溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Kubernetes如何通過Device Plugins來使用NVIDIA GPU,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
Device Pulgins在Kubernetes 1.10中是beta特性,開始于Kubernetes 1.8,用來給第三方設備廠商通過插件化的方式將設備資源對接到Kubernetes,給容器提供Extended Resources。
通過Device Plugins方式,用戶不需要改Kubernetes的代碼,由第三方設備廠商開發插件,實現Kubernetes Device Plugins的相關接口即可。
目前關注度比較高的Device Plugins實現有:
Nvidia提供的GPU插件:NVIDIA device plugin for Kubernetes
高性能低延遲RDMA卡插件:RDMA device plugin for Kubernetes
低延遲Solarflare萬兆網卡驅動:Solarflare Device Plugin
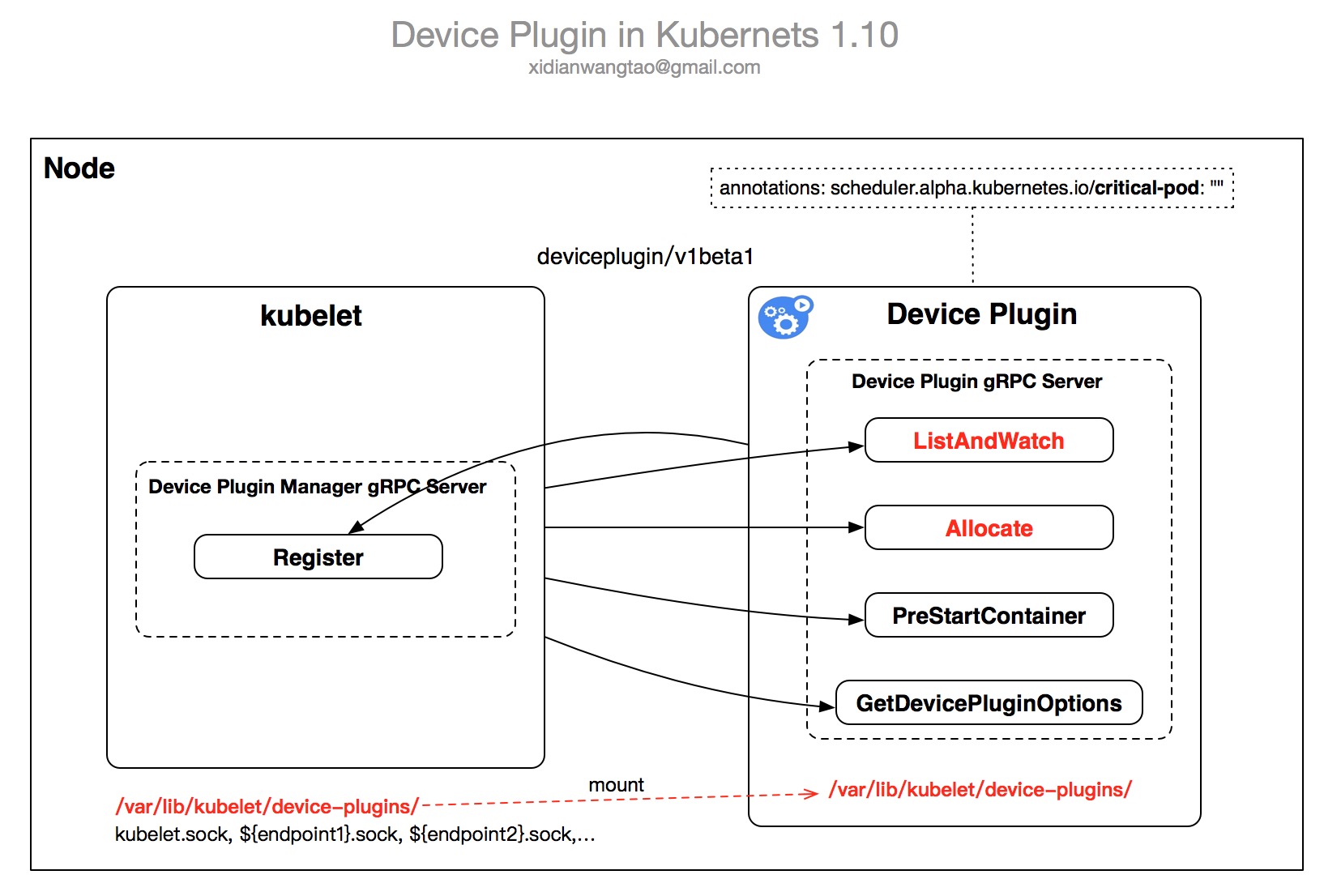
Device plugins啟動時,對外暴露幾個gRPC Service提供服務,并通過/var/lib/kubelet/device-plugins/kubelet.sock向kubelet進行注冊。
在Kubernetes 1.10之前的版本,默認disable DevicePlugins,用戶需要在Feature Gate中enable。
在Kubernetes 1.10,默認enable DevicePlugins,用戶可以在Feature Gate中disable it。
當DevicePlugins Feature Gate enable,kubelet就會暴露一個Register gRPC接口。Device Plugins通過調用Register接口完成Device的注冊。
Register接口描述如下:
pkg/kubelet/apis/deviceplugin/v1beta1/api.pb.go:440
type RegistrationServer interface {
Register(context.Context, *RegisterRequest) (*Empty, error)
}
pkg/kubelet/apis/deviceplugin/v1beta1/api.pb.go:87
type RegisterRequest struct {
// Version of the API the Device Plugin was built against
Version string `protobuf:"bytes,1,opt,name=version,proto3" json:"version,omitempty"`
// Name of the unix socket the device plugin is listening on
// PATH = path.Join(DevicePluginPath, endpoint)
Endpoint string `protobuf:"bytes,2,opt,name=endpoint,proto3" json:"endpoint,omitempty"`
// Schedulable resource name. As of now it's expected to be a DNS Label
ResourceName string `protobuf:"bytes,3,opt,name=resource_name,json=resourceName,proto3" json:"resource_name,omitempty"`
// Options to be communicated with Device Manager
Options *DevicePluginOptions `protobuf:"bytes,4,opt,name=options" json:"options,omitempty"`
}RegisterRequest要求的參數如下:
對于nvidia gpu,只有一個PreStartRequired選項,表示每個Container啟動前是否要調用Device Plugin的PreStartContainer接口(是Kubernetes 1.10中Device Plugin Interface接口之一),默認為false。
vendor/k8s.io/kubernetes/pkg/kubelet/apis/deviceplugin/v1beta1/api.pb.go:71
func (m *NvidiaDevicePlugin) GetDevicePluginOptions(context.Context, *pluginapi.Empty) (*pluginapi.DevicePluginOptions, error) {
return &pluginapi.DevicePluginOptions{}, nil
}
github.com/NVIDIA/k8s-device-plugin/server.go:80
type DevicePluginOptions struct {
// Indicates if PreStartContainer call is required before each container start
