溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“如何掌握SQL子查詢優化”,在日常操作中,相信很多人在如何掌握SQL子查詢優化問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”如何掌握SQL子查詢優化”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
子查詢是定義在 SQL 標準中一種語法,它可以出現在 SQL 的幾乎任何地方,包括 SELECT, FROM, WHERE 等子句中。
總的來說,子查詢可以分為關聯子查詢(Correlated Subquery)和非關聯子查詢(Non-correlated Subquery)。后者非關聯子查詢是個很簡單的問題,最簡單地,只要先執行它、得到結果集并物化,再執行外層查詢即可。下面是一個例子:
SELECT c_count, count(*) AS custdist FROM ( SELECT c_custkey, count(o_orderkey) AS c_count FROM CUSTOMER LEFT OUTER JOIN ORDERS ON c_custkey = o_custkey AND o_comment NOT LIKE '%pending%deposits%' GROUP BY c_custkey ) c_orders GROUP BY c_count ORDER BY custdist DESC, c_count DESC;
▲ TPCH-13 是一個非關聯子查詢
非關聯子查詢不在本文討論范圍之列,除非特別聲明,以下我們說的子查詢都是指關聯子查詢。
關聯子查詢的特別之處在于,其本身是不完整的:它的閉包中包含一些外層查詢提供的參數。顯然,只有知道這些參數才能運行該查詢,所以我們不能像對待非關聯子查詢那樣。
根據產生的數據來分類,子查詢可以分成以下幾種:
標量(Scalar-valued) 子查詢:輸出一個只有一行一列的結果表,這個標量值就是它的結果。如果結果為空(0 行),則輸出一個 NULL。但是注意,超過 1 行結果是不被允許的,會產生一個運行時異常。
標量子查詢可以出現在任意包含標量的地方,例如 SELECT、WHERE 等子句里。下面是一個例子:
