溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文首發于 vivo互聯網技術 微信公眾號
作者:李勇
目錄:
1.左表 join 后條件下推
2.左表join中條件不下推
3.右表join中條件下推
4.右表join中條件不下推
5.總結
在《SparkSql連接查詢中的謂詞下推處理(一)》中,我們介紹了一些基本的概念,并對內連接查詢時的一些基本下推規則進行了分析。
本篇文章要介紹的是--外連接查詢中的謂詞下推規則,這相比內連接中的規則要復雜一些,不過使用簡單的表格來進行分析也是可以分析清楚的。先上表:

我們以左外連接查詢為例,先總結規矩如下:
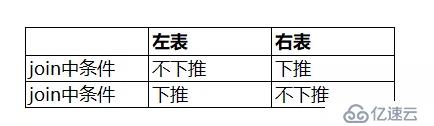
接下來對這個表格中的規則進行詳細的分析。
查詢語句如下:

前文有提到,對于join后條件,如果放在jo**in**操作后執行,是可以作為正確結果進行比對的。那么先對兩表進行左連接,結果如下:
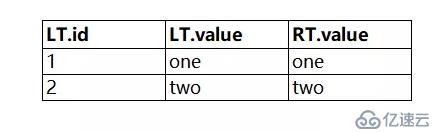
然后使用LT.id>1這個join后條件進行過濾,結果如下:

來分析一下LT.id>1下推到左表進行數據過濾的結果,經過LT.id>1過濾后,左表變為:

此時再和右表進行左連接,左表id為2的行,在右表中能找到id為2的行,則連接結果如下:

可見,兩種處理方法結果一致。條件下推過濾了左表整整50%的數據(相當牛,雖然只過濾了一條)。究其原因,是因為在SparkSQL中,把以上的查詢解析成了如下的子查詢:

這是一個非相關子查詢,即完全可以先完成子查詢,再完成父查詢,子查詢在查詢過程中和外部查詢沒有關聯關系。
查詢語句如下:
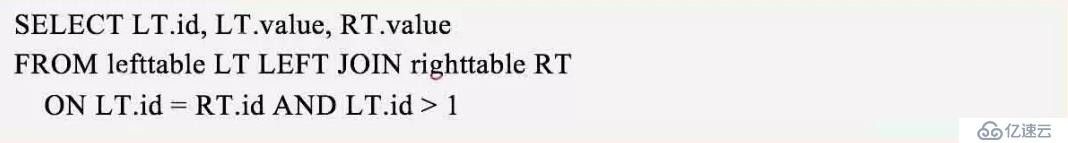
來看看不下推的情況下計算出的正確結果,join過程如下:
第一步:左表id為1的行在右表中能找到相等的id,但是左表的id為1,是不滿足第二個join條件(LT.id>1)的,所以左表這一條相當于沒有和右表join上,所以左表的值value保留,而右表的value為null(你沒滿足join中條件沒join上還把你的值保留,給我搞個空值?沒辦法,就是這么任性)。
第二步:左表id為2的行在右表中能找到,而且左表id為2的行的id大于1,兩個join條件都滿足,所以算是和右表join上了,所以左表和右表的value都保留。最終的查詢結果如下:
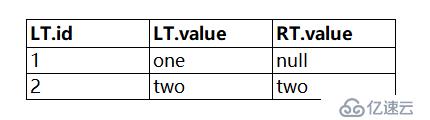
那么如果把"LT.id>1"這個條件下推到做表,會得到什么結果呢?
首先左表經過"LT.id>1"過濾后,如下:

此時再和右表連接,左表id為2的行在右表中能找到,且滿足"LT.id = RT.id AND LT.id > 1"這個join中條件,所以兩表的value都被保留。左表中已經沒有數據了,查詢結束,查詢結果如下:

這個查詢結果和不下推的正確結果不一致,是個錯誤的結果,所以左表join中條件是不能下推進行數據過濾的。分析原因:主要是因為join中條件和join后條件對結果的處理方式不同,前者在不滿足join條件時會保留一部分結果,而后者在不滿足條件時任何東西都不保留。
查詢語句如下:
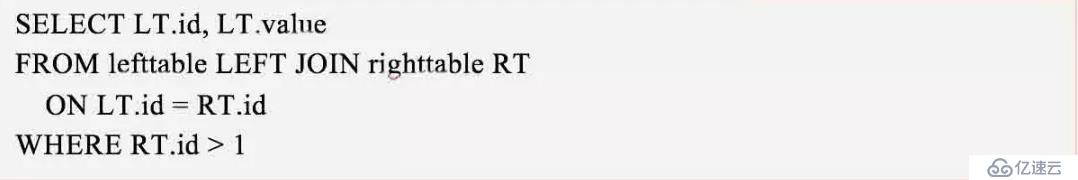
現在把RT.id>1這個右表join后條件下推,來過濾右表,過濾后如下:

然后左表再和右表進行左連接,流程如下:
第一步:左表id為1的行在右表中沒有,此時左表值保留,右表為null;
第二步:左表id位2的行在右表中有,并且RT.id大于1,兩個join條件都滿足,則左表和右表的值都保留。查詢結果如下:
那么如果不下推(為了得到正確結果),來看看結果,流程如下:
第一步:左表id為1的行在右表中有,但是不滿足第二個join條件,所以這行算是沒join上,所以左表數據保留,右表為null;
第二步:左表id為2的行在右表中有,也滿足第二個join條件,所以左右表的數據都保留。
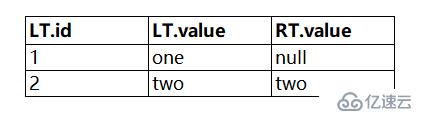
可見,右表join中條件下推不下推,結果一樣,所以,干嗎不下推?可以過濾掉一半的數據呢。SparkSQL中的等價處理語句是:

可以看出,也是解析成了一個非相關子查詢來處理的。
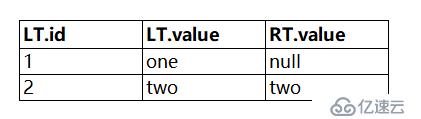
這個應該是最違反常規理解的查詢了,查詢語句如下:
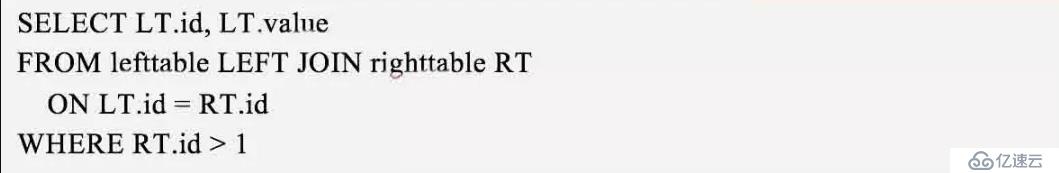
首先來看,join后條件不下推的情況,流程如下:
第一步:左表id為1的行在右表中可以找到,但是此時僅僅滿足join條件,在使用where條件判斷這條連接后數據時,發現右表的id不滿足RT.id>1的條件,所以這條join結果不保留(注意:這里是不保留,全都不保留,左表右表都不保留,要跟上邊的沒join上而右表的值保留為null的情況區別開,這也是關鍵所在);
第二步:左表id為2的行和右表id為2的行join上了,同時也滿足RT.id>1的where條件。

這是一條符合語義的正確的查詢結果。
好了,接下來看看右表join后條件下推的情況:
第一步:使用RT.id>1過濾右表,過濾后右表只剩一行id為2的行;
第二步:左表id為1的行在過濾后的右表中沒有,此時左表值保留,右表值為null;
第三步:左表id為2的行在右表中有,此時左表值保留,右表值也保留。
結果如下:
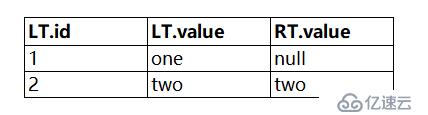
很明顯這其實是一個錯誤的結果。
至此,左連接查詢的四條規則分析完了。可以看出,在SparkSQL中對于外連接查詢時的過濾條件,并不能在所有情況下都用來進行數據源的過濾,如果使用得當會極大的提升查詢性能,如果使用不當,則會產生錯誤的查詢結果,而這種錯誤結果又不易發覺,所以使用時要格外小心。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