PreStartRequired bool `protobuf:"varint,1,opt,name=pre_start_required,json=preStartRequired,proto3" json:"pre_start_required,omitempty"`
}Version, 目前有v1alpha,v1beta1兩個版本。
Endpoint, 表示device plugin暴露的socket名稱,Register時會根據Endpoint生成plugin的socket放在/var/lib/kubelet/device-plugins/目錄下,比如Nvidia GPU Device Plugin對應/var/lib/kubelet/device-plugins/nvidia.sock。
ResourceName, 須按照Extended Resource Naming Scheme格式vendor-domain/resource,比如nvidia.com/gpu
DevicePluginOptions, 作為kubelet與device plugin通信時的額外參數傳遞。
前面提到Device Plugin Interface目前有v1alpha, v1beta1兩個版本,每個版本對應的接口如下:
/v1beta1.Registration/Register
/v1beta1.Registration/Register
pkg/kubelet/apis/deviceplugin/v1beta1/api.pb.go:466
var _Registration_serviceDesc = grpc.ServiceDesc{
ServiceName: "v1beta1.Registration",
HandlerType: (*RegistrationServer)(nil),
Methods: []grpc.MethodDesc{
{
MethodName: "Register",
Handler: _Registration_Register_Handler,
},
},
Streams: []grpc.StreamDesc{},
Metadata: "api.proto",
}/v1beta1.DevicePlugin/ListAndWatch
/v1beta1.DevicePlugin/Allocate
/v1beta1.DevicePlugin/PreStartContainer
/v1beta1.DevicePlugin/GetDevicePluginOptions
pkg/kubelet/apis/deviceplugin/v1beta1/api.pb.go:665
var _DevicePlugin_serviceDesc = grpc.ServiceDesc{
ServiceName: "v1beta1.DevicePlugin",
HandlerType: (*DevicePluginServer)(nil),
Methods: []grpc.MethodDesc{
{
MethodName: "GetDevicePluginOptions",
Handler: _DevicePlugin_GetDevicePluginOptions_Handler,
},
{
MethodName: "Allocate",
Handler: _DevicePlugin_Allocate_Handler,
},
{
MethodName: "PreStartContainer",
Handler: _DevicePlugin_PreStartContainer_Handler,
},
},
Streams: []grpc.StreamDesc{
{
StreamName: "ListAndWatch",
Handler: _DevicePlugin_ListAndWatch_Handler,
ServerStreams: true,
},
},
Metadata: "api.proto",
}/deviceplugin.Registration/Register
pkg/kubelet/apis/deviceplugin/v1alpha/api.pb.go:374
var _Registration_serviceDesc = grpc.ServiceDesc{
ServiceName: "deviceplugin.Registration",
HandlerType: (*RegistrationServer)(nil),
Methods: []grpc.MethodDesc{
{
MethodName: "Register",
Handler: _Registration_Register_Handler,
},
},
Streams: []grpc.StreamDesc{},
Metadata: "api.proto",
}/deviceplugin.DevicePlugin/Allocate
/deviceplugin.DevicePlugin/ListAndWatch
pkg/kubelet/apis/deviceplugin/v1alpha/api.pb.go:505
var _DevicePlugin_serviceDesc = grpc.ServiceDesc{
ServiceName: "deviceplugin.DevicePlugin",
HandlerType: (*DevicePluginServer)(nil),
Methods: []grpc.MethodDesc{
{
MethodName: "Allocate",
Handler: _DevicePlugin_Allocate_Handler,
