溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關Kubernetes attach/detach controller邏輯漏洞致使pod啟動失敗該怎么辦,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
通過深入學習k8s attach/detach controller源碼,了解現網案例發現的attach/detach controller bug發生的原委,并給出解決方案。
我們首先了解下現網案例的問題和現象;然后去深入理解ad controller維護的數據結構;之后根據數據結構與ad controller的代碼邏輯,再來詳細分析現網案例出現的原因和解決方案。從而深入理解整個ad controller。
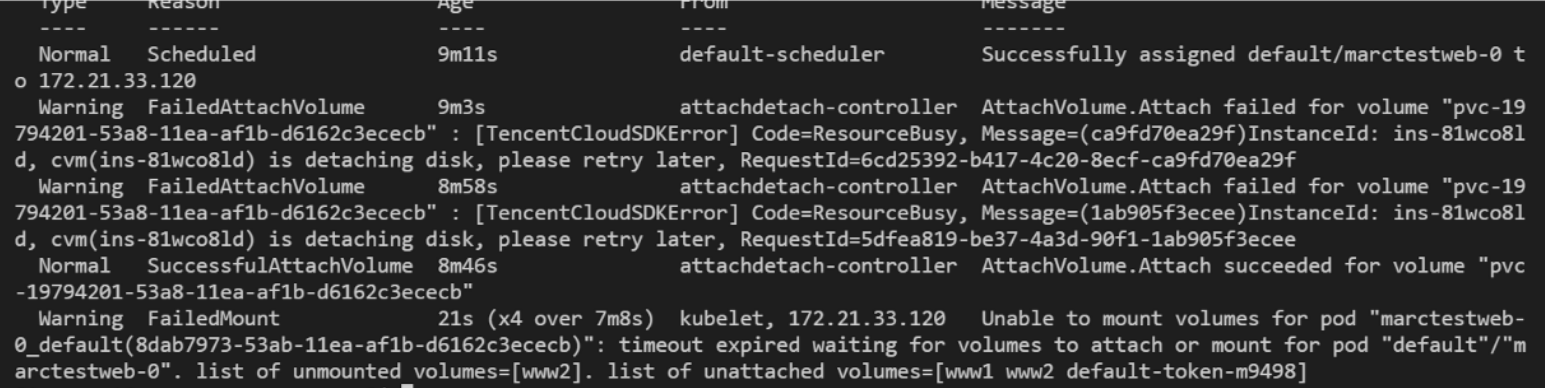
一個statefulsets(sts)引用了多個pvc cbs,我們更新sts時,刪除舊pod,創建新pod,此時如果刪除舊pod時cbs detach失敗,且創建的新pod調度到和舊pod相同的節點,就可能會讓這些pod一直處于ContainerCreating 。
kubectl describe pod
kubelet log

kubectl get node xxx -oyaml 的volumesAttached和volumesInUse
volumesAttached: - devicePath: /dev/disk/by-id/virtio-disk-6w87j3wv name: kubernetes.io/qcloud-cbs/disk-6w87j3wv volumesInUse: - kubernetes.io/qcloud-cbs/disk-6w87j3wv - kubernetes.io/qcloud-cbs/disk-7bfqsft5
k8s中attach/detach controller負責存儲插件的attach/detach。本文結合現網出現的一個案例來分析ad controller的源碼邏輯,該案例是因k8s的ad controller bug導致的pod創建失敗。
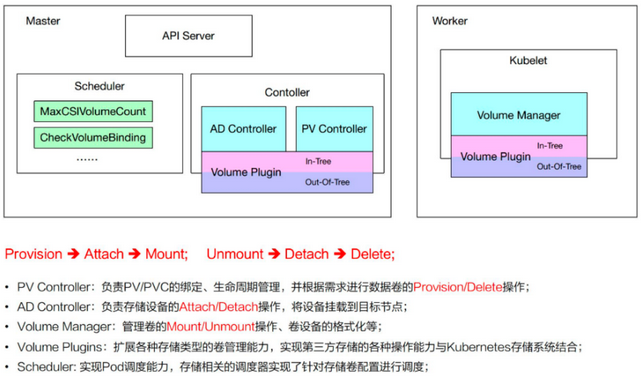
k8s中涉及存儲的組件主要有:attach/detach controller、pv controller、volume manager、volume plugins、scheduler。每個組件分工明確:
attach/detach controller:負責對volume進行attach/detach
pv controller:負責處理pv/pvc對象,包括pv的provision/delete(cbs intree的provisioner設計成了external provisioner,獨立的cbs-provisioner來負責cbs pv的provision/delete)
volume manager:主要負責對volume進行mount/unmount
volume plugins:包含k8s原生的和各廠商的的存儲插件
原生的包括:emptydir、hostpath、flexvolume、csi等
各廠商的包括:aws-ebs、azure、我們的cbs等
scheduler:涉及到volume的調度。比如對ebs、csi等的單node最大可attach磁盤數量的predicate策略
控制器模式是k8s非常重要的概念,一般一個controller會去管理一個或多個API對象,以讓對象從實際狀態/當前狀態趨近于期望狀態。
所以attach/detach controller的作用其實就是去attach期望被attach的volume,detach期望被detach的volume。
后續attach/detach controller簡稱ad controller。
對于ad controller來說,理解了其內部的數據結構,再去理解邏輯就事半功倍。ad controller在內存中維護2個數據結構:
actualStateOfWorld —— 表征實際狀態(后面簡稱asw)
desiredStateOfWorld —— 表征期望狀態(后面簡稱dsw)
很明顯,對于聲明式API來說,是需要隨時比對實際狀態和期望狀態的,所以ad controller中就用了2個數據結構來分別表征實際狀態和期望狀態。
actualStateOfWorld 包含2個map:
attachedVolumes: 包含了那些ad controller認為被成功attach到nodes上的volumes
nodesToUpdateStatusFor: 包含要更新node.Status.VolumesAttached 的nodes
