溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Prometheus怎么使用”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Prometheus怎么使用”吧!
一個谷歌云平臺賬號(免費的即可),其他云也是一樣的
Rancher v2.4.2(文章發布時的最新版本)
運行在GKE(版本為1.15.11-gke.3)上的Kubernetes集群(EKS或者AKS也可以)
首先,啟動一個Rancher實例。你可以根據Rancher的指引啟動:
https://www.rancher.cn/quick-start/
使用Rancher來設置并配置一個Kubernetes集群。你可以訪問下方鏈接獲取文檔:
https://rancher2.docs.rancher.cn/docs/cluster-provisioning/_index
我們將利用Rancher的應用商店來安裝Prometheus。Rancher的應用商店主要集合了許多Helm Chart,以便于用戶能夠重復部署應用程序。
我們的集群起來并且開始運行之后,讓我們在“Apps”的標簽下選擇為其創建的默認項目,然后單擊“Launch”按鈕。

現在我們來搜索我們感興趣的chart。我們可以設置很多字段——但是對于本次demo來說我們將保留默認值。你可以在Detailed Description部分找到關于這些值的有用信息。無需擔心出現問題,盡管去查看它們的用途。在頁面底部,點擊【Launch】。Prometheus Server以及Alertmanager將會被安裝以及配置。
