溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Spark如何編譯的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
1.編譯環境
CentOS6.6 JDK1.7.0_80 Maven3.2.5
2.下載Spark源代碼并解壓
[yyl@vmnode ~]$ pwd /home/yyl [yyl@vmnode make]$ pwd /home/yyl/make [yyl@vmnode make]$ wget http://mirrors.cnnic.cn/apache/spark/spark-1.5.0/spark-1.5.0.tgz [yyl@vmnode make]$ tar -zxf spark-1.5.0.tgz
3.編譯
解壓后的源碼包的根目錄下有個 pom.xml 文件,這個文件就是使用 Maven 編譯 Spark 的腳步文件。
OK,現在開始編譯:
[yyl@vmnode spark-1.5.0]$ pwd /home/yyl/make/spark-1.5.0 [yyl@vmnode spark-1.5.0]$ export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m" [yyl@vmnode spark-1.5.0]$ mvn -Pyarn -Phadoop-2.4 -Dhadoop.version=2.4.0 -DskipTests clean package
編譯過程中報錯:
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-enforcer-plugin:1.4:enforce (enforce-versions) on project spark-parent_2.10: Some Enforcer rules have failed. Look above for specific messages explaining why the rule failed. -> [Help 1] [ERROR] [ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch. [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
這個錯誤有兩個解決辦法:一是編譯時加入 -Denforcer.skip=true 參數;二是修改 pom.xml 文件中 properties 定義的變量的值為實際環境中 maven 、java 的版本
[yyl@vmnode spark-1.5.0]$ vim pom.xml <java.version>1.7</java.version> <maven.version>3.2.5</maven.version>
解決上面的錯誤后重新編譯,結果又報錯:
[INFO] ------------------------------------------------------------------------ [INFO] Reactor Summary: [INFO] [INFO] Spark Project Parent POM ........................... SUCCESS [ 4.619 s] [INFO] Spark Project Launcher ............................. SUCCESS [ 11.669 s] [INFO] Spark Project Networking ........................... SUCCESS [ 11.537 s] [INFO] Spark Project Shuffle Streaming Service ............ SUCCESS [ 6.245 s] [INFO] Spark Project Unsafe ............................... SUCCESS [ 17.217 s] [INFO] Spark Project Core ................................. SUCCESS [04:15 min] [INFO] Spark Project Bagel ................................ SUCCESS [ 22.739 s] [INFO] Spark Project GraphX ............................... SUCCESS [01:09 min] [INFO] Spark Project Streaming ............................ SUCCESS [02:04 min] [INFO] Spark Project Catalyst ............................. SUCCESS [02:43 min] [INFO] Spark Project SQL .................................. SKIPPED ...... --------------------------------------------------- java.lang.reflect.InvocationTargetException at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced(Launcher.java:289) at org.codehaus.plexus.classworlds.launcher.Launcher.launch(Launcher.java:229) at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode(Launcher.java:415) at org.codehaus.plexus.classworlds.launcher.Launcher.main(Launcher.java:356) Caused by: scala.reflect.internal.Types$TypeError: bad symbolic reference. A signature in WebUI.class refers to term servlet in value org.jetty which is not available. It may be completely missing from the current classpath, or the version on the classpath might be incompatible with the version used when compiling WebUI.class. at scala.reflect.internal.pickling.UnPickler$Scan.toTypeError(UnPickler.scala:847) at scala.reflect.internal.pickling.UnPickler$Scan$LazyTypeRef.complete(UnPickler.scala:854) at scala.reflect.internal.pickling.UnPickler$Scan$LazyTypeRef.load(UnPickler.scala:863) at scala.reflect.internal.Symbols$Symbol.typeParams(Symbols.scala:1489) ......
這是什么原因呢,查看Spark1.5官方編譯文檔,有這么一句話:
Building Spark using Maven requires Maven 3.3.3 or newer and Java 7+. The Spark build can supply a suitable Maven binary; see below. 果斷升級 maven 到3.3.3,再次編譯,OK,編譯成功!
