溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享的是Apache中Druid多進程架構的詳細介紹,相信大部分人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,話不多說,一起往下看吧。
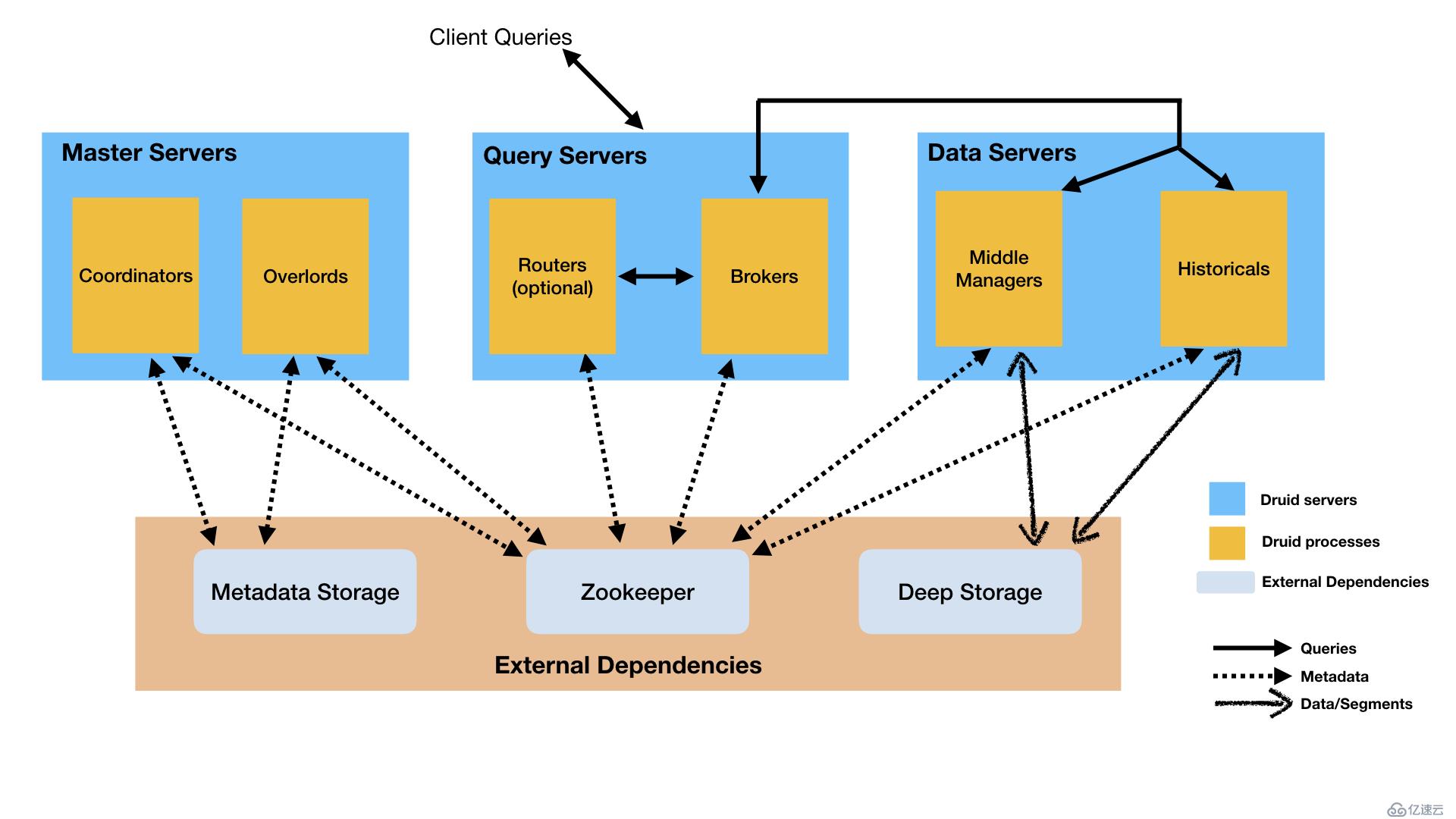
Druid 是多進程架構,每種進程類型都可以獨立配置,獨立擴展。這樣可以為集群提供最大的靈活度。這種設計還提供了強失效容忍:一個失效的組件不會立即影響另外的組件。
下面我們來深入了解 Druid 有哪些進程類型,每種進程又在整個集群中扮演什么角色。
Druid 有多種進程類型,如下:
你可以以任何方式來部署上面的進程。但是為了易于運維,官方建議以下面三種服務類型來組織進程:Master、Query 和 Data。
除了內置的進程類型,Druid 還有三個外部依賴項。
共享文件存儲,只要配置成允許 Druid 訪問即可。在集群部署中,通常使用分布式存儲(如 S3 或 HDFS)或掛載網絡文件系統。在單機部署中,通常使用本地磁盤。Druid 使用 Deep Storage 存儲寫入集群的數據。
Druid 僅將 Deep Storage 用作數據的備份,并作為 Druid進程間在后臺的數據傳輸方式。要響應查詢,Historical 進程并不從 Deep Storage 上讀取數據,在任何查詢之前,先從本地磁盤查詢已經存在的數據。這意味著,Druid 在查詢時并不需要訪問 Deep Storage,這樣就可以得到最優的查詢延遲。這也意味著,在 Deep Storage 和 Historical 進程間你必須有足夠的磁盤空間來存儲你計劃加載的數據。
Deep Storage 是 Druid 彈性、容錯設計的重要組成部分。如果 Druid 單機進程本地數據丟失,可以從 Deep Storage 恢復數據。
元數據存儲,存儲各種共享的系統元數據,如 segment 可用性信息和 task 信息。在集群部署中,通常使用傳統的 RDBMS,如 PostgreSQL 或 MySQL。在單機部署中,通常使用本地存儲,如 Apache Derby 數據庫。