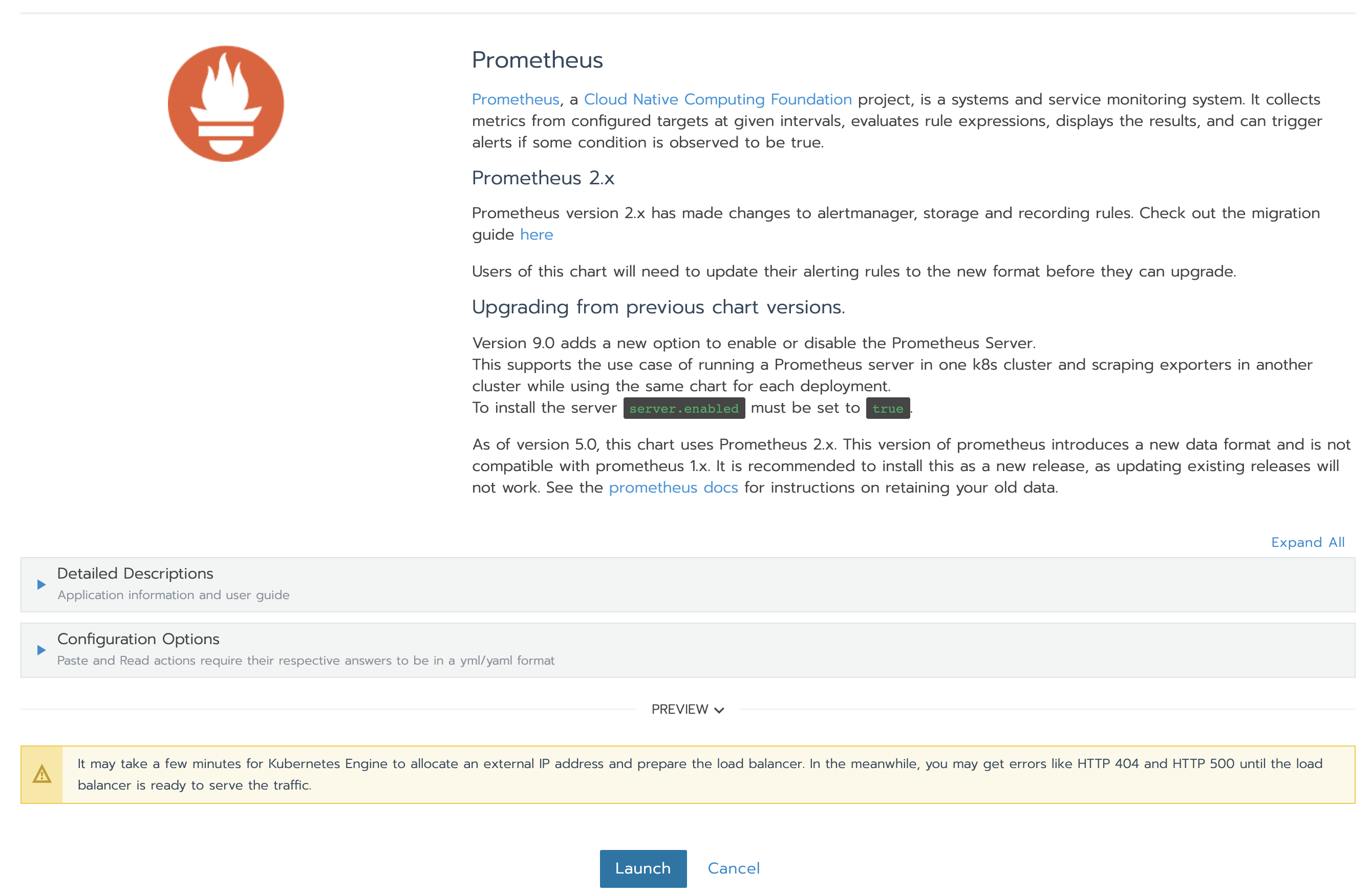
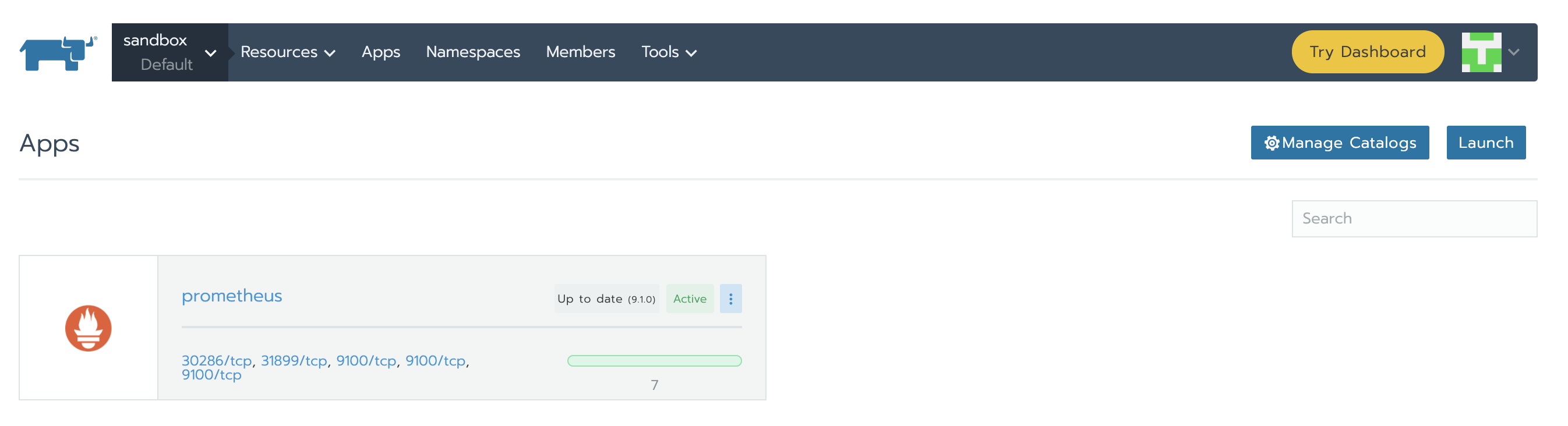
當安裝完成時,頁面如下所示:
接下來,我們需要創建Services以訪問Prometheus Server以及Alertmanager。點開資源下方的工作負載標簽,在負載均衡部分,我們可以看到目前還沒有配置。點擊導入YAML,選擇prometheus namespace,一次性復制兩個YAML并點擊導入。稍后你將了解我們如何知道使用那些特定的端口和組件tag。
apiVersion: v1 kind: Service metadata: name: prometheus-service spec: type: LoadBalancer ports: - port: 80 targetPort: 9090 protocol: TCP selector: component: server
apiVersion: v1 kind: Service metadata: name: alertmanager-service spec: type: LoadBalancer ports: - port: 80 targetPort: 9093 protocol: TCP selector: component: alertmanager
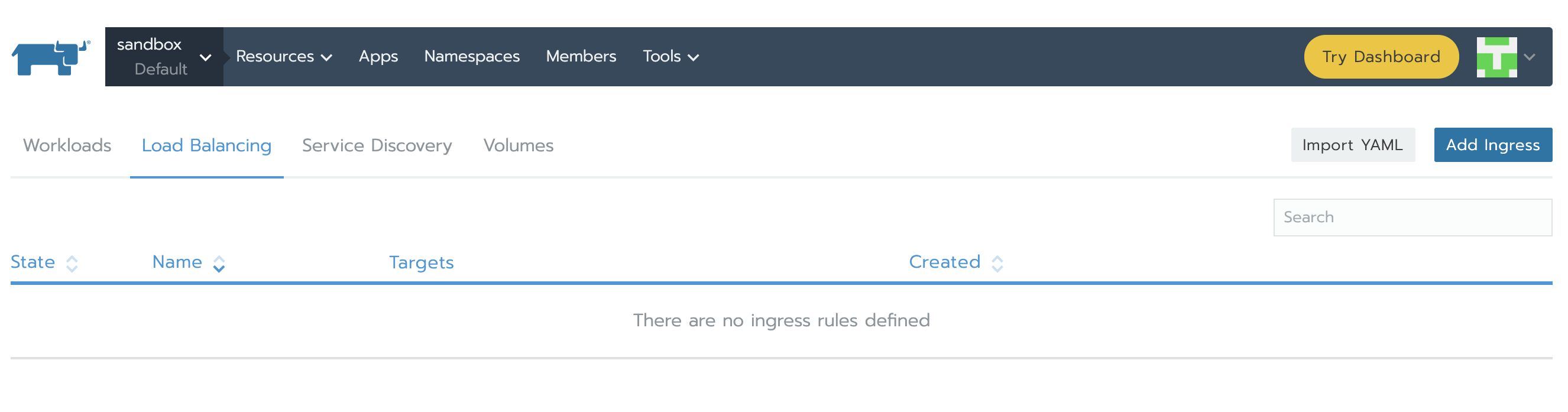
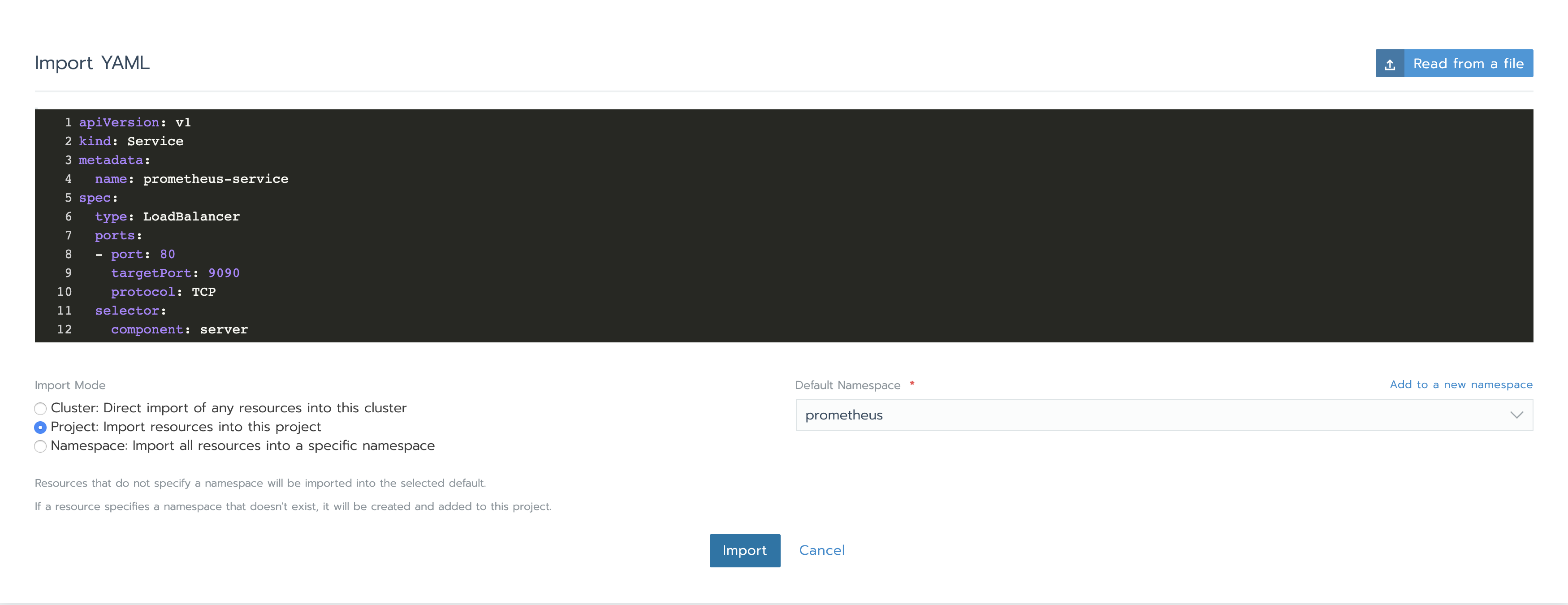
