去kafka讀取數據。010版本以后,又存在假如kafka和spark運行于同一集群,會有數據本性的概念。
數據本地性
spark streaming與kafka 082結合生成的rdd,數據本地性計算方式如下:
override def getPreferredLocations(thePart: Partition): Seq[String] = {
val part = thePart.asInstanceOf[KafkaRDDPartition]
// TODO is additional hostname resolution necessary here
Seq(part.host)
}
spark streaming 與kafka 010結合生成的rdd,數據本地性計算方式如下:
override def getPreferredLocations(thePart: Partition): Seq[String] = {
// The intention is best-effort consistent executor for a given topicpartition,
// so that caching consumers can be effective.
// TODO what about hosts specified by ip vs name
val part = thePart.asInstanceOf[KafkaRDDPartition]
val allExecs = executors()
val tp = part.topicPartition
val prefHost = preferredHosts.get(tp)
val prefExecs = if (null == prefHost) allExecs else allExecs.filter(_.host == prefHost)
val execs = if (prefExecs.isEmpty) allExecs else prefExecs
if (execs.isEmpty) {
Seq.empty
} else {
// execs is sorted, tp.hashCode depends only on topic and partition, so consistent index
val index = Math.floorMod(tp.hashCode, execs.length)
val chosen = execs(index)
Seq(chosen.toString)
}
}
對于 與kafka010結合的注意事項,實際上以前浪尖也翻譯過一篇文章。
必讀:Spark與kafka010整合
限速
限速,很多人使用姿勢不對,詳細的原理可以參看
Spark的PIDController源碼賞析及backpressure詳解
具體配置參數詳解,可以參考:
spark.streaming.backpressure.enabled 默認是false,設置為true,就開啟了背壓機制。
spark.streaming.backpressure.initialRate 默認沒設置,初始速率。第一次啟動的時候每個receiver接受數據的最大值。
spark.streaming.receiver.maxRate 默認值沒設置。每個接收器將接收數據的最大速率(每秒記錄數)。 實際上,每個流每秒最多將消費此數量的記錄。 將此配置設置為0或負數將不會對速率進行限制。
spark.streaming.kafka.maxRatePerPartition 使用新Kafka direct API時從每個Kafka分區讀取數據的最大速率(每秒記錄數)。
以上是“direct Dstream是什么”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