1、在啟動ad controller時,會populate asw,此時會list集群內所有node對象,然后用這些node對象的node.Status.VolumesAttached 去填充attachedVolumes。
2、之后只要有需要attach的volume被成功attach了,就會調用MarkVolumeAsAttached(GenerateAttachVolumeFunc 中)來填充到attachedVolumes中。
1、只有在volume被detach成功后,才會把相關的volume從attachedVolumes中刪掉。(GenerateDetachVolumeFunc 中調用MarkVolumeDetached)
1、detach volume失敗后,將volume add back到nodesToUpdateStatusFor
- GenerateDetachVolumeFunc 中調用AddVolumeToReportAsAttached
1、在detach volume之前會先調用RemoveVolumeFromReportAsAttached 從nodesToUpdateStatusFor中先刪除該volume相關信息
desiredStateOfWorld 中維護了一個map:
nodesManaged:包含被ad controller管理的nodes,以及期望attach到這些node上的volumes。
1、在啟動ad controller時,會populate asw,list集群內所有node對象,然后把由ad controller管理的node填充到nodesManaged
2、ad controller的nodeInformer watch到node有更新也會把node填充到nodesManaged
3、另外在populate dsw和podInformer watch到pod有變化(add, update)時,往nodesManaged 中填充volume和pod的信息
4、desiredStateOfWorldPopulator 中也會周期性地去找出需要被add的pod,此時也會把相應的volume和pod填充到nodesManaged
1、當刪除node時,ad controller中的nodeInformer watch到變化會從dsw的nodesManaged 中刪除相應的node
2、當ad controller中的podInformer watch到pod的刪除時,會從nodesManaged 中刪除相應的volume和pod
3、desiredStateOfWorldPopulator 中也會周期性地去找出需要被刪除的pod,此時也會從nodesManaged 中刪除相應的volume和pod
ad controller的邏輯比較簡單:
1、首先,list集群內所有的node和pod,來populate actualStateOfWorld (attachedVolumes )和desiredStateOfWorld (nodesManaged)
2、然后,單獨開個goroutine運行reconciler,通過觸發attach, detach操作周期性地去reconcile asw(實際狀態)和dws(期望狀態)
觸發attach,detach操作也就是,detach該被detach的volume,attach該被attach的volume
3、之后,又單獨開個goroutine運行DesiredStateOfWorldPopulator ,定期去驗證dsw中的pods是否依然存在,如果不存在就從dsw中刪除
接下來結合上面所說的現網案例,來詳細看看reconciler的邏輯。
從pod的事件可以看出來:ad controller認為cbs attach成功了,然后kubelet沒有mount成功。
但是從kubelet日志卻發現Volume not attached according to node status ,也就是說kubelet認為cbs沒有按照node的狀態去掛載。這個從node info也可以得到證實:volumesAttached 中的確沒有這個cbs盤(disk-7bfqsft5)。
node info中還有個現象:volumesInUse 中還有這個cbs。說明沒有unmount成功
很明顯,cbs要能被pod成功使用,需要ad controller和volume manager的協同工作。所以這個問題的定位首先要明確:
volume manager為什么認為volume沒有按照node狀態掛載,ad controller卻認為volume attch成功了?
volumesAttached和volumesInUse 在ad controller和kubelet之間充當什么角色?