完成之后,service將顯示Active。
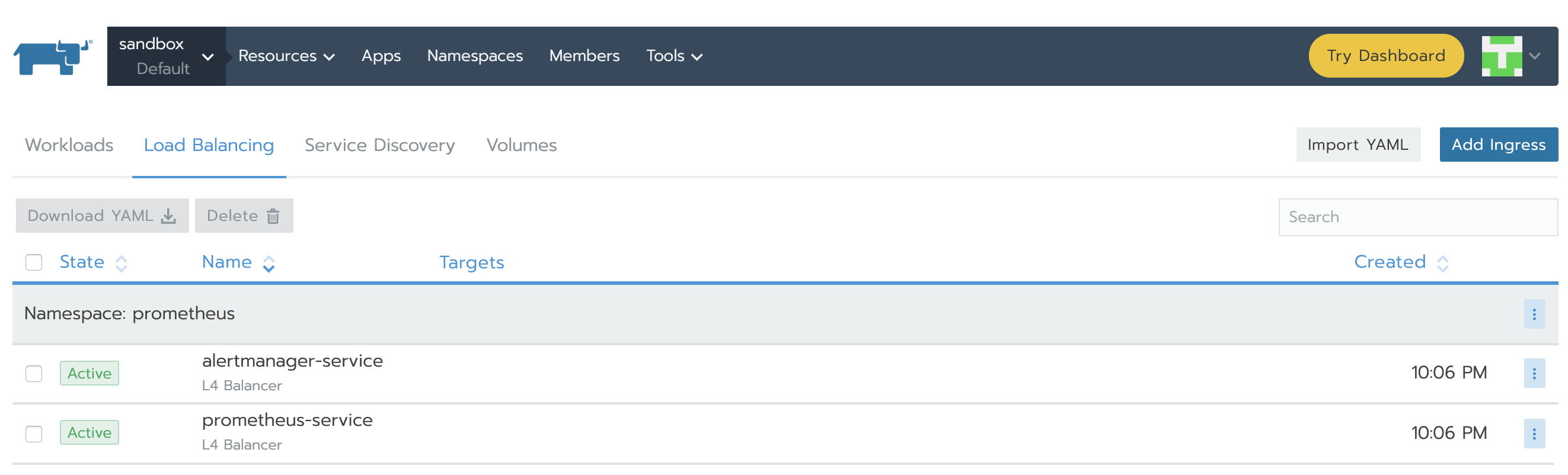
在右側垂直省略號的下拉菜單里你能找到IP并點擊View/Edit YAML。在yaml文件的底部,你將會看到類似的部分:
status: loadBalancer: ingress: - ip: 34.76.22.14
訪問IP將為我們展示Prometheus Server和Alertmanager的GUI。你會發現這時沒有什么內容可以查看的,因為尚未定義規則以及配置告警。
規則可以讓我們觸發告警。這些規則都是基于Prometheus的表達式語言。無論何時,只要符合條件,告警就會被觸發并發送給Alertmanager。
現在來看看我們如何添加規則。
在資源->工作負載標簽下,我們可以看到Deployment在運行chart時創建了什么。我們來詳細看看prometheus-server和prometheus-alertmanager。
我們從第一個開始并理解其配置,我們如何編輯它并了解服務在哪個端口上運行。點擊垂直省略號菜單按鈕并點擊View/Edit YAML。
首先,我們看到的是兩個與Deplolyment關聯的容器:prometheus-server-configmap-reload和prometheus-server。容器prometheus-server的專屬部分有一些相關信息:
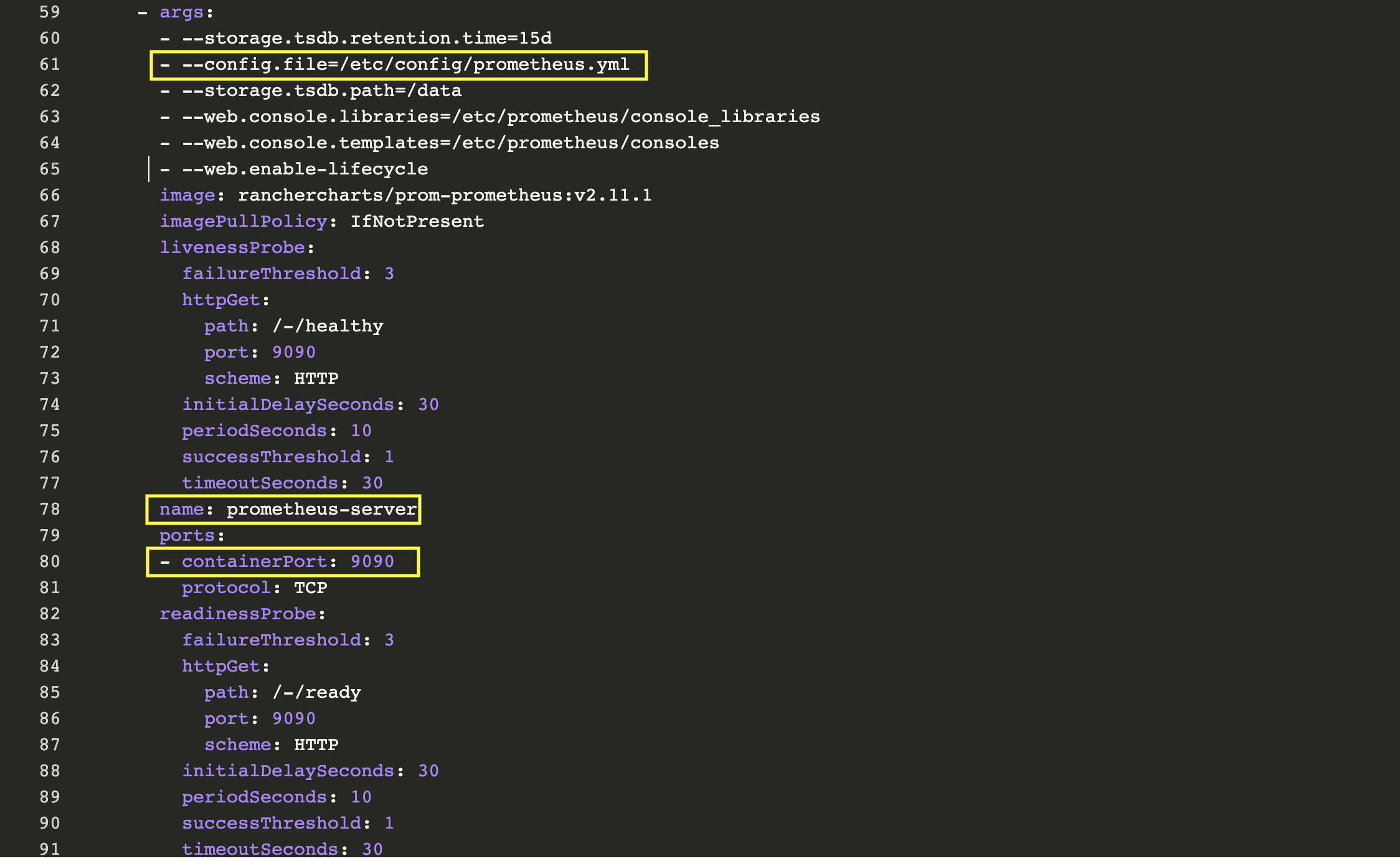
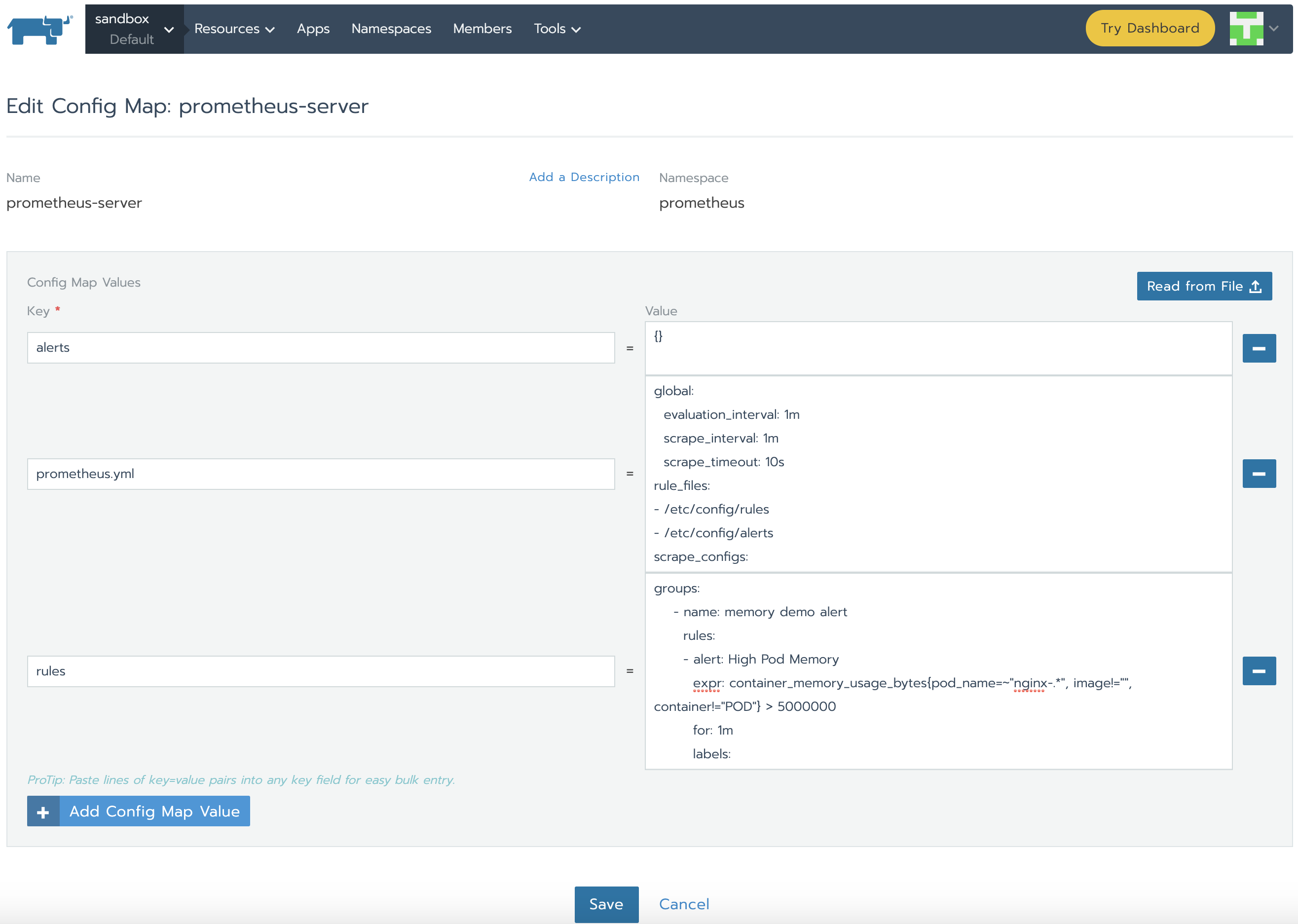