SELECT c_custkey FROM CUSTOMER WHERE 1000000 < ( SELECT SUM(o_totalprice) FROM ORDERS WHERE o_custkey = c_custkey )
▲ Query 1: 一個出現在 WHERE 子句中的標量子查詢,關聯參數用紅色字體標明了
SELECT o_orderkey, ( SELECT c_name FROM CUSTOMER WHERE c_custkey = o_custkey ) AS c_name FROM ORDERS
▲ Query 2: 一個出現在 SELECT 子句中的標量子查詢
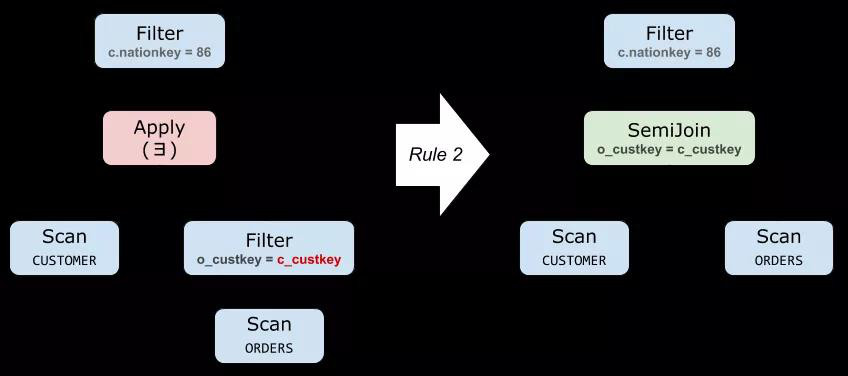
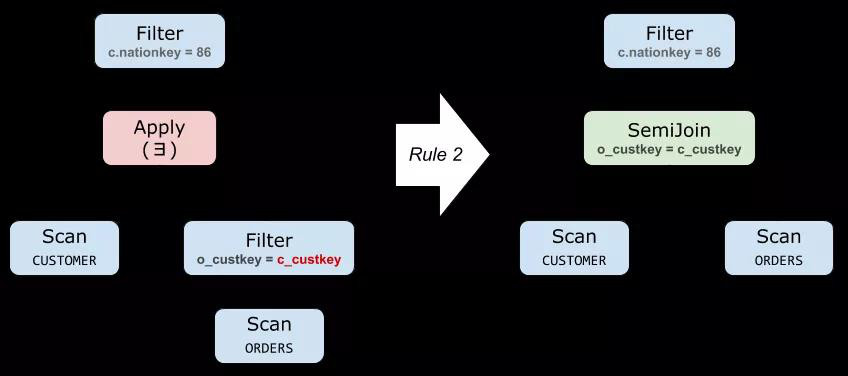
存在性檢測(Existential Test) 子查詢:特指 EXISTS 的子查詢,返回一個布爾值。如果出現在 WHERE 中,這就是我們熟悉的 Semi-Join。當然,它可能出現在任何可以放布爾值的地方。
SELECT c_custkey FROM CUSTOMER WHERE c_nationkey = 86 AND EXISTS( SELECT * FROM ORDERS WHERE o_custkey = c_custkey )
▲ Query 3: 一個 Semi-Join 的例子
集合比較(Quantified Comparision) 子查詢:特指 IN、SOME、ANY 的查詢,返回一個布爾值,常用的形式有:x = SOME(Q) (等價于 x IN Q)或 X <> ALL(Q)(等價于 x NOT IN Q)。同上,它可能出現在任何可以放布爾值的地方。
SELECT c_name FROM CUSTOMER WHERE c_nationkey <> ALL (SELECT s_nationkey FROM SUPPLIER)
▲ Query 4: 一個集合比較的非關聯子查詢
我們以 Query 1 為例,直觀地感受一下,為什么說關聯子查詢的去關聯化是十分必要的。
下面是 Query 1 的未經去關聯化的原始查詢計劃(Relation Tree)。與其他查詢計劃不一樣的是,我們特地畫出了表達式樹(Expression Tree),可以清晰地看到:子查詢是實際上是掛在 Filter 的條件表達式下面的。
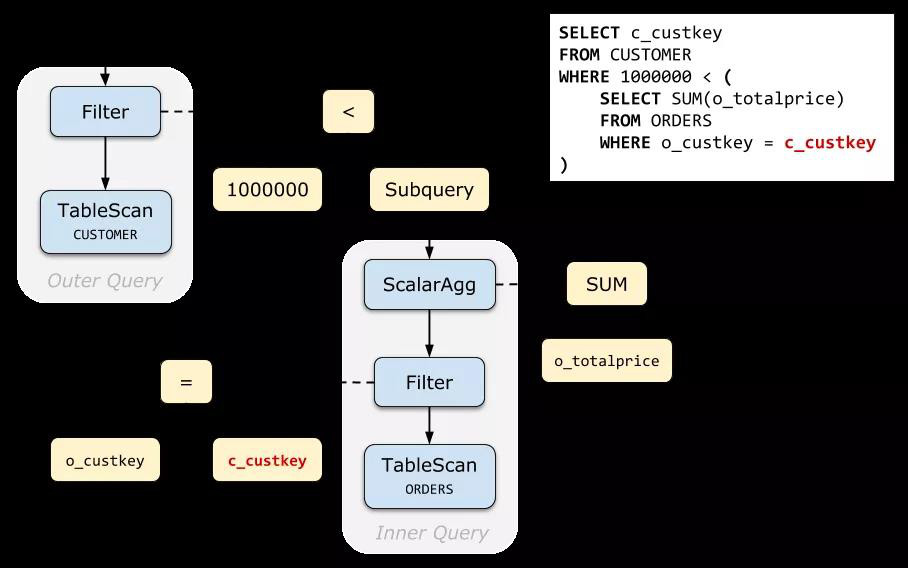
