溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了在solr4.x上使用IK分詞設置useSmart沒有效果的解決方發,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
大家知道由于lucene和solr在最新版本在分詞方面改動比較大,在solr4.x上使用IK分詞,并且設置粗細力度,安裝官方的說法是這樣設置的:
 結果發現建索引和查詢時候的分詞力度是一樣的,默認是安裝細力度分詞,解決方案如下:
結果發現建索引和查詢時候的分詞力度是一樣的,默認是安裝細力度分詞,解決方案如下:
package org.apache.solr.analysis;
import java.io.Reader;
import java.util.Map;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.util.TokenizerFactory;
import org.apache.lucene.util.AttributeSource.AttributeFactory;
import org.wltea.analyzer.lucene.IKTokenizer;
/**
* 解決IK Analyzer 2012FF_hf1 在solr4.x應用時,配置useSmart失效的問題
*
* @author lqin
* @date 2013-12-24
* @email qin.liang@sinovatio.com
* @version 1.0
*
*/
public class IKAnalyzerSolrTokenizerFactory extends TokenizerFactory {
/**
* 構造函數,從參數里面讀取配置
* @param args
*/
public IKAnalyzerSolrTokenizerFactory(Map<String, String> args)
{
super(args);
assureMatchVersion();
// 設置分詞力度,useSmart=true粗力度,useSmart=false細力度
this.setUseSmart("true".equals(args.get("useSmart")));
}
private boolean useSmart;
public boolean useSmart()
{
return useSmart;
}
public void setUseSmart(boolean useSmart)
{
this.useSmart = useSmart;
}
public void init(Map<String, String> args) {
this.useSmart = "true".equals(args.get("useSmart")) ;
}
@Override
public Tokenizer create(AttributeFactory factory, Reader input)
{
Tokenizer _IKTokenizer = new IKTokenizer(input , this.useSmart);
return _IKTokenizer;
}
}
修改配置:
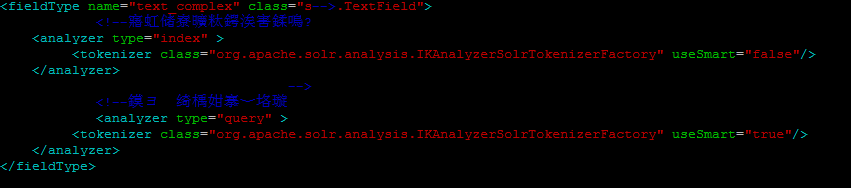
上述內容就是在solr4.x上使用IK分詞設置useSmart沒有效果的解決方發,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