正如我們所了解的,Prometheus通過prometheus.yml進行配置。該文件(以及其他在serverFiles中列出的文件)將掛載到server pod。為了添加/編輯規則,我們需要修改這個文件。實際上,這就是一個Config Map,可以在Resources Config的標簽頁下找到。點擊垂直的省略菜單按鈕并Edit。在規則部分,讓我們添加新的規則并點擊保存。
groups:
- name: memory demo alert
rules:
- alert: High Pod Memory
expr: container_memory_usage_bytes{pod_name=~"nginx-.*", image!="", container!="POD"} > 5000000
for: 1m
labels:
severity: critical
annotations:
summary: High Memory Usage
- name: cpu demo alert
rules:
- alert: High Pod CPU
expr: rate (container_cpu_usage_seconds_total{pod_name=~"nginx-.*", image!="", container!="POD"}[5m]) > 0.04
for: 1m
labels:
severity: critical
annotations:
summary: High CPU Usage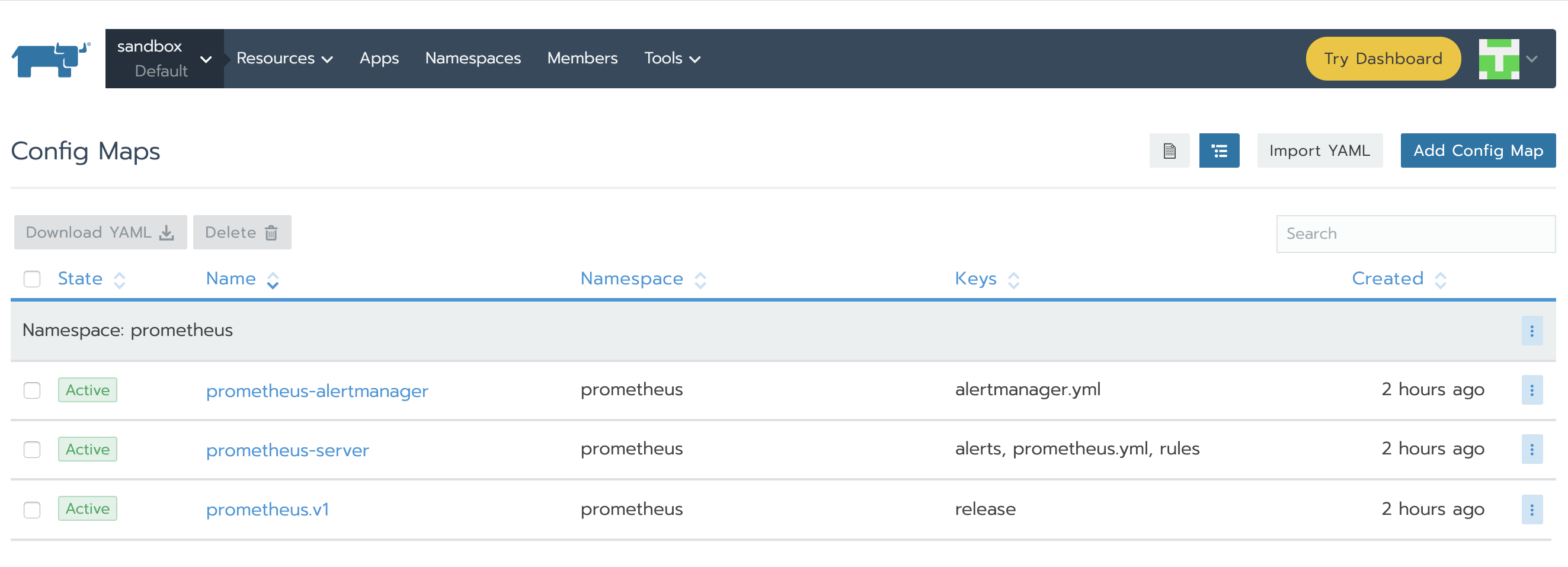