img實際執行時,查詢計劃執行器(Executor)在執行到 Filter 時,調用表達式執行器(Evaluator);由于這個條件表達式中包含一個標量子查詢,所以 Evaluator 又會調用 Executor 計算標量子查詢的結果。
這種 Executor - Evaluator - Executor 的交替調用十分低效!考慮到 Filter 上可能會有上百萬行數據經過,如果為每行數據都執行一次子查詢,那查詢執行的總時長顯然是不可接受的。
上文說到的 Relation - Expression - Relation 這種交替引用不僅執行性能堪憂,而且,對于優化器也是個麻煩的存在——我們的優化規則都是在匹配并且對 Relation 進行變換,而這里的子查詢卻藏在 Expression 里,令人無從下手。
為此,在開始去關聯化之前,我們引入 Apply 算子:
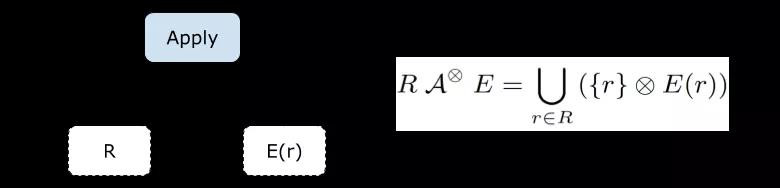
Apply 算子(也稱作 Correlated Join)接收兩個關系樹的輸入,與一般 Join 不同的是,Apply 的 Inner 輸入(圖中是右子樹)是一個帶有參數的關系樹。
Apply 的含義用下圖右半部分的集合表達式定義:對于 Outer Relation RR 中的每一條數據 rr,計算 Inner Relation E(r)E(r),輸出它們連接(Join)起來的結果 r?E(r)r?E(r)。Apply 的結果是所有這些結果的并集(本文中說的并集指的是 Bag 語義下的并集,也就是 UNION ALL)。
“
Apply 是 SQL Server 的命名,它在 HyPer 的文章中叫做 Correlated Join。它們是完全等價的。考慮到 SQL Server 的文章發表更早、影響更廣,本文中都沿用它的命名。
根據連接方式(??)的不同,Apply 又有 4 種形式:
Cross Apply A×A×:這是最基本的形式,行為剛剛我們已經描述過了;
Left Outer Apply ALOJALOJ:即使 E(r)E(r) 為空,也生成一個 r°{NULLs}r°{NULLs}。
Semi Apply A?A?:如果 E(r)E(r) 不為空則返回 rr,否則丟棄;
Anti-Semi Apply A?A?:如果 E(r)E(r) 為空則返回 rr,否則丟棄;
我們用剛剛定義的 Apply 算子來改寫之前的例子:把子查詢從 Expression 內部提取出來。結果如下:
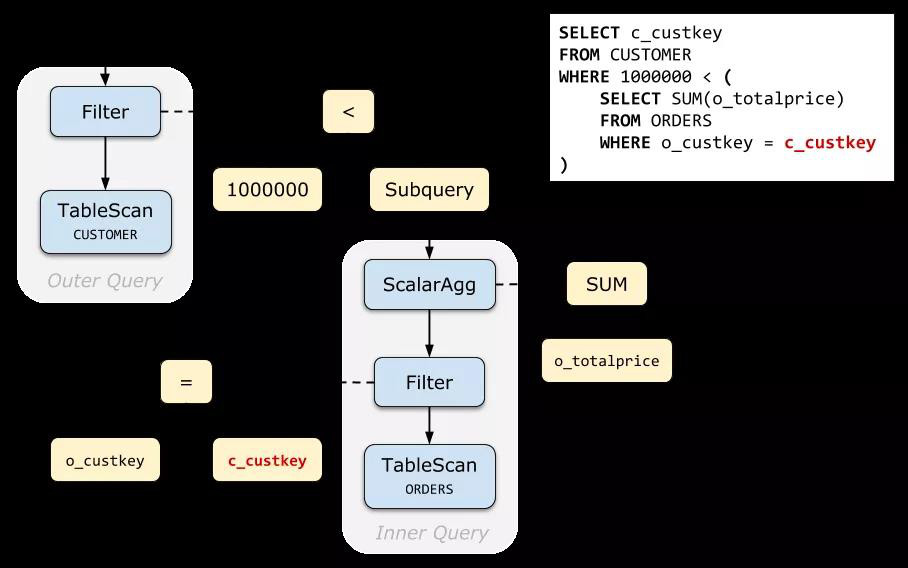