},
},
Streams: []grpc.StreamDesc{
{
StreamName: "ListAndWatch",
Handler: _DevicePlugin_ListAndWatch_Handler,
ServerStreams: true,
},
},
Metadata: "api.proto",
}v1alpha:
v1beta1:
當Device Plugin成功注冊后,它將通過ListAndWatch向kubelet發送它管理的device列表,kubelet收到數據后通過API Server更新etcd中對應node的status中。
然后用戶就能在Container Spec request中請求對應的device,注意以下限制:
Extended Resource只支持請求整數個device,不支持小數點。
不支持超配,即Resource QoS只能是Guaranteed。
同一塊Device不能多個Containers共享。
Device Plugins的工作流如下:
初始化:Device Plugin啟動后,進行一些插件特定的初始化工作以確定對應的Devices處于Ready狀態,對于Nvidia GPU,就是加載NVML Library。
啟動gRPC服務:通過/var/lib/kubelet/device-plugins/${Endpoint}.sock對外暴露gRPC服務,不同的API Version對應不同的服務接口,前面已經提過,下面是每個接口的描述。
ListAndWatch
Allocate
GetDevicePluginOptions
PreStartContainer
pkg/kubelet/apis/deviceplugin/v1beta1/api.proto
// DevicePlugin is the service advertised by Device Plugins
service DevicePlugin {
// GetDevicePluginOptions returns options to be communicated with Device
// Manager
rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state change or a Device disapears, ListAndWatch
// returns the new list
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// Allocate is called during container creation so that the Device
// Plugin can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
// PreStartContainer is called, if indicated by Device Plugin during registeration phase,
// before each container start. Device plugin can run device specific operations
// such as reseting the device before making devices available to the container
rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {}
}ListAndWatch
Allocate
pkg/kubelet/apis/deviceplugin/v1alpha/api.proto
// DevicePlugin is the service advertised by Device Plugins
service DevicePlugin {
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state changes or a Device disappears, ListAndWatch
// returns the new list
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// Allocate is called during container creation so that the Device
// Plugin can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
}v1alpha:
v1beta1:
Device Plugin通過/var/lib/kubelet/device-plugins/kubelet.sock向kubelet進行注冊。
注冊成功后,Device Plugin就正式進入了Serving模式,提供前面提到的gRPC接口調用服務,下面是v1beta1的每個接口對應的具體分析:
下面是struct Device的GPU Sample:
struct Device {
ID: "GPU-fef8089b-4820-abfc-e83e-94318197576e",
State: "Healthy",
}
PreStartContainer is expected to be called before each container start if indicated by plugin during registration phase.