這里只對分析volume manager做簡要分析。
根據Volume not attached according to node status 在代碼中找到對應的位置,發現在GenerateVerifyControllerAttachedVolumeFunc 中。仔細看代碼邏輯,會發現
此時會先從volume manager的dsw緩存中獲取要被mount的volumes(volumesToMount的podsToMount )
然后遍歷,驗證每個volumeToMount是否已經attach了
驗證邏輯中,在GenerateVerifyControllerAttachedVolumeFunc中會去遍歷本節點的node.Status.VolumesAttached,如果沒有找到就報錯(Volume not attached according to node status)
這個volumeToMount是由podManager中的podInformer加入到相應內存中,然后desiredStateOfWorldPopulator周期性同步到dsw中的
volume manager的reconciler會先確認該被unmount的volume被unmount掉
然后確認該被mount的volume被mount
所以可以看出來,volume manager就是根據volume是否存在于node.Status.VolumesAttached 中來判斷volume有無被attach成功。
那誰去填充node.Status.VolumesAttached ?ad controller的數據結構nodesToUpdateStatusFor 就是用來存儲要更新到node.Status.VolumesAttached 上的數據的。
所以,如果ad controller那邊沒有更新node.Status.VolumesAttached,而又新建了pod,desiredStateOfWorldPopulator 從podManager中的內存把新建pod引用的volume同步到了volumesToMount中,在驗證volume是否attach時,就會報錯(Volume not attached according to node status)
當然,之后由于kublet的syncLoop里面會調用WaitForAttachAndMount 去等待volumeattach和mount成功,由于前面一直無法成功,等待超時,才會有會面timeout expired 的報錯
所以接下來主要需要看為什么ad controller那邊沒有更新node.Status.VolumesAttached。
reconciler詳解接下來詳細分析下ad controller的邏輯,看看為什么會沒有更新node.Status.VolumesAttached,但從事件看ad controller卻又認為volume已經掛載成功。
從流程簡述中表述可見,ad controller主要邏輯是在reconciler中。
reconciler定時去運行reconciliationLoopFunc,周期為100ms。
reconciliationLoopFunc的主要邏輯在reconcile()中:
遍歷dsw的nodesManaged,判斷volume是否已經被attach到該node,如果已經被attach到該node,則跳過attach操作
去asw.attachedVolumes中判斷是否存在,若不存在就認為沒有attach到node
而attachedConfirmed是由asw中AddVolumeNode去設置的,MarkVolumeAsAttached設置為true。(true即代表該volume已經被attach到該node了)
若存在,再判斷node,node也匹配就返回attachedConfirmed
之后判斷是否禁止多掛載,再由operator_excutor去執行attach
遍歷asw中的attachedVolumes,對于每個volume,判斷其是否存在于dsw中
如果volume存在于asw,且不存在于dsw,則意味著需要進行detach
之后,根據node.Status.VolumesInUse來判斷volume是否已經unmount完成,unmount完成或者等待6min timeout時間到后,會繼續detach邏輯
在執行detach volume之前,會先調用RemoveVolumeFromReportAsAttached從asw的nodesToUpdateStatusFor中去刪除要detach的volume
然后patch node,也就等于從node.status.VolumesAttached刪除這個volume
之后進行detach,detach失敗主要分2種
backoff周期起始為500ms,之后指數遞增至2min2s。已經detach失敗了的volume,在每個周期期間進入detach邏輯都會直接返回backoffError
根據nodeName去dsw.nodesManaged中判斷node是否存在
存在的話,再根據volumeName判斷volume是否存在
如果真正執行了volumePlugin的具體實現DetachVolume失敗,會把volume add back到nodesToUpdateStatusFor(之后在attach邏輯結束后,會再次patch node)
如果是operator_excutor判斷還沒到backoff周期,就會返回backoffError,直接跳過DetachVolume
首先,確保該被detach的volume被detach掉
之后,確保該被attach的volume被attach成功
最后,UpdateNodeStatuses去更新node status
前提
volume detach失敗
sts+cbs(pvc),pod recreate前后調度到相同的node
涉及k8s組件
ad controller
kubelet(volume namager)
ad controller和kubelet(volume namager)通過字段node.status.VolumesAttached交互。