上面的例子中,我們可以肯定 Scalar Agg 子查詢有且只有一行結果,所以可以直接轉成 Apply。但某些情況下,可能無法肯定子查詢一定能返回 0 或 1 行結果(例如,想象一下 Query 2 如果 c_custkey 不是唯一的),為了確保 SQL 語義,還要在 Apply 右邊加一個 Max1RowMax1Row 算子:
Max1Row(E)=?????Null,E,error,if |E|=0if |E|=1otherwiseMax1Row(E)={Null,if |E|=0E,if |E|=1error,otherwise
理論上,我們可以將所有的子查詢轉換成 Apply 算子,一個通用的方法如下:
如果某個算子的表達式中出現了子查詢,我們就把這個子查詢提取到該算子下面(留下一個子查詢的結果變量),構成一個 ALOJALOJ 算子。如果不止一個子查詢,則會產生多個 ALOJALOJ。必要的時候加上 Max1RowMax1Row 算子。
然后應用其他一些規則,將 ALOJALOJ 轉換成 A×A×、A?A?、A?A?。例如上面例子中的子查詢結果 XX 被用作 Filter 的過濾條件,NULL 值會被過濾掉,因此可以安全地轉換成 A×A×。
下面這個例子中,Filter 條件表達式中包含 Q1Q1、Q2Q2 兩個子查詢。轉換之后分別生成了對應的 Apply 算子。其中 Q2Q2 無法確定只會生成恰好一條記錄,所以還加上了 Max1RowMax1Row 算子。
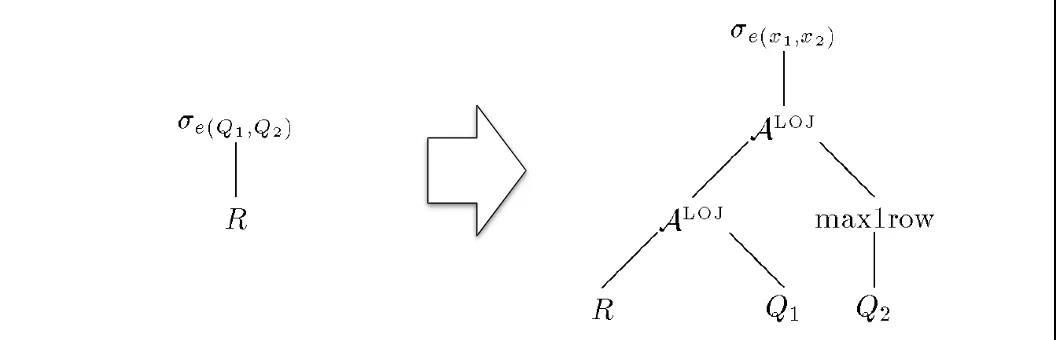
第一組規則是最基本的規則,等式中的 ?? 說明它不限制連接類型,可以是 {×,LOJ,?,?}{×,LOJ,?,?} 中的任意一個。
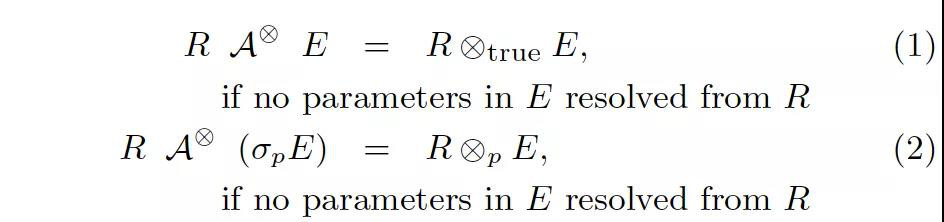
這兩條規則是非常顯而易見的,翻譯成大白話就是:如果 Apply 的右邊不包含來自左邊的參數,那它就和直接 Join 是等價的。
下面是對 Query 3 應用規則 (2) 的例子:
第二組規則描述了如何處理子查詢中的 Project 和 Filter,其思想可以用一句話來描述:盡可能把 Apply 往下推、把 Apply 下面的算子向上提。
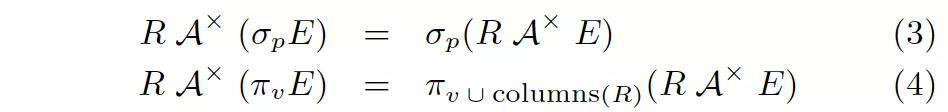
注意這些規則僅處理 Cross Apply 這一種情況。其他 3 種 Apply 的變體,理論上都可以轉換成 Cross Apply,暫時我們只要知道這個事實就可以了。