如果你想要編譯兼容 Scala2.11.x 的 Spark,則使用如下命令編譯(默認兼容 Scala2.10.x):
[yyl@vmnode spark-1.5.0]$ ./dev/change-scala-version.sh 2.11 [yyl@vmnode spark-1.5.0]$ mvn -Pyarn -Phadoop-2.4 -Dscala-2.11 -DskipTests clean package
編譯支持 Hive 和 JDBC 的 Spark
[yyl@vmnode spark-1.5.0]$ mvn -Pyarn -Phadoop-2.4 -Dhadoop.version=2.4.0 -Phive -Phive-thriftserver -DskipTests clean package
4. 生成部署包
源碼包的根目錄下有個 make-distribution.sh 腳本,這個腳本可以打包Spark的發行包,make-distribution.sh 文件其實就是調用了 Maven 進行編譯,可以通過下面的命令運行:
[yyl@vmnode spark-1.5.0]$ ./make-distribution.sh --tgz -Pyarn -Phadoop-2.4 -Dhadoop.version=2.4.0 -Phive -Phive-thriftserver
make-distribution.sh的語法:./make-distribution.sh [--name] [--tgz] [--mvn <mvn-command>] [--with-tachyon] <maven build options>
--tgz :在根目錄下生成 spark-$VERSION-bin.tgz ,不加此參數時不生成 tgz 文件,只生成 /dist 目錄
--name NAME :和 tgz 結合可以生成 spark-$VERSION-bin-$NAME.tgz 的部署包,不加此參數時 NAME 為 hadoop 的版本號
--with-tachyon :是否支持內存文件系統 Tachyon ,不加此參數時不支持 tachyon
PS:編譯時如何指定 Hadoop 版本
例如,Spark要讀取的是 Hadoop2.5.2 上的文件,使用 maven 該如何編譯呢?答案是:mvn -Pyarn -Phadoop-2.4 -Dhadoop.version=2.5.2 -Phive -Phive-thriftserver -DskipTests clean package
具體請看官網說明:
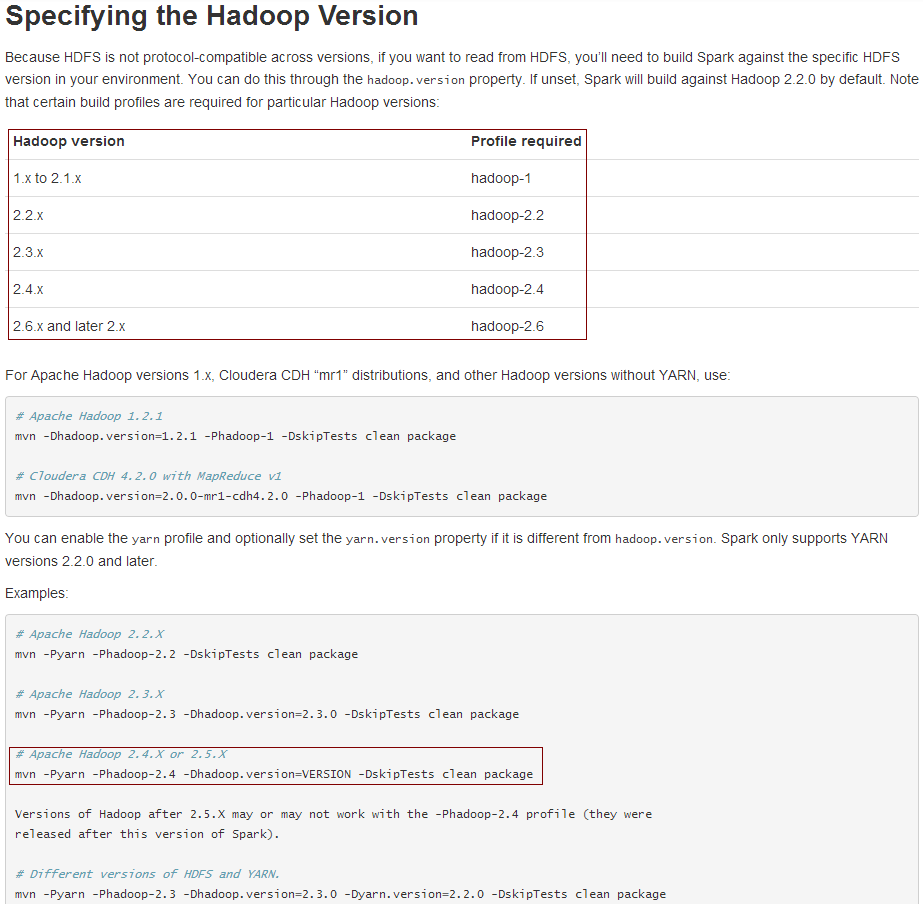
另外,如若遇到官方編譯文件不兼容的新的 Hadoop 版本,只能是自行修改 pom.xml 文件,添加新版本的支持,例如添加:
<profile>
<id>hadoop-2.7</id>
<properties>
<hadoop.version>2.7.1</hadoop.version>
<jets3t.version>0.9.3</jets3t.version>
<zookeeper.version>3.4.6</zookeeper.version>
<curator.version>2.6.0</curator.version>
</properties>
</profile>
感謝各位的閱讀!關于“Spark如何編譯”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