PreStartContainer allows kubelet to pass reinitialized devices to containers.
PreStartContainer allows Device Plugin to run device specific operations on the Devices requested.
type PreStartContainerRequest struct {
DevicesIDs []string `protobuf:"bytes,1,rep,name=devicesIDs" json:"devicesIDs,omitempty"`
}
// PreStartContainerResponse will be send by plugin in response to PreStartContainerRequest
type PreStartContainerResponse struct {
}Allocate is expected to be called during pod creation since allocation failures for any container would result in pod startup failure.
Allocate allows kubelet to exposes additional artifacts in a pod's environment as directed by the plugin.
Allocate allows Device Plugin to run device specific operations on the Devices requested
type AllocateRequest struct {
ContainerRequests []*ContainerAllocateRequest `protobuf:"bytes,1,rep,name=container_requests,json=containerRequests" json:"container_requests,omitempty"`
}
type ContainerAllocateRequest struct {
DevicesIDs []string `protobuf:"bytes,1,rep,name=devicesIDs" json:"devicesIDs,omitempty"`
}
// AllocateResponse includes the artifacts that needs to be injected into
// a container for accessing 'deviceIDs' that were mentioned as part of
// 'AllocateRequest'.
// Failure Handling:
// if Kubelet sends an allocation request for dev1 and dev2.
// Allocation on dev1 succeeds but allocation on dev2 fails.
// The Device plugin should send a ListAndWatch update and fail the
// Allocation request
type AllocateResponse struct {
ContainerResponses []*ContainerAllocateResponse `protobuf:"bytes,1,rep,name=container_responses,json=containerResponses" json:"container_responses,omitempty"`
}
type ContainerAllocateResponse struct {
// List of environment variable to be set in the container to access one of more devices.
Envs map[string]string `protobuf:"bytes,1,rep,name=envs" json:"envs,omitempty" protobuf_key:"bytes,1,opt,name=key,proto3" protobuf_val:"bytes,2,opt,name=value,proto3"`
// Mounts for the container.
Mounts []*Mount `protobuf:"bytes,2,rep,name=mounts" json:"mounts,omitempty"`
// Devices for the container.
Devices []*DeviceSpec `protobuf:"bytes,3,rep,name=devices" json:"devices,omitempty"`
// Container annotations to pass to the container runtime
Annotations map[string]string `protobuf:"bytes,4,rep,name=annotations" json:"annotations,omitempty" protobuf_key:"bytes,1,opt,name=key,proto3" protobuf_val:"bytes,2,opt,name=value,proto3"`
}
// DeviceSpec specifies a host device to mount into a container.
type DeviceSpec struct {
// Path of the device within the container.
ContainerPath string `protobuf:"bytes,1,opt,name=container_path,json=containerPath,proto3" json:"container_path,omitempty"`
// Path of the device on the host.
HostPath string `protobuf:"bytes,2,opt,name=host_path,json=hostPath,proto3" json:"host_path,omitempty"`
// Cgroups permissions of the device, candidates are one or more of
// * r - allows container to read from the specified device.
// * w - allows container to write to the specified device.