你可能會問:通常我們都是盡可能把 Filter、Project 往下推,為什么這里會反其道而行呢?關鍵在于:Filter、Project 里面原本包含了帶有關聯變量的表達式,但是把它提到 Apply 上方之后,關聯變量就變成普通變量了!這正是我們想要的。
我們稍后就會看到這樣做的巨大收益:當 Apply 被推最下面時,就可以應用第一組規則,直接把 Apply 變成 Join,也就完成了子查詢去關聯化的優化過程。
下面是對 Query 2 應用規則 (3) 的例子。之后再應用規則 (1),就完成了去關聯化過程。
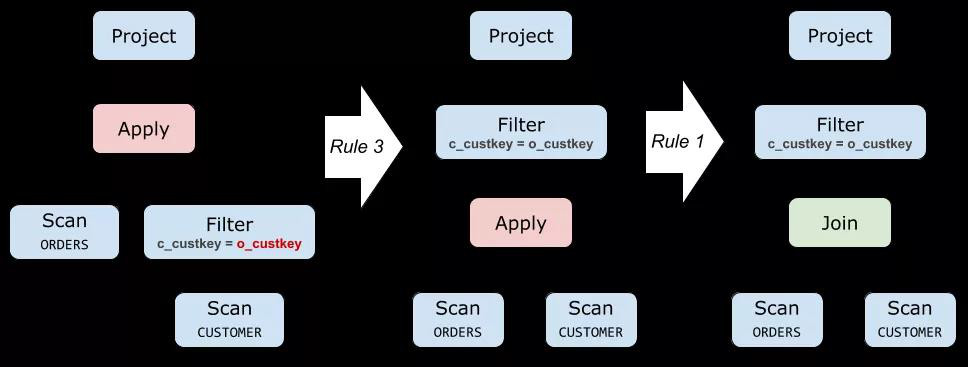
第三組規則描述如何處理子查詢中的 Aggregate(即 Group By)。和上一組一樣,我們的指導思想仍然是:盡可能把 Apply 往下推、把 Apply 下面的算子向上提。
下面等式中,GA,FGA,F 表示帶有 Group By 分組的聚合(Group Agg),其中 AA 表示分組的列,FF 表示聚合函數的列;G1FGF1 表示不帶有分組的聚合(Scalar Agg)。
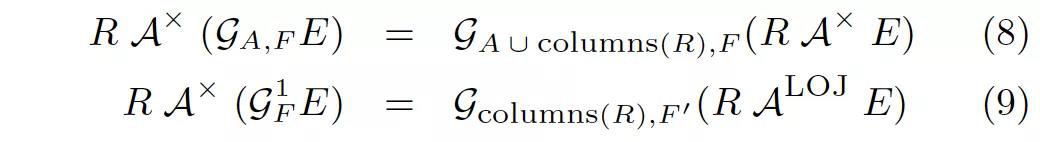
img這一組規則不像之前那么簡單直白,我們先看一個例子找找感覺。下面是對 Query 1 運用規則 (9) 的結果:
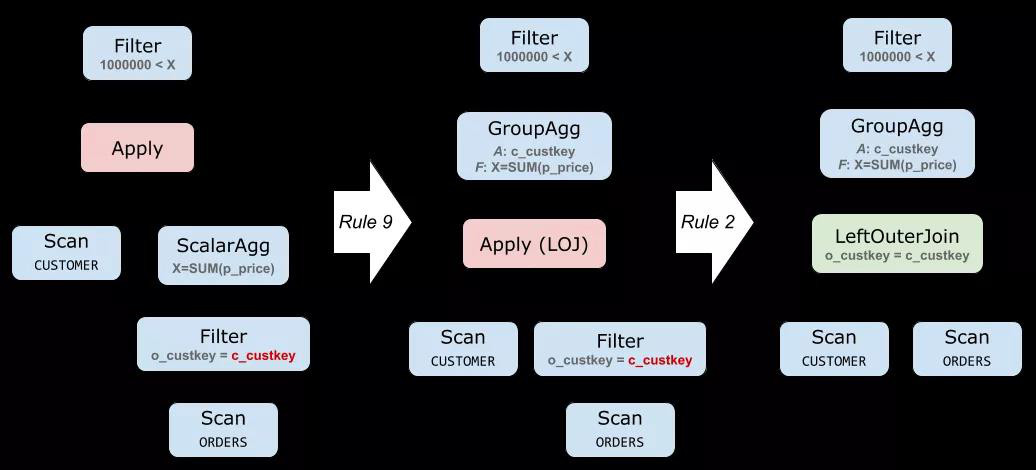
規則 (9) 在下推 Apply 的同時,還將 ScalarAgg 變成了 GroupAgg,其中,分組列就是 R 的 key,在這里也就是 CUSTOMER 的主鍵 c_custkey。
“
如果 R 沒有主鍵或唯一鍵,理論上,我們可以在 Scan 時生成一個。
為什么變換前后是等價的呢?變換前,我們是給每個 R 的行做了一次 ScalarAgg 聚合計算,然后再把聚合的結果合并起來;變換后,我們先是將所有要聚合的數據準備好(這被稱為 augment),然后使用 GroupAgg 一次性地做完所有聚合。
這也解釋了為什么我們要用 ALOJALOJ 而不是原本的 A×A× :原來的 ScalarAgg 上,即使輸入是空集,也會輸出一個 NULL。如果我們這里用 ALOJALOJ,恰好也會得到一樣的行為(*);反之,如果用 A×A× 就有問題了——沒有對應 ORDERS 的客戶在結果中消失了!