用來進行內部服務發現,協調,和主選舉。
下圖可以看出使用官方建議的 Master/Query/Data 服務部署方式,查詢和寫入數據是如何進行的:
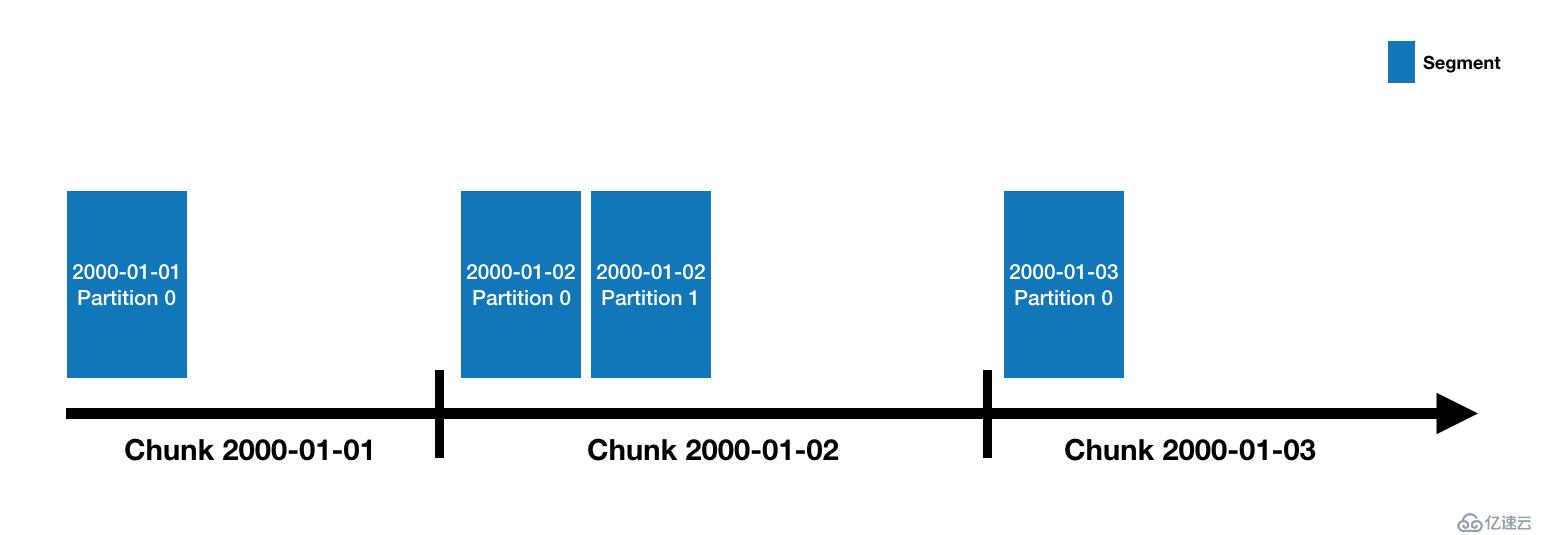
Druid 數據存儲在"datasources"中,它就像 RDBMS 中的 table。每一個 datasources 通過時間分區,或通過其他屬性進行分區。每一個時間范圍稱之為"chunk"(比如,一天一個,如果你的 datasource 使用 day 分區)。在 chunk 中,數據被分區進一個或多個"segments"中。每一個 segment 是一個單獨的文件,通常包含數百萬行數據。一旦 segment 被存儲進 chunks,其組織方式將如以下時間線所示:
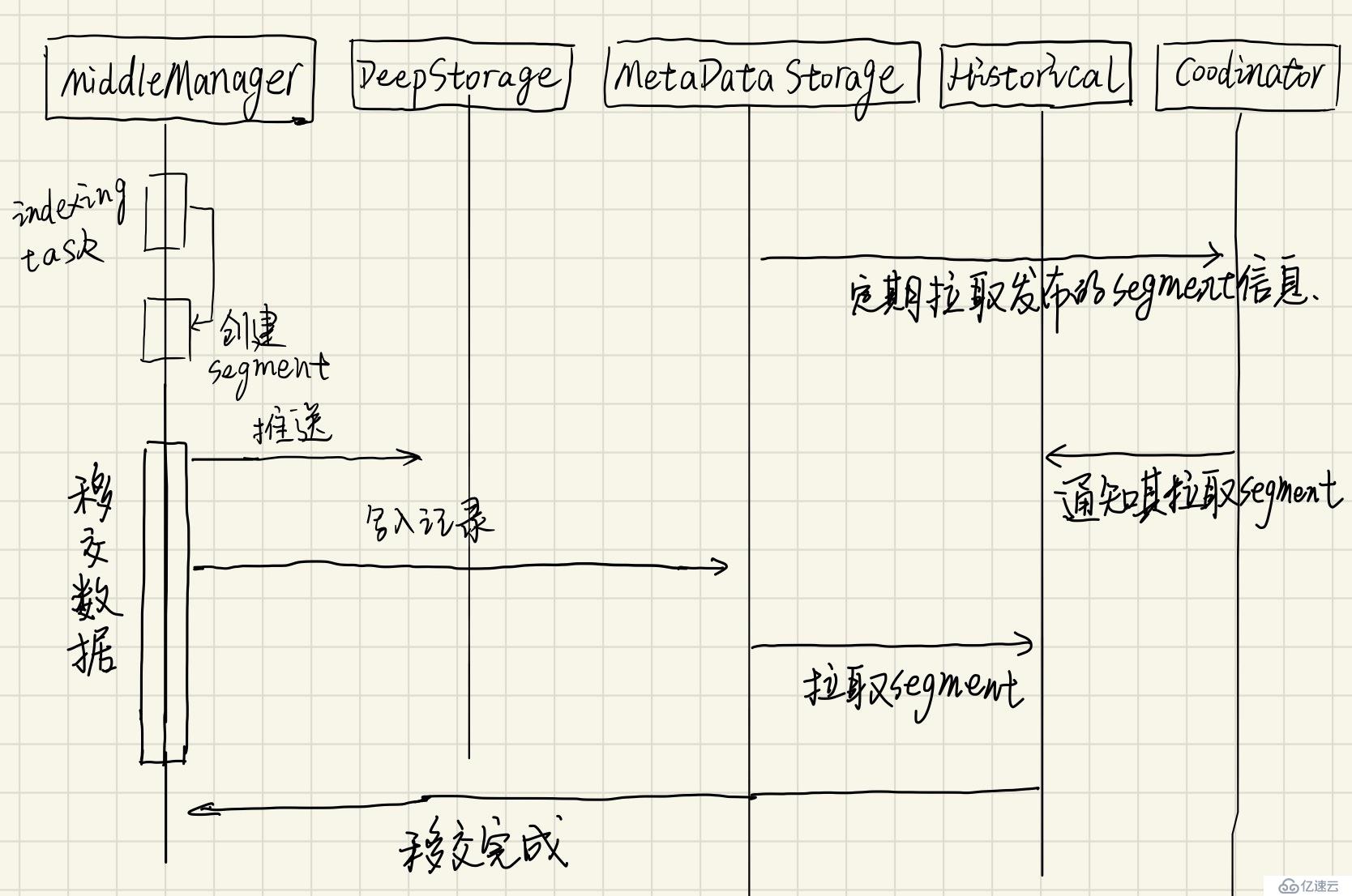
一個 datasource 也許只有一個,也可能有數十萬甚至上百萬個 segment。每個 segment 生命周期開始于 MiddleManager 創建時,剛被創建時,segment 是可變和未提交的。segment 構建過程包含以下幾步,旨在生成結構緊湊并支持快速查詢的數據文件。
segment 定時提交和發布。此時,數據被寫入 Deep Storage,并且再不可變,并從 MiddleManagers 進程遷移至 Historical 進程中。一個關于 segment 的 entry 將寫入 metadata storage。這個 entry 是關于 segment 的元數據的自描述信息,包含如 segment 的數據模式,大小,Deep Storage 地址等信息。這些信息讓 Coordinator 知道集群中哪些數據是可用的。
indexing 是每個 segment 創建的機制。handoff 是數據被發布并開始可以被 Historical 進程處理的機制。這機制在 indexing 側的工作順序如下:
這機制在 Coordinator/Historical 側的工作如下:
數據寫入(indexing)和移交(handoff):
Segment 標識由下面四部分組成:
segmentGranularity指定參數)。例如,這是 datasource 為clarity-cloud0,時間段為2018-05-21T16:00:00.000Z/2018-05-21T17:00:00.000Z,版本號為2018-05-21T15:56:09.909Z,分區號為 1 的標識符:
clarity-cloud0_2018-05-21T16:00:00.000Z_2018-05-21T17:00:00.000Z_2018-05-21T15:56:09.909Z_1分區號為 0(塊中的第一個分區)的 segment 省略了分區號,如以下示例所示,它是與前一個分區在同一時間塊中的 segment,但分區號為 0 而不是 1:
clarity-cloud0_2018-05-21T16:00:00.000Z_2018-05-21T17:00:00.000Z_2018-05-21T15:56:09.909Z你可能想知道上一節中描述的“版本號”是什么。
Druid 支持批處理模式覆寫。在 Driud 中,如果你要做的只是追加數據,那么每個時間塊只有一個版本。但是,當你覆蓋數據時,在幕后發生的事情是使用相同的數據源,相同的時間間隔,但版本號更高的方式創建了一組新的 segment。這向 Druid 系統的其余部分發出信號,表明應從群集中刪除較舊的版本,而應使用新版本替換它。
對于用戶而言,切換似乎是瞬間發生的,因為 Druid 通過先加載新數據(但不允許對其進行查詢)來處理此問題,然后在所有新數據加載完畢后,立即將新查詢切換到新 segment。然后,它在幾分鐘后刪除舊 segment。
每個 segment 的生命周期都涉及以下三個主要領域:
元數據存儲區中。將 segmnet 的記錄插入元數據存儲的操作稱為發布。然后將元數據中的use布爾值設置成可用。由實時任務創建的 segment 將在發布之前可用,因為它們僅在 segment 完成時才發布,并且不接受任何其他數據。你可以使用 Druid SQL sys.segments表檢查當前 segment 的狀態 。它包括以下標志:
is_published:如果 segment 元數據已發布到存儲的元數據中,used則為 true,此值也為 true。is_available:如果該 segment 當前可用于實時任務或Historical查詢,則為 True。is_realtime:如果 segment 在實時任務上可用,則為 true 。對于使用實時寫入的數據源,通常會先設置成true,然后隨著 segment 的發布和移交而變成false。is_overshadowed:如果該 segment 已發布(used設置為 true)并且被其他一些已發布的 segment 完全覆蓋,則為 true。通常,這是一個過渡狀態,處于此狀態的 segment 很快就會將其used標志自動設置為 false。查詢首先進入Broker進程,Broker將得出哪些 segment 具有與該查詢有關的數據(segment 列表始終按時間規劃,也可以根據其他屬性來規劃,這取決于數據源的分區方式),然后,Broker將確定哪些 Historical 和 MiddleManager 正在為這些 segment 提供服務,并將重寫的子查詢發送給每個進程。Historical / MiddleManager 進程將接受查詢,對其進行處理并返回結果。Broker接收結果并將它們合并在一起以得到最終答案,并將其返回給客戶端。
Broker會分析每個請求,優化查詢,盡可能的減少每個查詢必須掃描的數據量。相比于 Broker 過濾器做的優化,每個 segment 內的索引結構允許 Druid 在查看任何數據行之前先找出哪些行(如果有)與過濾器集匹配。一旦 Druid 知道哪些行與特定查詢匹配,它就只會訪問該查詢所需的特定列。在這些列中,Druid 可以在行與行之間跳過,從而避免讀取與查詢過濾器不匹配的數據。
因此,Druid 使用三種不同的技術來優化查詢性能:
檢索每個查詢需訪問的 segment。
在每個 segment 中,使用索引來標識查詢的行。
關于Apache中Druid多進程架構就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果喜歡這篇文章,不如把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