// * m - allows container to create device files that do not yet exist.
Permissions string `protobuf:"bytes,3,opt,name=permissions,proto3" json:"permissions,omitempty"`
}AllocateRequest就是DeviceID列表。
AllocateResponse包括需要注入到Container里面的Envs、Devices的掛載信息(包括device的cgroup permissions)以及自定義的Annotations。
Allocate:Device Plugin執行device-specific操作,返回AllocateResponse給kubelet,kubelet再傳給dockerd,由dockerd(調用nvidia-docker)在創建容器時分配device時使用。下面是這個接口的Request和Response的描述。
PreStartContainer:
GetDevicePluginOptions: 目前只有PreStartRequired這一個field。
type DevicePluginOptions struct {
// Indicates if PreStartContainer call is required before each container start
PreStartRequired bool `protobuf:"varint,1,opt,name=pre_start_required,json=preStartRequired,proto3" json:"pre_start_required,omitempty"`
}ListAndWatch:監控對應Devices的狀態變更或者Disappear事件,返回ListAndWatchResponse給kubelet, ListAndWatchResponse就是Device列表。
type ListAndWatchResponse struct {
Devices []*Device `protobuf:"bytes,1,rep,name=devices" json:"devices,omitempty"`
}
type Device struct {
// A unique ID assigned by the device plugin used
// to identify devices during the communication
// Max length of this field is 63 characters
ID string `protobuf:"bytes,1,opt,name=ID,json=iD,proto3" json:"ID,omitempty"`
// Health of the device, can be healthy or unhealthy, see constants.go
Health string `protobuf:"bytes,2,opt,name=health,proto3" json:"health,omitempty"`
}每次kubelet啟動(重啟)時,都會將/var/lib/kubelet/device-plugins下的所有sockets文件刪除。
Device Plugin要負責監測自己的socket被刪除,然后進行重新注冊,重新生成自己的socket。
當plugin socket被誤刪,Device Plugin該怎么辦?
我們看看Nvidia Device Plugin是怎么處理的,相關的代碼如下:
github.com/NVIDIA/k8s-device-plugin/main.go:15
func main() {
...
log.Println("Starting FS watcher.")
watcher, err := newFSWatcher(pluginapi.DevicePluginPath)
...
restart := true
var devicePlugin *NvidiaDevicePlugin
L:
for {
if restart {
if devicePlugin != nil {
devicePlugin.Stop()
}
devicePlugin = NewNvidiaDevicePlugin()
if err := devicePlugin.Serve(); err != nil {
log.Println("Could not contact Kubelet, retrying. Did you enable the device plugin feature gate?")
log.Printf("You can check the prerequisites at: https://github.com/NVIDIA/k8s-device-plugin#prerequisites")
log.Printf("You can learn how to set the runtime at: https://github.com/NVIDIA/k8s-device-plugin#quick-start")
} else {
restart = false
}
}
select {
case event := <-watcher.Events:
if event.Name == pluginapi.KubeletSocket && event.Op&fsnotify.Create == fsnotify.Create {
log.Printf("inotify: %s created, restarting.", pluginapi.KubeletSocket)
restart = true
}
case err := <-watcher.Errors:
log.Printf("inotify: %s", err)
case s := <-sigs:
switch s {
case syscall.SIGHUP:
log.Println("Received SIGHUP, restarting.")