規則 (8) 處理的是 GroupAgg,道理也是一樣的,只不過原來的分組列也要留著。
ScalarAgg 轉換中的細節*
細心的讀者可能注意到,規則 (9) 右邊產生的聚合函數是 F′F′,多了一個單引號,這暗示它和原來的聚合函數 FF 可能是有些不同的。那什么情況下會不同呢?這個話題比較深入了,不感興趣的同學可以跳過。
首先我們思考下,GroupAgg 以及 ALOJALOJ 的行為真的和變換前一模一樣嗎?其實不然。舉個反例:
SELECT c_custkey, ( SELECT COUNT(*) FROM ORDERS WHERE o_custkey = c_custkey ) AS count_orders FROM CUSTOMER
設想一下:客戶 Eric 沒有任何訂單,那么這個查詢應當返回一個 ['Eric', 0] 的行。但是,當我們應用了規則 (9) 做變換之后,卻得到了一個 ['Eric', 1] 的值,結果出錯了!
為何會這樣呢?變換之后,我們是先用 LeftOuterJoin 準備好中間數據(augment),然后用 GroupAgg 做聚合。LeftOuterJoin 為客戶 Eric 生成了一個 ['Eric', NULL, NULL, ...] 的行;之后的 GroupAgg 中,聚合函數 COUNT(*) 認為 Eric 這個分組有 1 行數據,所以輸出了 ['Eric', 1]。
下面是個更復雜的例子,也有類似的問題:
SELECT c_custkey FROM CUSTOMER WHERE 200000 < ( SELECT MAX(IF_NULL(o_totalprice, 42)) -- o_totalprice may be NULL FROM ORDERS WHERE o_custkey = c_custkey )
作為總結,問題的根源在于:F(?)≠F({NULL})F(?)≠F({NULL}),這樣的聚合函數 FF 都有這個問題。
變換后的 GroupAgg 無法區分它看到的 NULL 數據到底是 OuterJoin 產生的,還是原本就存在的,有時候,這兩種情形在變換前的 ScalarAgg 中會產生不同的結果。
幸運的是,SQL 標準中定義的聚合函數 F(col)F(col) 都是 OK 的——它們都滿足 F(?)=F({NULL})F(?)=F({NULL}),我們只要對 FF 稍加變換就能解決這個問題。
對于例子一,將 COUNT(*) 替換成一個對非空列(例如主鍵)的 Count 即可,例如:COUNT(o_orderkey);
對于例子二,需要把 MIN(IF_NULL(o_totalprice, 42)) 分成兩步來做:定義中間變量X,先用 Project 計算 X = IF_NULL(o_totalprice, 42),再對聚合函數 MIN(X) 進行去關聯化即可。
最后一組優化規則用來處理帶有 Union(對應 UNION ALL)、Subtract(對應 EXCEPT ALL) 和 Inner Join 算子的子查詢。再強調一遍,我們的指導思想是:盡可能把 Apply 往下推、把 Apply 下面的算子向上提。
下面的等式中,×× 表示 Cross Join,?R.key?R.key 表示按照 RR 的 Key 做自然連接:r°e1°e2r°e1°e2 。和之前一樣,我們假設 RR 存在主鍵或唯一鍵,如果沒有也可以在 Scan 的時候加上一個。
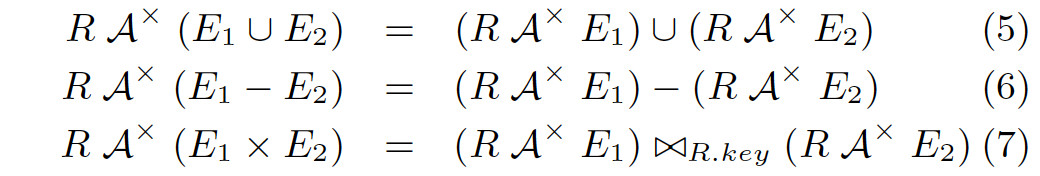
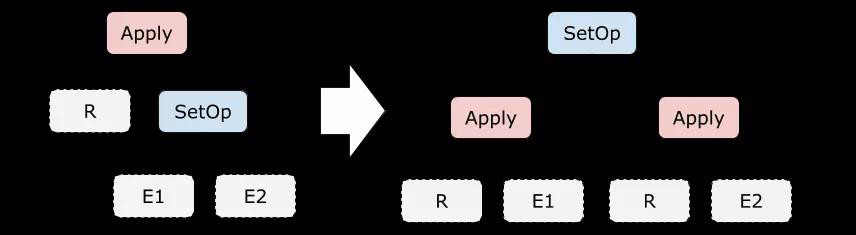
注意到,這些規則與之前我們見過的規則有個顯著的不同:等式右邊 RR 出現了兩次。這樣一來,要么我們把這顆子樹拷貝一份,要么做成一個 DAG 的執行計劃,總之會麻煩許多。
事實上,這一組規則很少能派上用場。在 [2] 中提到,在 TPC-H 的 Schema 下甚至很難寫出一個帶有 Union All 的、有意義的子查詢。
有幾個我認為比較重要的點,用 FAQ 的形式列在下面。
? 是否任意的關聯子查詢都可以被去關聯化?