規則將會由Prometheus Server自動加載,然后我們在Prometheus Server GUI中能看到它們:
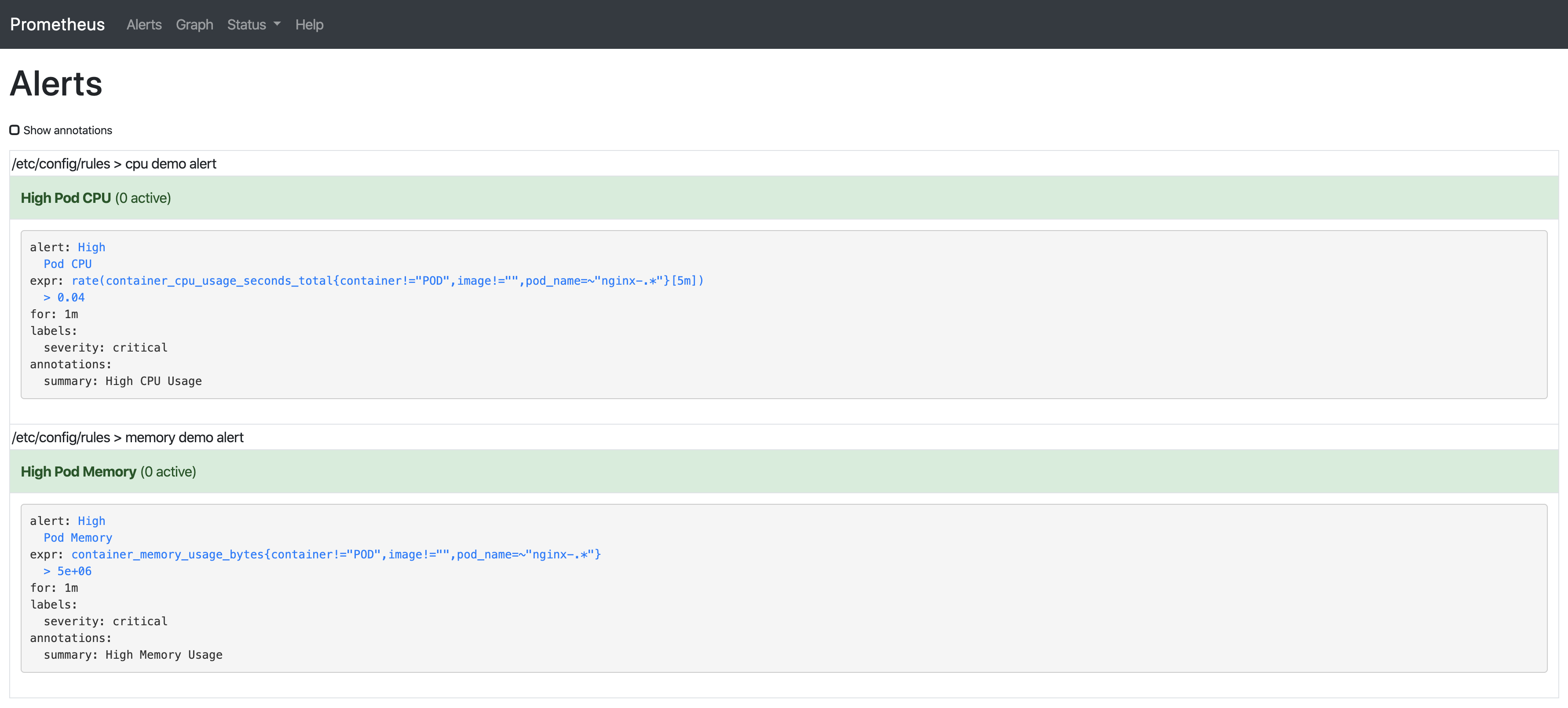
這是關于以上兩條規則的解釋:
container_memory_usage_bytes:當前內存使用情況(以字節為單位),包括所有內存,無論任何時候訪問。
container_cpu_usage_seconds_total:累積的CPU時間(以秒為單位)
所有的指標都能夠在以下頁面中找到:
https://github.com/google/cadvisor/blob/master/metrics/prometheus.go
在Prometheus中所有正則表達式都使用RE2 syntax。使用正則表達式,我們只能為名稱與特定模式匹配的Pod選擇時間序列。在我們的示例中,我們需要尋找以nginx-開頭的pod,并且排除“POD”,因為這是容器的父cgroup,而且會顯示pod內所有容器的統計信息。
對于container_cpu_usage_seconds_total來說,我們使用所謂的子查詢(Subquery)。它會每5分鐘返回我們的指標。
如果你想了解更多關于查詢以及例子,可以在官方的Prometheus文檔中查看。
只要出現問題,告警就能立即提醒我們,使得我們能夠立刻知道系統中發生了錯誤。而Prometheus通過Alertmanager組件來提供告警。
與Prometheus Server的操作步驟相同:在資源->工作負載標簽頁下,點擊prometheus-alertmanager右側菜單欄按鈕,選擇View/Edit YAML,檢查其配置:
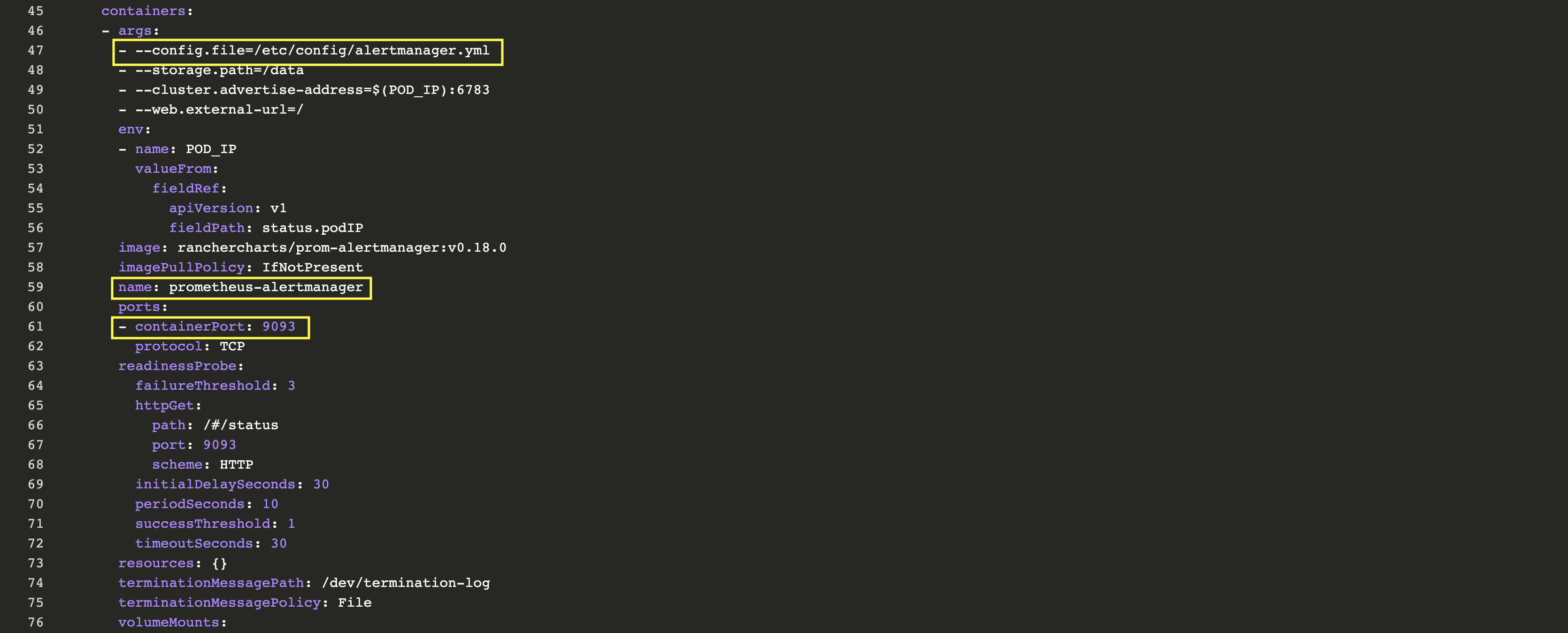
Alertmanager通過alertmanager.yml進行配置。該文件(及其他列在alertmanagerFiles內的文件)將掛載到alertmanager pod上。接下來我們需要修改與alertmanager相關聯的configMap以便于設置告警。在Config標簽頁下,點擊prometheus-alertmanager行的菜單欄,然后選擇Edit。使用以下代碼代替基本配置:
global: resolve_timeout: 5m route: group_by: [Alertname] # Send all notifications to me. receiver: demo-alert group_wait: 30s group_interval: 5m repeat_interval: 12h routes: - match: alertname: DemoAlertName receiver: "demo-alert" receivers: - name: demo-alert email_configs: - to: your_email@gmail.com from: from_email@gmail.com # Your smtp server address smarthost: smtp.gmail.com:587 auth_username: from_email@gmail.com auth_identity: from_email@gmail.com