restart = true
default:
log.Printf("Received signal \"%v\", shutting down.", s)
devicePlugin.Stop()
break L
}
}
}
} 通過fsnotify.Watcher監控/var/lib/kubelet/device-plugins/目錄。
如果fsnotify.Watcher的Events Channel收到Create kubelet.sock事件(說明kubelet發生重啟),則會觸發Nvidia Device Plugin的重啟。
Nvidia Device Plugin重啟的邏輯是:先檢查devicePlugin對象是否為空(說明完成了Nvidia Device Plugin的初始化):
如果不為空,則先停止Nvidia Device Plugin的gRPC Server。
然后調用NewNvidiaDevicePlugin()重建一個新的DevicePlugin實例。
調用Serve()啟動gRPC Server,并先kubelet注冊自己。
因此,這其中只監控了kubelet.sock的Create事件,能很好處理kubelet重啟的問題,但是并沒有監控自己的socket是否被刪除的事件。所以,如果Nvidia Device Plugin的socket被誤刪了,那么將會導致kubelet無法與該節點的Nvidia Device Plugin進行socket通信,則意味著Device Plugin的gRPC接口都無法調通:
無法ListAndWatch該節點上的Device列表、健康狀態,Devices信息無法同步。
無法Allocate Device,導致容器創建失敗。
因此,建議加上對自己device plugin socket的刪除事件的監控,一旦監控到刪除,則應該觸發restart。
select {
case event := <-watcher.Events:
if event.Name == pluginapi.KubeletSocket && event.Op&fsnotify.Create == fsnotify.Create {
log.Printf("inotify: %s created, restarting.", pluginapi.KubeletSocket)
restart = true
}
// 增加對nvidia.sock的刪除事件監控
if event.Name == serverSocket && event.Op&fsnotify.Delete == fsnotify.Delete {
log.Printf("inotify: %s deleted, restarting.", serverSocket)
restart = true
}
...
}Device Plugin是通過Extended Resources來expose宿主機上的資源的,Kubernetes內置的Resources都是隸屬于kubernetes.io domain的,因此Extended Resource不允許advertise在kubernetes.io domain下。
Node-level Extended Resource
注意:~1 is the encoding for the character / in the patch path。
給API Server提交PATCH請求,給node的status.capacity添加新的資源名稱和數量;
kubelet通過定期更新node status.allocatable到API Server,這其中就包括事先給node打PATCH新加的資源。之后請求了新加資源的Pod就會被scheduler根據node status.allocatable進行FitResources Predicate甩選node。
注意:kubelet通過--node-status-update-frequency配置定期更新間隔,默認10s。因此,當你提交完PATCH后,最壞情況下可能要等待10s左右的時間才能被scheduler發現并使用該資源。
Device plugin管理的資源
其他資源
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/example.com~1foo", "value": "5"}]' \
http://k8s-master:8080/api/v1/nodes/k8s-node-1/statusCluster-level Extended Resources
通常集群級的Extended Resources是給scheduler extender使用的,用來做Resources的配額管理。
當Pod請求的resource中包含該extended resources時,default scheduler才會將這個Pod發給對應的scheduler extender進行二次調度。
ignoredByScheduler field如果設置為true,則default scheduler將不會對該資源進行PodFitsResources預選檢查,通常都會設置為true,因為Cluster-level不是跟node相關的,不適合進行PodFitResources對Node資源進行檢查。
{
"kind": "Policy",
"apiVersion": "v1",
"extenders": [
{
"urlPrefix":"<extender-endpoint>",
"bindVerb": "bind",
"ManagedResources": [
{
"name": "example.com/foo",
"ignoredByScheduler": true
}
]
}
]
}API Server限制了Extender Resources只能為整數,比如2,2000m,2Ki,不能為1.5, 1500m。
Contaienr resources filed中只配置的Extended Resources必須是Guaranteed QoS。即要么只顯示設置了limits(此時requests默認同limits),要么requests和limit顯示配置一樣。
https://kubernetes.io/docs/tasks/manage-gpus/scheduling-gpus/
這里我們只討論Kubernetes 1.10中如何調度使用GPU。
在Kubernetes 1.8之前,官方還是建議enable alpha gate feature: Accelerators,通過請求resource alpha.kubernetes.io/nvidia-gpu來使用gpu,并且要求容器掛載Host上的nvidia lib和driver到容器內。這部分內容,請參考我的博文:如何在Kubernetes集群中利用GPU進行AI訓練。
從Kubernetes 1.8開始,官方推薦使用Device Plugins方式來使用GPU。
需要在Node上pre-install NVIDIA Driver,并建議通過Daemonset部署NVIDIA Device Plugin,完成后Kubernetes才能發現nvidia.com/gpu。
因為device plugin通過extended resources來expose gpu resource的,所以在container請求gpu資源的時候要注意resource QoS為Guaranteed。
Containers目前仍然不支持共享同一塊gpu卡。每個Container可以請求多塊gpu卡,但是不支持gpu fraction。