ad controller為node.status.VolumesAttached新增或刪除volume,新增表明已掛載,刪除表明已刪除
kubelet(volume manager)需要驗證新建pod中的(pvc的)volume是否掛載成功,存在于node.status.VolumesAttached中,則表明驗證volume已掛載成功;不存在,則表明還未掛載成功。
以下是整個過程:
首先,刪除pod時,由于某種原因cbs detach失敗,失敗后就會backoff重試。
由于detach失敗,該volume也不會從asw的attachedVolumes中刪除
由于detach時,
先從node.status.VolumesAttached中刪除volume,之后才去執行detach
detach時返回backoffError不會把該volumeadd back node.status.VolumesAttached
之后,我們在backoff周期中(假如就為第一個周期的500ms中間)再次創建sts,pod被調度到之前的node
而pod一旦被創建,就會被添加到dsw的nodesManaged(nodeName和volumeName都沒變)
reconcile()中的第2步,會去判斷volume是否被attach,此時發現該volume同時存在于asw和dws中,并且由于detach失敗,也會在檢測時發現還是attach,從而設置attachedConfirmed為true
ad controller就認為該volume被attach成功了
reconcile()中第1步的detach邏輯進行判斷時,發現要detach的volume已經存在于dsw.nodesManaged了(由于nodeName和volumeName都沒變),這樣volume同時存在于asw和dsw中了,實際狀態和期望狀態一致,被認為就不需要進行detach了。
這樣,該volume之后就再也不會被add back到node.status.VolumesAttached。所以就出現了現象中的node info中沒有該volume,而ad controller又認為該volume被attach成功了
由于kubelet(volume manager)與controller manager是異步的,而它們之間交互是依據node.status.VolumesAttached ,所以volume manager在驗證volume是否attach成功,發現node.status.VolumesAttached中沒有這個voume,也就認為沒有attach成功,所以就有了現象中的報錯Volume not attached according to node status
之后kubelet的syncPod在等待pod所有的volume attach和mount成功時,就超時了(現象中的另一個報錯timeout expired wating...)。
所以pod一直處于ContainerCreating
所以,該案例出現的原因是:
sts+cbs,pod recreate時間被調度到相同的node
由于detach失敗,backoff期間創建sts/pod,致使ad controller中的dsw和asw數據一致(此時該volume由于沒有被detach成功而確實處于attach狀態),從而導致ad controller認為不再需要去detach該volume。
又由于detach時,是先從node.status.VolumesAttached中刪除該volume,再去執行真正的DetachVolume。backoff期間直接返回backoffError,跳過DetachVolume,不會add back
之后,ad controller因volume已經處于attach狀態,認為不再需要被attach,就不會再向node.status.VolumesAttached中添加該volume
最后,kubelet與ad controller交互就通過node.status.VolumesAttached,所以kubelet認為沒有attach成功,新創建的pod就一直處于ContianerCreating了
據此,我們可以發現關鍵點在于node.status.VolumesAttached和以下兩個邏輯:
detach時backoffError,不會add back
detach是先刪除,失敗再add back
所以只要想辦法能在任何情況下add back就不會有問題了。根據以上兩個邏輯就對應有以下2種解決方案,推薦使用方案2:
這個方案能避免方案1的問題,且會進一步減少請求apiserver的次數,且改動也不多
pr #88572
但這種方式有個缺點:patch node的請求數增加了10+次/(s * volume)
pr #72914
一進入detach邏輯就判斷是否backoffError(處于backoff周期中),是就跳過之后所有detach邏輯,不刪除就不需要add back了。
backoffError時,也add back
AD Controller負責存儲的Attach、Detach。通過比較asw和dsw來判斷是否需要attach/detach。最終attach和detach結果會體現在node.status.VolumesAttached。
以上現網案例出現的現象,是k8s ad controller的bug導致,目前社區并未修復。
先刪除舊pod過程中detach失敗,而在detach失敗的backoff周期中創建新pod,此時由于ad controller邏輯bug,導致volume被從node.status.VolumesAttached中刪除,從而導致創建新pod時,kubelet檢查時認為該volume沒有attach成功,致使pod就一直處于ContianerCreating。
現象出現的原因主要是:
而現象的解決方案,推薦使用pr #88572。目前TKE已經有該方案的穩定運行版本,在灰度中。
上述就是小編為大家分享的Kubernetes attach/detach controller邏輯漏洞致使pod啟動失敗該怎么辦了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