auth_password: 16letter_generated token # you can use gmail account password, but better create a dedicated token for this headers: From: from_email@gmail.com Subject: "Demo ALERT"
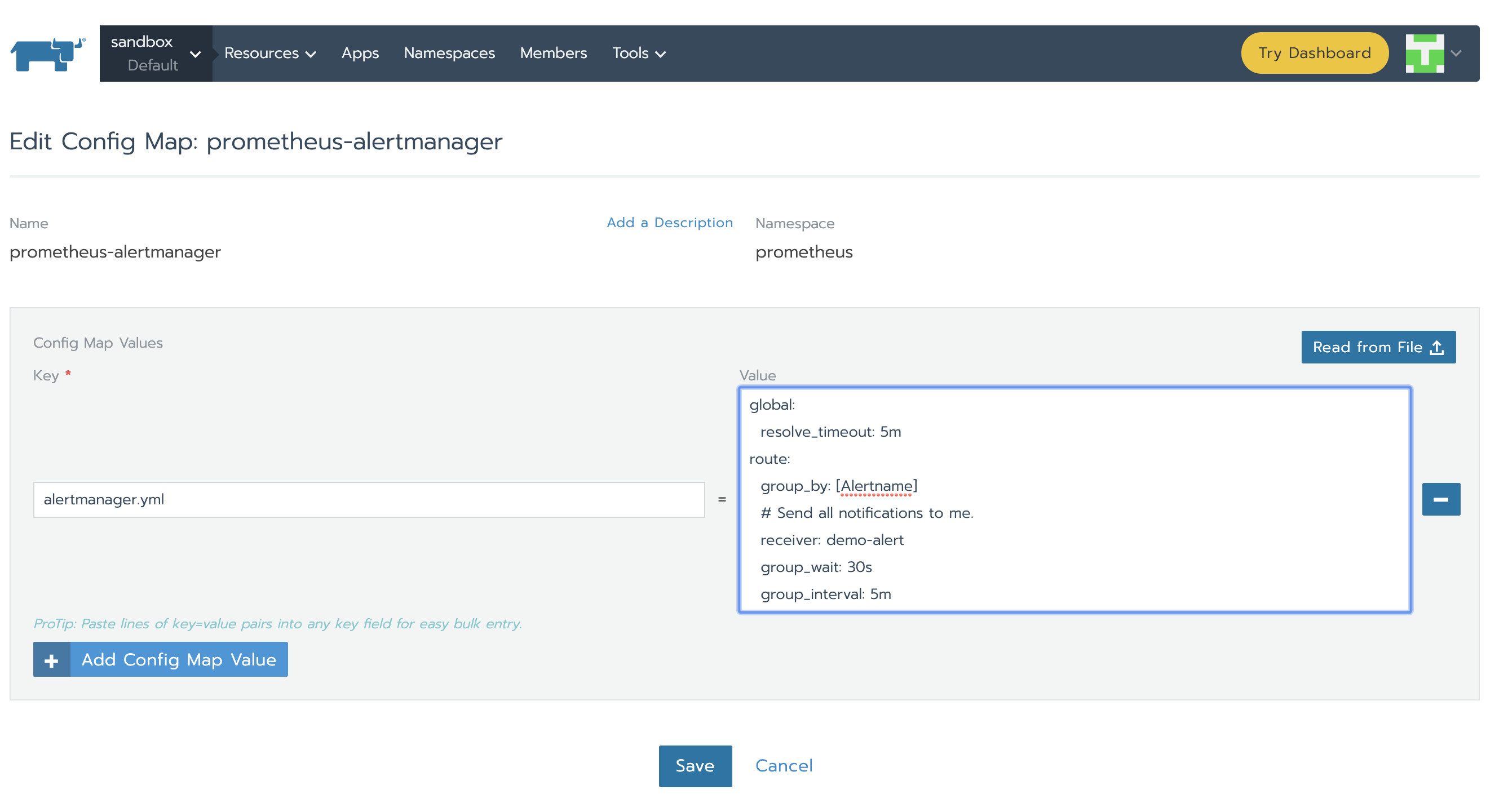
新配置將會由Alertmanager重新加載,并且我們能在Status標簽頁下看到GUI。
讓我們部署一些組件來進行監控。對于練習來說部署一個簡單的nginx deployment就足夠了。使用Rancher GUI,在資源->工作負載標簽頁下點擊導入YAML,粘貼以下代碼(本次使用默認的命名空間)并點擊導入:
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2 kind: Deployment metadata: name: nginx-deployment spec: selector: matchLabels: app: nginx replicas: 3 # tells deployment to run 2 pods matching the template template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80
在Prometheus UI中,我們為使用此前為告警配置的兩個表達式中的1個來查看一些指標:
rate (container_cpu_usage_seconds_total{pod_name=~"nginx-.*", image!="", container!="POD"}[5m])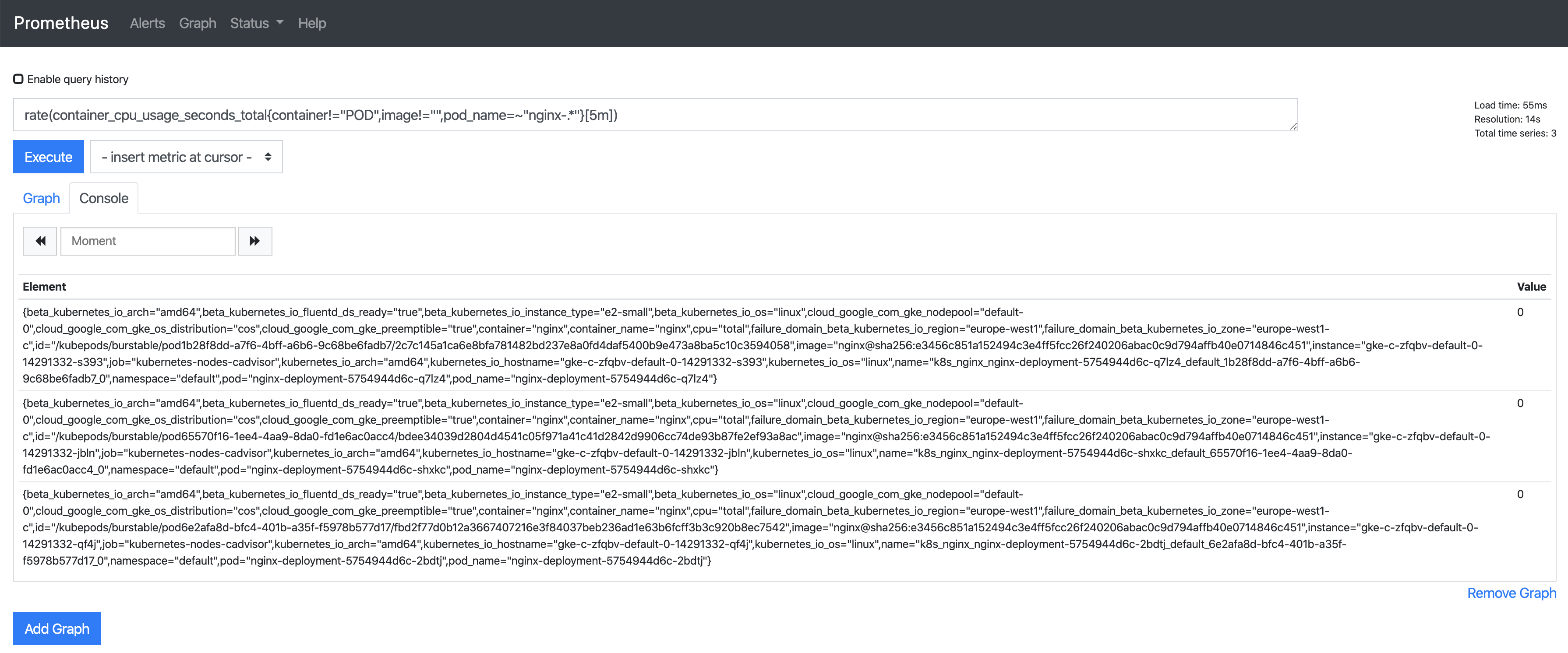
讓我們在其中一個Pod中添加一些負載以查看值的變化。當值大于0.04時,我們應該獲得告警。為此,我們需要選擇其中一個nginx Deployment Pod并點擊Execute Shell。在其中我們將執行一個命令:
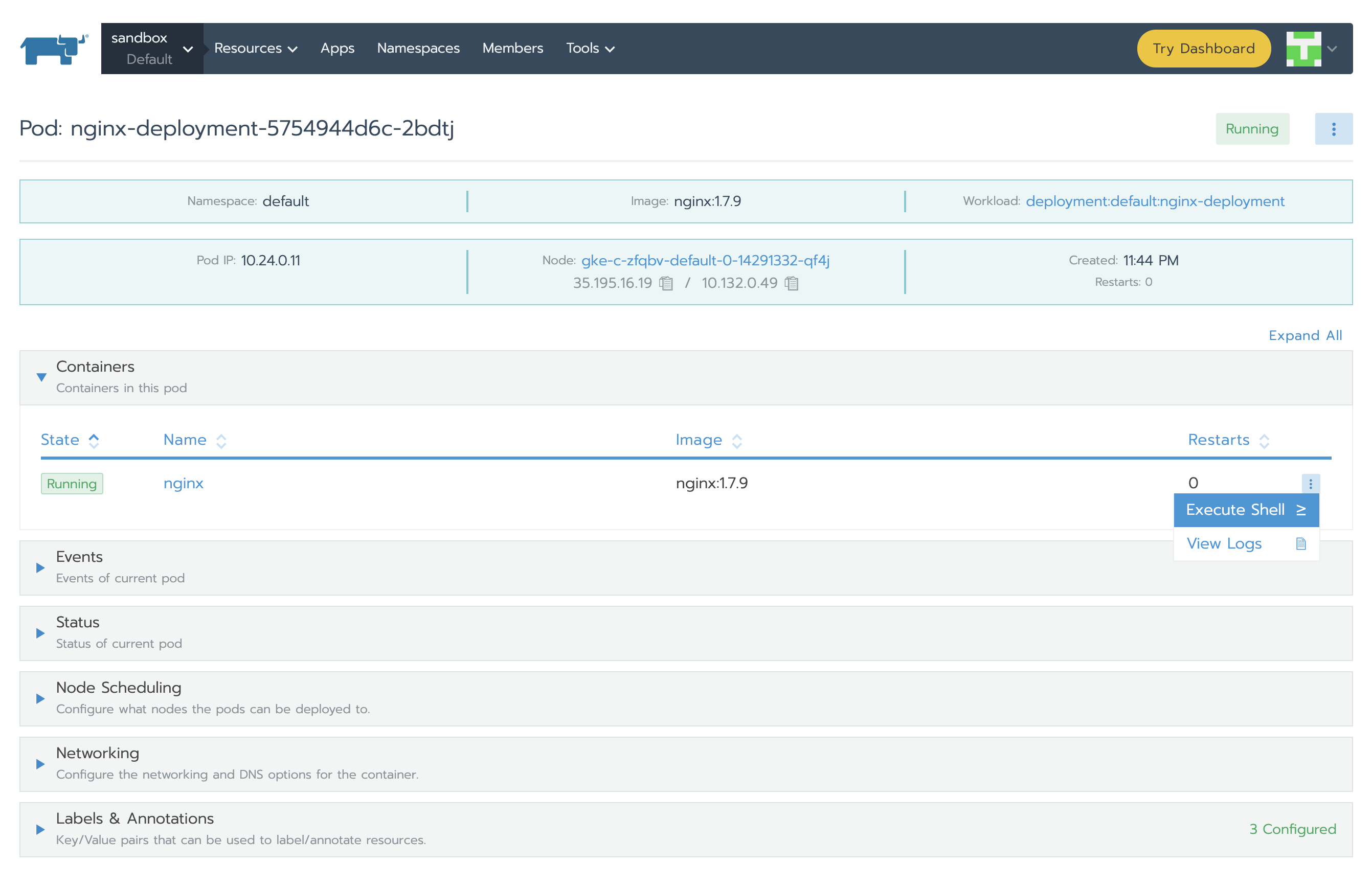
告警有3個階段:
Inactive-條件不滿足
Pending-滿足條件
Firing-告警被觸發
我們已經看到告警處于inactive狀態,所以繼續在CPU上增加負載讓我們能觀察到剩余兩種狀態:
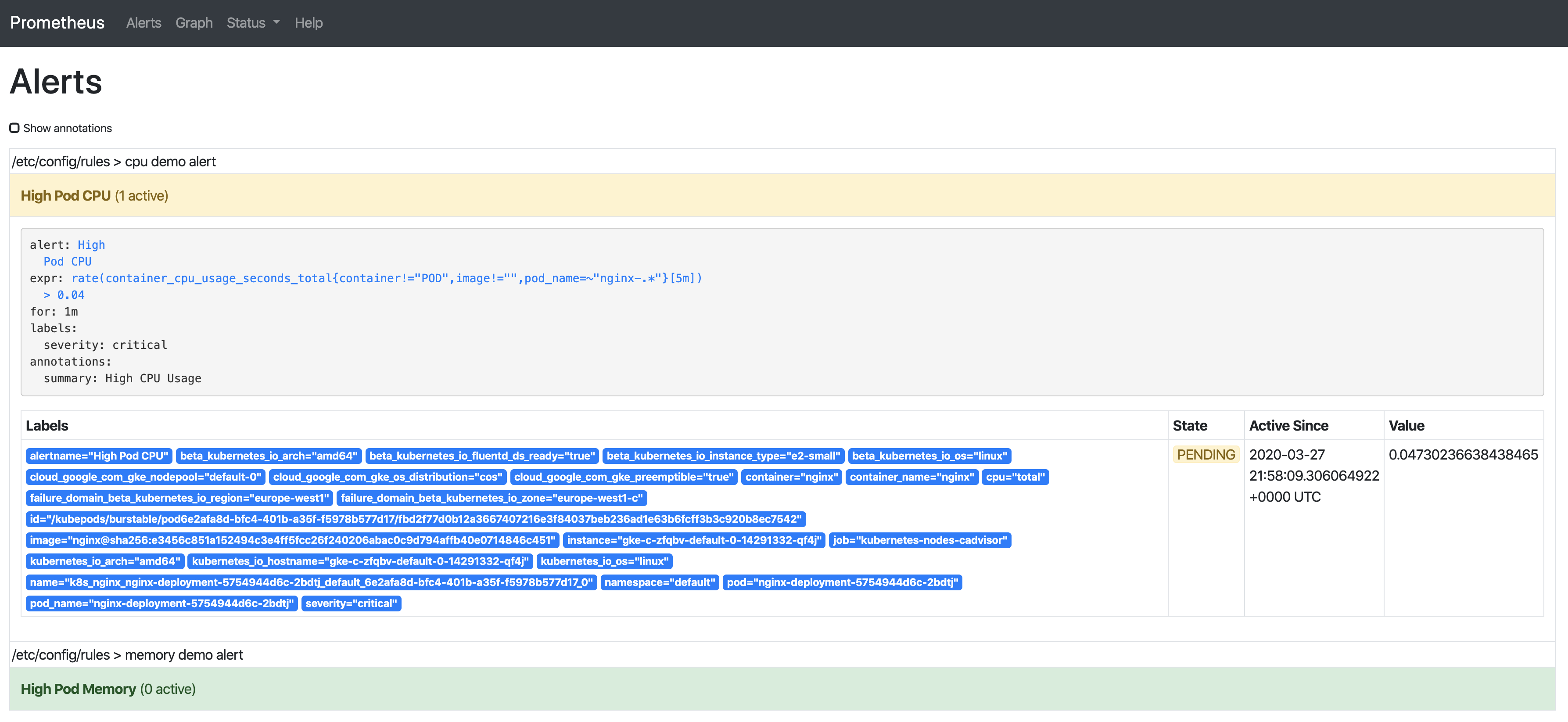
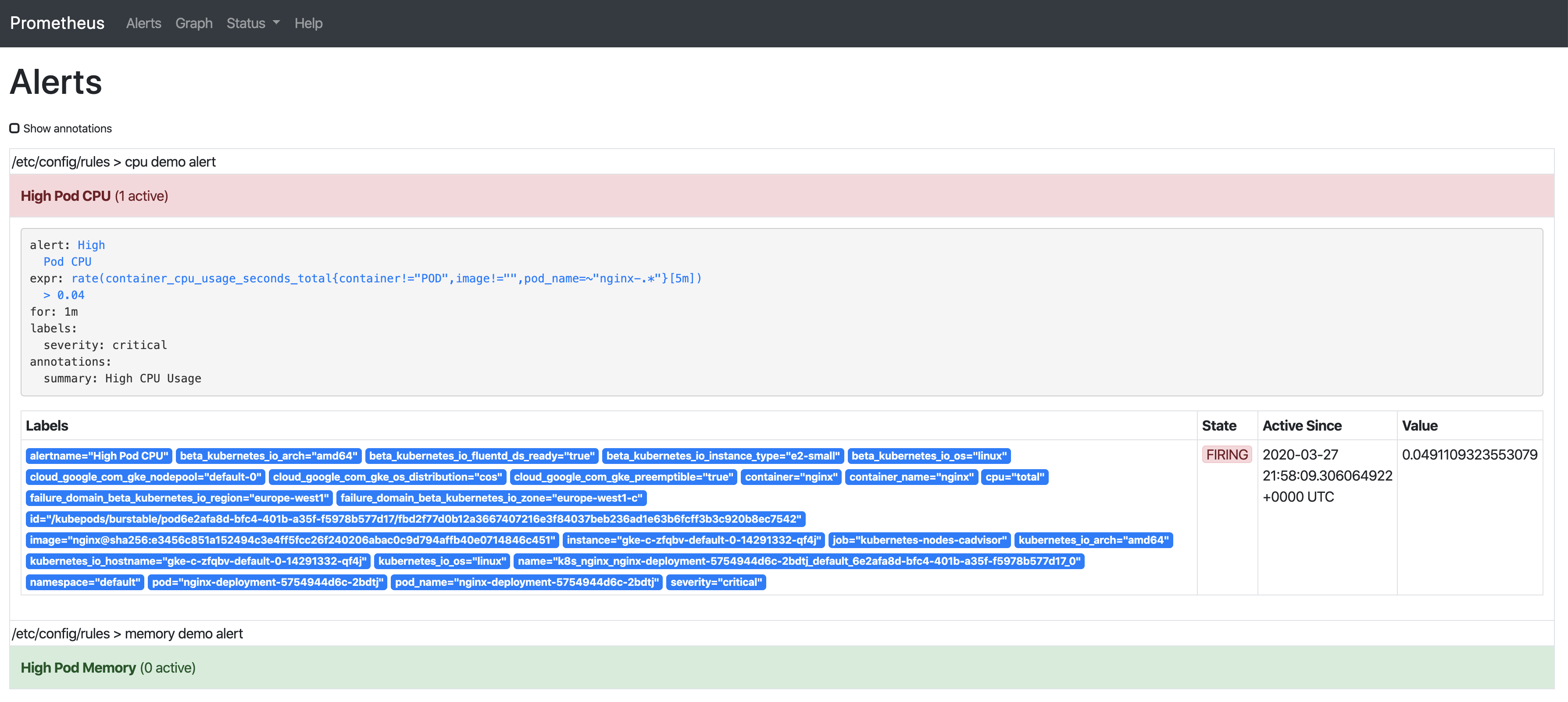
只要告警觸發,將會顯示在Alertmanager中:
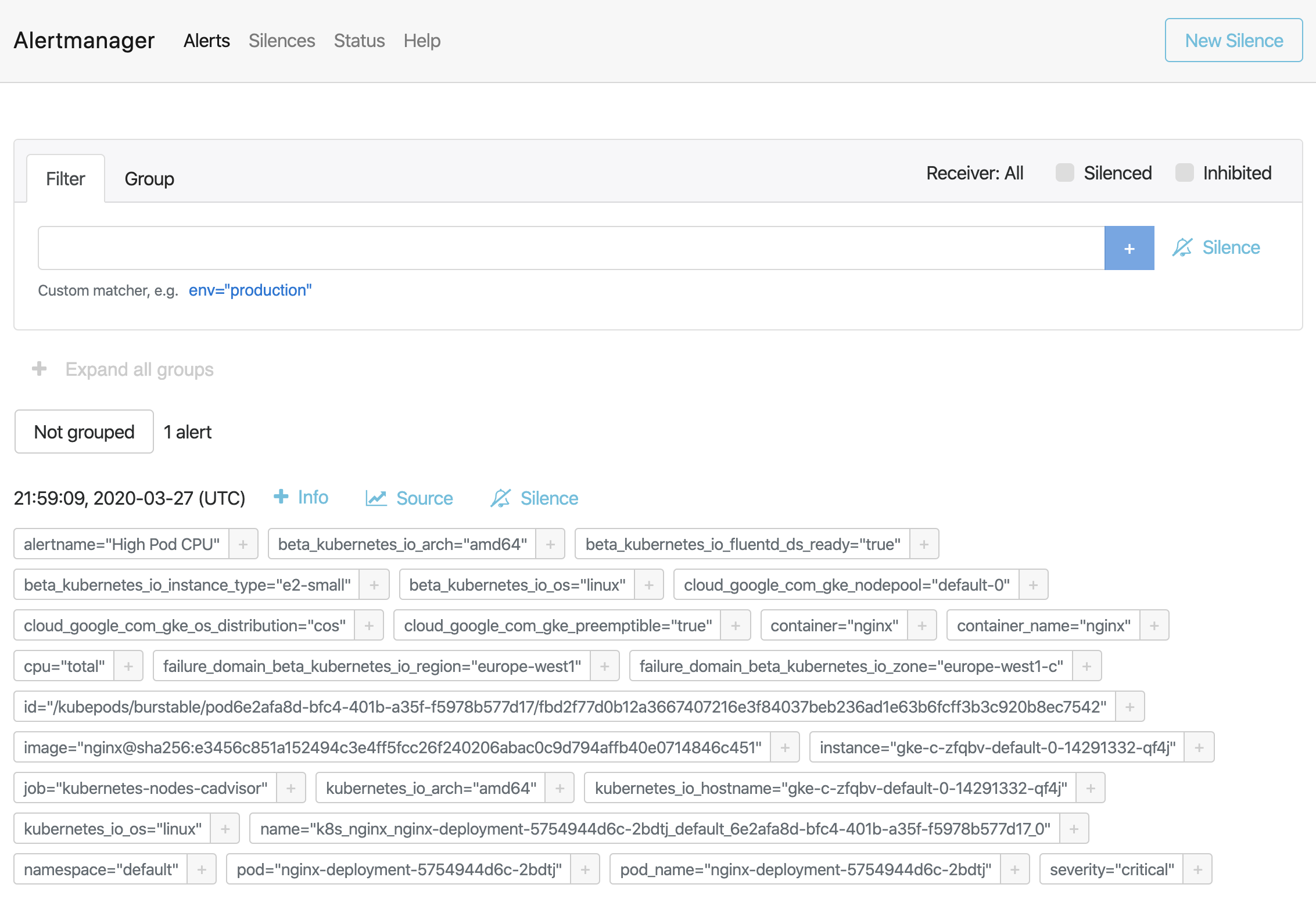
將Alertmanager配置為在我們收到告警時發送電子郵件。如果我們查看收件箱,則會看到類似的內容:

感謝各位的閱讀,以上就是“Prometheus怎么使用”的內容了,經過本文的學習后,相信大家對Prometheus怎么使用這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