使用官方nvidia driver除了以上注意事項之外,還需注意:
Node上需要pre-install nvidia docker 2.0,并使用nvidia docker替換runC作為docker的默認runtime。
在CentOS上,參考如下方式安裝nvidia docker 2.0 :
# Add the package repositories distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | \ sudo tee /etc/yum.repos.d/nvidia-docker.repo # Install nvidia-docker2 and reload the Docker daemon configuration sudo yum install -y nvidia-docker2 sudo pkill -SIGHUP dockerd # Test nvidia-smi with the latest official CUDA image docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi
以上工作都完成后,Container就可以像請求buit-in resources一樣請求gpu資源了:
apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add # https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile image: "k8s.gcr.io/cuda-vector-add:v0.1" resources: limits: nvidia.com/gpu: 2 # requesting 2 GPU
如果你的集群中存在不同型號的GPU服務器,比如nvidia tesla k80, p100, v100等,而且不同的訓練任務需要匹配不同的GPU型號,那么先給Node打上對應的Label:
# Label your nodes with the accelerator type they have. kubectl label nodes <node-with-k80> accelerator=nvidia-tesla-k80 kubectl label nodes <node-with-p100> accelerator=nvidia-tesla-p100
Pod中通過NodeSelector來指定對應的GPU型號:
apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add # https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile image: "k8s.gcr.io/cuda-vector-add:v0.1" resources: limits: nvidia.com/gpu: 1 nodeSelector: accelerator: nvidia-tesla-p100 # or nvidia-tesla-k80 etc.
思考:其實僅僅使用NodeSelector是不能很好解決這個問題的,這要求所有的pod都要加上對應的NodeSelector。對于V100這樣的昂貴稀有的GPU卡,通常還要求不能讓別的訓練任務使用,只給某些算法訓練使用,這個時候我們可以通過給Node打上對應的Taint,給需要的Pod的打上對應Toleration就能完美滿足需求了。
建議通過Daemonset來部署Device Plugin,方便實現failover。
Device Plugin Pod必須具有privileged特權才能訪問/var/lib/kubelet/device-plugins
Device Plugin Pod需將宿主機的hostpath /var/lib/kubelet/device-plugins掛載到容器內相同的目錄。
apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: nvidia-device-plugin-daemonset spec: template: metadata: labels: name: nvidia-device-plugin-ds spec: containers: - image: nvidia/k8s-device-plugin:1.8 name: nvidia-device-plugin-ctr securityContext: privileged: true volumeMounts: - name: device-plugin mountPath: /var/lib/kubelet/device-plugins volumes: - name: device-plugin hostPath: path: /var/lib/kubelet/device-plugins
apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: nvidia-device-plugin-daemonset namespace: kube-system spec: template: metadata: # Mark this pod as a critical add-on; when enabled, the critical add-on scheduler # reserves resources for critical add-on pods so that they can be rescheduled after # a failure. This annotation works in tandem with the toleration below. annotations: scheduler.alpha.kubernetes.io/critical-pod: "" labels: name: nvidia-device-plugin-ds spec: tolerations: # Allow this pod to be rescheduled while the node is in "critical add-ons only" mode. # This, along with the annotation above marks this pod as a critical add-on. - key: CriticalAddonsOnly operator: Exists containers: - image: nvidia/k8s-device-plugin:1.10 name: nvidia-device-plugin-ctr securityContext: privileged: true volumeMounts: - name: device-plugin mountPath: /var/lib/kubelet/device-plugins volumes: - name: device-plugin hostPath: path: /var/lib/kubelet/device-plugins
關于Kubernetes對critical pod的處理,越來越有意思了,找個時間單獨寫個博客再詳細聊這個。
上述內容就是Kubernetes如何通過Device Plugins來使用NVIDIA GPU,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