可以說是這樣的,在加上少量限定之后,理論上可以證明:任意的關聯子查詢都可以被去關聯化。
證明方法在 [1]、[3] 中都有提及。以 [1] 中為例,思路大致是:
對于任意的查詢關系樹,首先將關聯子查詢從表達式中提取出來,用 Apply 算子表示;
一步步去掉其中非基本關系算子,首先,通過等價變換去掉 Union 和 Subtract;
進一步縮小算子集合,去掉 OuterJoin、ALOJALOJ、A?A?、A?A?;
最后,去掉所有的 A×A×,剩下的關系樹僅包含基本的一些關系算子,即完成了去關聯化。
另一方面,現實世界中用戶使用的子查詢大多是比較簡單的,本文中描述的這些規則可能已經覆蓋到 99% 的場景。雖然理論上任意子查詢都可以處理,但是實際上,沒有任何一個已知的 DBMS 實現了所有這些變換規則。
? HyPer 和 SQL Server 的做法有什么異同?
HyPer 的理論覆蓋了更多的去關聯化場景。例如各種 Join 等算子,[3] 中都給出了相應的等價變換規則(作為例子,下圖是對 Outer Join 的變換)。而在 [1] 中僅僅是證明了這些情況都可以被規約到可處理的情形(實際上嘛,可想而知,一定是沒有處理的)。
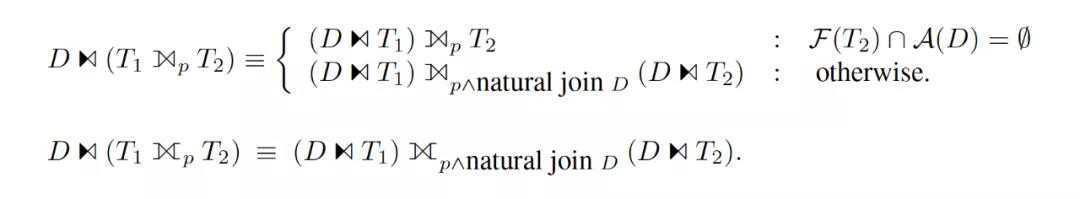
另一個細節是,HyPer 中還存在這樣一條規則:
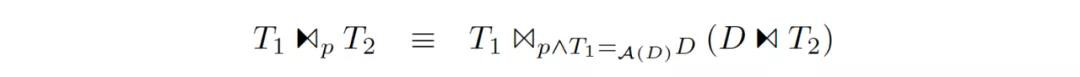
其中,D=ΠF(T2)∩A(T1)(T1)D=ΠF(T2)∩A(T1)(T1),表示對 T1T1 的 Distinct Project 結果(所謂的 _Magic Set_)。直接看等式比較晦澀,看下面的例子就容易理解了:

圖中,在做 Apply 之前,先拿到需要 Apply 的列的 Distinct 值集合,拿這些值做 Apply,之后再用普通的 Join 把 Apply 的結果連接上去。
這樣做的好處是:如果被 Apply 的數據存在大量重復,則 Distinct Project 之后需要 Apply 的行數大大減少。這樣一來,即使之后 Apply 沒有被優化掉,迭代執行的代價也會減小不少。
到此,關于“如何掌握SQL子查詢優化”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





